















































软件

产品


点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
作者丨吃猫的鱼python @CSDN
编辑丨3D视觉开发者社区
目
录
content
一.项目介绍前言
二.识别检测方法
三.完整代码及效果展示
一、项目介绍前言
人脸识别作为一种生物特征识别技术,具有非侵扰性、非接触性、友好性和便捷性等优点。人脸识别通用的流程主要包括人脸检测、人脸裁剪、人脸校正、特征提取和人脸识别。人脸检测是从获取的图像中去除干扰,提取人脸信息,获取人脸图像位置,检测的成功率主要受图像质量,光线强弱和遮挡等因素影响。下图是整个人脸检测过程。
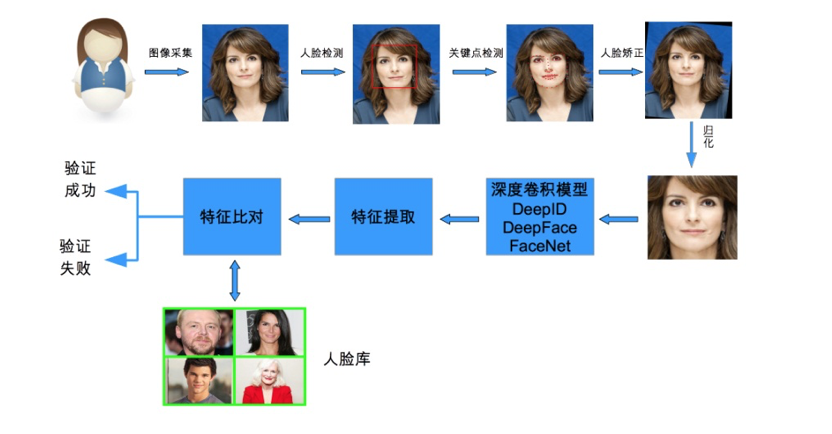
二、识别检测方法
传统识别方法
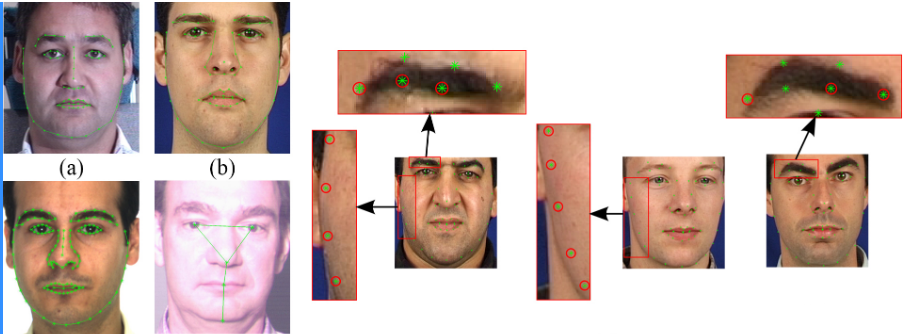
(1)基于点云数据的人脸识别
(2)基于面部特征的3D人脸识别
深度学习识别方法
(1)基于深度图的人脸识别
(2)基于RGB-3DMM的人脸识别
(3)基于RGB-D的人脸识别
🌙本文方法
关键点定位概述
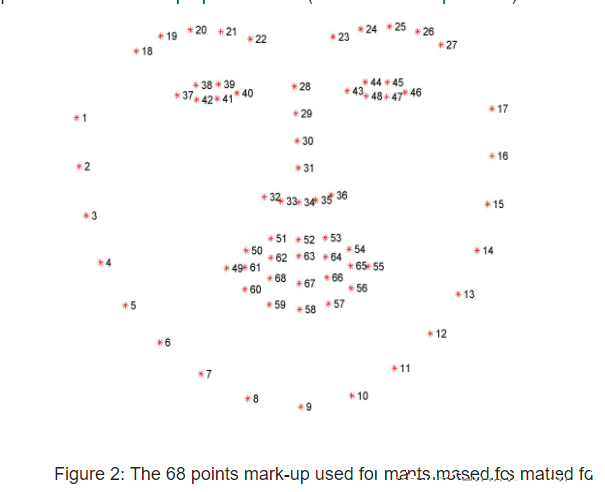
一般人脸中有5个关键点,其中包括眼睛两个,鼻子一个,嘴角两个。还可以细致的分为68个关键点,这样的话会概括的比较全面,我们本次研究就是68个关键点定位。
上图就是我们定位人脸的68个关键点,其中他的顺序是要严格的进行排序的。从1到68点的顺序不能错误。
🌙项目解析
使用机器学习框架dlib做本次的项目。首先我们要指定参数时,要把dlib中的68关键点人脸定位找到。设置出来的68关键点人脸定位找到。并且设置出来。
from collections import OrderedDictimport numpy as npimport argparseimport dlibimport cv2首先我们导入工具包。其中dlib库是通过这个网址http://dlib.net/files/进行下载的。然后我们导入参数。
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--shape-predictor", required=True,
help="path to facial landmark predictor")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())这里我们要设置参数,
--shape-predictor shape_predictor_68_face_landmarks.dat --image images/lanqiudui.jpg。如果一张图像里面有多个人脸,那么我们分不同部分进行检测,裁剪出来所对应的ROI区域。我们的整体思路就是先检测人脸所在的一个区域位置,然后检测鼻子相对于人脸框所在的一个位置,比如说人的左眼睛在0.2w,0.2h的人脸框处。
FACIAL_LANDMARKS_68_IDXS = OrderedDict([
("mouth", (48, 68)),
("right_eyebrow", (17, 22)),
("left_eyebrow", (22, 27)),
("right_eye", (36, 42)),
("left_eye", (42, 48)),
("nose", (27, 36)),
("jaw", (0, 17))
])这个是68个关键点定位的各个部位相对于人脸框的所在位置。分别对应着嘴,左眼、右眼、左眼眉、右眼眉、鼻子、下巴。
FACIAL_LANDMARKS_5_IDXS = OrderedDict([
("right_eye", (2, 3)),
("left_eye", (0, 1)),
("nose", (4))
])如果是5点定位,那么就需要定位左眼、右眼、鼻子。0、1、2、3、4分别表示对应的5个点。
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(args["shape_predictor"])加载人脸检测与关键点定位。加载出来。其中detector默认的人脸检测器。然后通过传入参数返回人脸检测矩形框4点坐标。其中predictor以图像的某块区域为输入,输出一系列的点(point location)以表示此图像region里object的姿势pose。返回训练好的人脸68特征点检测器。
image = cv2.imread(args["image"])
(h, w) = image.shape[:2]
width=500
r = width / float(w)
dim = (width, int(h * r))
image = cv2.resize(image, dim, interpolation=cv2.INTER_AREA)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)这里我们把数据读了进来,然后进行需处理,提取h和w,其中我们自己设定图像的w为500,然后按照比例同比例设置h。然后进行了resize操作,最后转化为灰度图。
rects = detector(gray, 1)这里调用了detector的人脸框检测器,要使用灰度图进行检测,这个1是重采样个数。这里面返回的是人脸检测矩形框4点坐标。然后对检测框进行遍历
for (i, rect) in enumerate(rects):
# 对人脸框进行关键点定位
# 转换成ndarray
shape = predictor(gray, rect)
shape = shape_to_np(shape)这里面返回68个关键点定位。shape_to_np这个函数如下。
def shape_to_np(shape, dtype="int"): # 创建68*2 coords = np.zeros((shape.num_parts, 2), dtype=dtype) # 遍历每一个关键点 # 得到坐标 for i in range(0, shape.num_parts): coords[i] = (shape.part(i).x, shape.part(i).y) return coords这里shape_to_np函数的作用就是得到关键点定位的坐标。
for (name, (i, j)) in FACIAL_LANDMARKS_68_IDXS.items(): clone = image.copy() cv2.putText(clone, name, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2) # 根据位置画点 for (x, y) in shape[i:j]: cv2.circle(clone, (x, y), 3, (0, 0, 255), -1) # 提取ROI区域 (x, y, w, h) = cv2.boundingRect(np.array([shape[i:j]])) roi = image[y:y + h, x:x + w] (h, w) = roi.shape[:2] width=250 r = width / float(w) dim = (width, int(h * r)) roi = cv2.resize(roi, dim, interpolation=cv2.INTER_AREA) # 显示每一部分 cv2.imshow("ROI", roi) cv2.imshow("Image", clone) cv2.waitKey(0)这里字典FACIAL_LANDMARKS_68_IDXS.items()是同时提取字典中的key和value数值。然后遍历出来这几个区域,并且进行显示具体是那个区域,并且将这个区域画圆。随后提取roi区域并且进行显示。后面部分就是同比例显示w和h。然后展示出来。
output = visualize_facial_landmarks(image, shape)
cv2.imshow("Image", output)
cv2.waitKey(0)最后展示所有区域。
其中visualize_facial_landmarks函数就是:
def visualize_facial_landmarks(image, shape, colors=None, alpha=0.75):
# 创建两个copy
# overlay and one for the final output image
overlay = image.copy()
output = image.copy()
# 设置一些颜色区域
if colors is None:
colors = [(19, 199, 109), (79, 76, 240), (230, 159, 23),
(168, 100, 168), (158, 163, 32),
(163, 38, 32), (180, 42, 220)]
# 遍历每一个区域
for (i, name) in enumerate(FACIAL_LANDMARKS_68_IDXS.keys()):
# 得到每一个点的坐标
(j, k) = FACIAL_LANDMARKS_68_IDXS[name]
pts = shape[j:k]
# 检查位置
if name == "jaw":
# 用线条连起来
for l in range(1, len(pts)):
ptA = tuple(pts[l - 1])
ptB = tuple(pts[l])
cv2.line(overlay, ptA, ptB, colors[i], 2)
# 计算凸包
else:
hull = cv2.convexHull(pts)
cv2.drawContours(overlay, [hull], -1, colors[i], -1)
# 叠加在原图上,可以指定比例
cv2.addWeighted(overlay, alpha, output, 1 - alpha, 0, output)
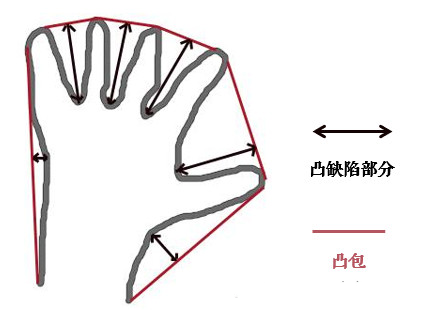
return output这个函数是计算cv2.convexHull凸包的,也就是下图这个意思。
这个函数cv2.addWeighted是做图像叠加的。
src1, src2:需要融合叠加的两副图像,要求大小和通道数相等
alpha:src1 的权重
beta:src2 的权重
gamma:gamma 修正系数,不需要修正设置为 0
dst:可选参数,输出结果保存的变量,默认值为 None
dtype:可选参数,输出图像数组的深度,即图像单个像素值的位数(如 RGB 用三个字节表示,则为 24 位),选默认值 None 表示与源图像保持一致。
dst = src1 × alpha + src2 × beta + gamma;上面的式子理解为,结果图像 = 图像 1× 系数 1+图像 2× 系数 2+亮度调节量。
三、完整代码及效果展示
from collections import OrderedDictimport numpy as npimport argparseimport dlibimport cv2ap = argparse.ArgumentParser()ap.add_argument("-p", "--shape-predictor", required=True, help="path to facial landmark predictor")ap.add_argument("-i", "--image", required=True, help="path to input image")args = vars(ap.parse_args())FACIAL_LANDMARKS_68_IDXS = OrderedDict([ ("mouth", (48, 68)), ("right_eyebrow", (17, 22)), ("left_eyebrow", (22, 27)), ("right_eye", (36, 42)), ("left_eye", (42, 48)), ("nose", (27, 36)), ("jaw", (0, 17))])FACIAL_LANDMARKS_5_IDXS = OrderedDict([ ("right_eye", (2, 3)), ("left_eye", (0, 1)), ("nose", (4))])def shape_to_np(shape, dtype="int"): # 创建68*2 coords = np.zeros((shape.num_parts, 2), dtype=dtype) # 遍历每一个关键点 # 得到坐标 for i in range(0, shape.num_parts): coords[i] = (shape.part(i).x, shape.part(i).y) return coordsdef visualize_facial_landmarks(image, shape, colors=None, alpha=0.75): # 创建两个copy # overlay and one for the final output image overlay = image.copy() output = image.copy() # 设置一些颜色区域 if colors is None: colors = [(19, 199, 109), (79, 76, 240), (230, 159, 23), (168, 100, 168), (158, 163, 32), (163, 38, 32), (180, 42, 220)] # 遍历每一个区域 for (i, name) in enumerate(FACIAL_LANDMARKS_68_IDXS.keys()): # 得到每一个点的坐标 (j, k) = FACIAL_LANDMARKS_68_IDXS[name] pts = shape[j:k] # 检查位置 if name == "jaw": # 用线条连起来 for l in range(1, len(pts)): ptA = tuple(pts[l - 1]) ptB = tuple(pts[l]) cv2.line(overlay, ptA, ptB, colors[i], 2) # 计算凸包 else: hull = cv2.convexHull(pts) cv2.drawContours(overlay, [hull], -1, colors[i], -1) # 叠加在原图上,可以指定比例 cv2.addWeighted(overlay, alpha, output, 1 - alpha, 0, output) return output# 加载人脸检测与关键点定位detector = dlib.get_frontal_face_detector()predictor = dlib.shape_predictor(args["shape_predictor"])# 读取输入数据,预处理image = cv2.imread(args["image"])(h, w) = image.shape[:2]width=500r = width / float(w)dim = (width, int(h * r))image = cv2.resize(image, dim, interpolation=cv2.INTER_AREA)gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)# 人脸检测rects = detector(gray, 1)# 遍历检测到的框for (i, rect) in enumerate(rects): # 对人脸框进行关键点定位 # 转换成ndarray shape = predictor(gray, rect) shape = shape_to_np(shape) # 遍历每一个部分 for (name, (i, j)) in FACIAL_LANDMARKS_68_IDXS.items(): clone = image.copy() cv2.putText(clone, name, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2) # 根据位置画点 for (x, y) in shape[i:j]: cv2.circle(clone, (x, y), 3, (0, 0, 255), -1) # 提取ROI区域 (x, y, w, h) = cv2.boundingRect(np.array([shape[i:j]])) roi = image[y:y + h, x:x + w] (h, w) = roi.shape[:2] width=250 r = width / float(w) dim = (width, int(h * r)) roi = cv2.resize(roi, dim, interpolation=cv2.INTER_AREA) # 显示每一部分 cv2.imshow("ROI", roi) cv2.imshow("Image", clone) cv2.waitKey(0) # 展示所有区域 output = visualize_facial_landmarks(image, shape) cv2.imshow("Image", output) cv2.waitKey(0)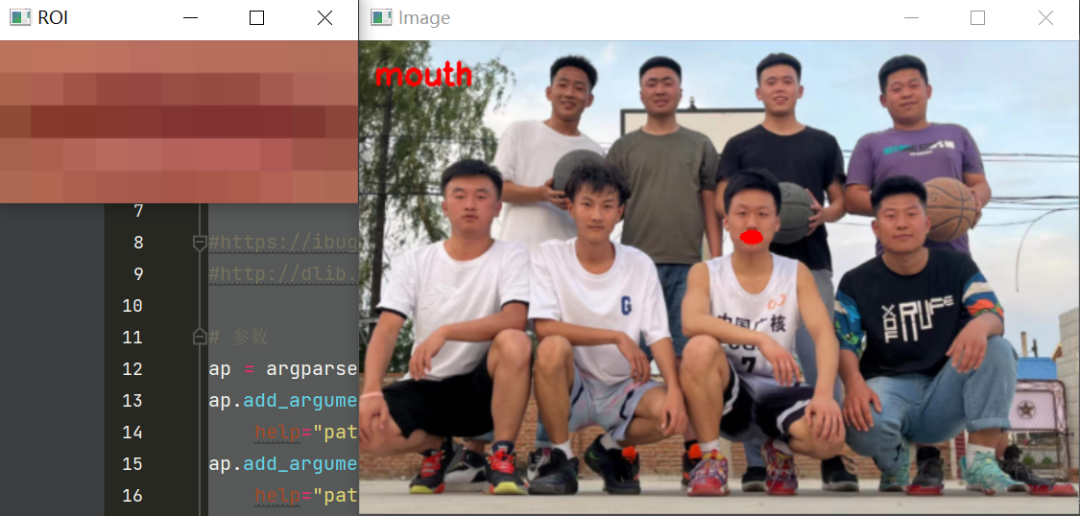

最终将7个人的人脸都依次的检测到了。并且根据关键点定位到了。
本文仅做学术分享,如有侵权,请联系删文。
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群 欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















