















































软件

产品


答:C++的引用,不能“换绑”,是“终身绑定”的!而C的指针是可以“换绑”的,利用C的指针可以实现诸如“链表”之类的数据结构!
“引用” 在概念上与“真正的数组” 很类似,视为一种常量的“绑定关系”,定义之后,“绑定关系”就不能变了!
有些人仅仅是偶尔使用“对象”和“引用”,并不是真正的OOP;他们认为“引用”是更方便的指针,更不容易混淆;他们认为“对象”就是在定义中有一些“方法”的结构体而已!
⭐ “继承”和“模板”的思想,才是OOP的核心!!!真正的OOP纯粹主义者,会将“对象”视为一个活生生的实体,它能够自我维护,能够与外界进行“交流”!
⭐ 从底层机制上来看,“结构体”和“类”是以同样的模式存储在内存单元之中,可以说是完全的相同!只不过在C++中,结构体是可以定义“构造函数”、“析构函数”和“方法”的;结构体和类的唯一不同之处在于:“类”的默认访问修饰符是“private”,“结构体”的默认访问修饰符是“public”。
⭐ 静态方法:“类”的方法前加“static”限定!这样的方法在调用时,不会传入“this”指针,不用指明“对象(结构体)”!因为:该方法为“类”服务!即使“对象”不同,行为也是一样的!
⭐ 非静态方法:不用“static”限定的方法!这样的方法在调用时,会传入“this”指针,会隐式知名“对象(结构体)”!因为:该方法是为“对象”服务的!根据对象的不同,可能会产生不同的行为!!!
对“作业”的功能性测试是考察“需求”实现的重要方法!为了完美而稳妥地提交你的实现方案,必须在是实现方案中集成“测试”工具!
测试用例:就是对“测试任务”的描述,包括完整的测试目标、测试环境、测试步骤、输入数据、预期结果,测试脚本等,输出pdf文档!
测试程序三步走:
(输入数据)——(预期结果)——(预期与实际结果对比)
paradigm 作业类型:
① 泛化的语言、图形:更高的抽象层次上,表述“实现方法”、“运行机理”;
② 具体化语言的:程序设计 + 测试用例;涵盖8-bit(MCS-51、PIC18、STM8)、PIC-24、ARM-32、x86-64机器的高级语言、汇编语言和微架构,在实际机器中体会“概念”。
③ 问题集:口头回答一些问题,做一些小小的计算题!
本质上:#define 就是个 “查找替换器” ;
#define label sth123abc
.c文件中查找到 label 字样,并替换为“sth123abc”
preprocessor是很傻的,替换过程中,不会检查语言语法的!
#define KWidth 480
#deifne KHeight 80
#define KPerimeter 2*(KWidth + KHeight)
带参数的#define
#define MAX(a,b) ((a>b) ? (a) : (b))
注意:“(” 和 “MAX" 之间不能有“空格”哦!此时preprocessor会意识到这是一个带参数的#define!!!
通过前面汇编代码的学习,我们已经知道了调用函数的时空开销是很大的,它需要调用和返回,需要维护”活动记录“:
定义1个函数会生成相应的“汇编指令”,会汇编成“机器代码”;
声明1个函数不会生成任何的“汇编指令”以及“机器代码”;
⭐ .c 中定义全局变量、全局函数以及类方法,这里定义了函数的实现!是会生成汇编代码的,会被编译器编译成.o文件!
⭐ .h 中除了定义共享的“全局变量”,不能够申请任何的存储空间!.h文件只是声明函数而已,供编译器去进行语法检查,不会生成任何的汇编代码!
.h 中声明函数原型的真正目的:让caller和callee在活动记录(saved PC、入参)上半部分达成一致!原型其实只涉及参数!
比如你在写数码的segment码时候,
const char code ca_table[]={
0xc0,0xf9,0xa4,0xb0,0x99,0x92,0x82,0xf8,0x80,0x90,0x88,0x83,0xc6,0xa1,0x86,0x8e};
const char code cc_table[]={
0x3f,0x06,0x5b,0x4f, 0x66,0x6d,0x7d,0x07,0x7f,0x6f,0x77,0x7c,0x39,0x5e,0x79,0x71};
上述数组,要放在.c文件中,因为.h中不让你申请任何的存储空间!
如果这个 xxx.h 被A.c 文件 #include了,又被B.c 文件 #include了,那么在总的大文件里面,就会有两段“ca_table” 数组啦!!!啊,哪个才是想要的呢???
gcc -E xxx.c
汇编:指的是将“汇编代码” → 转换成 → “机器代码”的过程
编译:指的是将“源代码” → 转换成 → “可执行代码”的过程
编译包括“汇编”这一步:源文件 (预处理器 )清掉#define的源文件()汇编文件(汇编)可重定位目标文件 可执行文件!
比如使用malloc(),没有include <stdlib.h>
源程序 → 可执行文件经历了三个大步骤:
① 源程序 → 预处理器 → 完成 “替换”,生成 翻译 单元(translation unit)
② 翻译单元 → 编译 → .o(可重定位目标文件)
③ .o → 链接 → 可执行文件(.out、.exe)
#include <stdio.h> // 注释掉这行,报1警告,报0错误
#include <stdlib.h> // 注释掉这行,报3个警告,报0错误
#include <assert.h> // 注释掉这行,报1警告,报1错误
int main(int argc, char **argv)
{
void *memory == malloc(400);
assert(memory != NULL);
printf("Hello\r\n");
free(memory);
return 0;
}
在“预处理”阶段:,翻译单元中将不会有printf()的声明!当编译器去检查printf()是否被正确调用的时候,会发现并没有printf()这个函数的声明!这时候,很多编译器会说,“哦!你在做什么啊?我怎么没见过这个函数呢?我找不到它的原型啊!我不认识它!所以,我要报错了啊!”
在“编译”阶段:但是gcc不会报错!gcc会在编译的时候分析源程序,看看哪部分像是函数调用,根据这个函数调用,去推测函数原型,当gcc看到printf(“Hello\r\n”)这里有1个字符串作为传入参数,它会发出1个警告,说“俺没有找到printf()的函数原型”,但是它不会停下来,会继续生成.o文件!如果后面还有printf(),依照前面的函数原型推测,传参只能是1个字符串!推测出来的函数原型与实际的printf()是有区别的!所以,编译是通过的!
然后进入“链接”阶段!.h文件只是包含一些数据结构的定义和一些函数原型,它不会产生任何的汇编代码,它的用途只是告诉编译器,可以判定程序上哪些语法是正确的,哪些语法是错误的!使用“链接”命令,会使用编译过程中的警告去寻找去查找“标准库”,而printf()对应的代码,恰好就在标准库中!在链接阶段会被加进来哦!运行时候,不会有任何问题!
在“预处理”阶段:翻译单元中将不会有malloc()和free()的声明!
在“编译”阶段:找不到malloc()和free()的原型,报2个警告,然后会推测函数原型,推测其有1个 int (默认)返回值!void * 和 int 类型不匹配,再报1个警告。
然后进入“链接”阶段!标准库中找到了对应的malloc()和free()函数,将成功生成可执行文件!运行时候,不会有任何问题!
在“预处理”阶段:翻译单元中将不会有assert()的声明!
在“编译”阶段:找不到assert()的原型,报1个警告,然后会推测函数原型,会把assert当作真正的函数哦!我们知道assert实际上是个宏,这里没有进行“宏替换”!
然后进入“链接”阶段!虽然标准库有assert() 的声明,但是,没有进行宏替换!完蛋,报1个错错了吧!
ANSI 提供的诸如C89、C99、C11标准里面,带有的标准函数库!
比如<stdio.h>,<stdlib.h>,<string.h>,<assert.h>等!
预测下列代码的行为会产生什么后果?
int main()
{
int num = 65;
int length = strlen((char *)&num, num);
printf("Length = %d\r\n", length);
return 0;
}
⭐ 没写“头文件”,在预处理阶段,没有加入<string.h>;进入编译阶段,找不到strlen的函数原型,将进行推测 int strlen(char *, int) 成这个狗模样,很明显跟标准函数库中的strlen()原型不一样!按常理来说,进入链接阶段后,应该就报错了啊!但是实际情况不是这样的,这段代码能够完美地被执行,并且不报错!为啥捏?请看下面的分析:
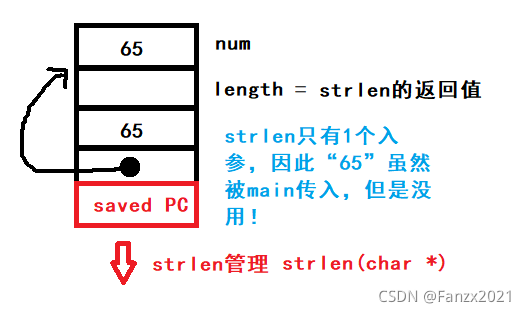
这就是函数入参从右向左读的好处!这个错误的代码竟然能不报错地运行!俺也是醉了!C语言啊,让人既赞叹,又有点“后怕”!
那这个main运行完后,会printf出来什么东西呢?strlen遇“\0”也就是“0”而停止计数!
⭐ 改成一个也不出警告的版本,声明原型!!!越错越离谱了!哈哈哈!!!
int strlen(char *, int len);
int main()
{
int num = 65;
int length = strlen((char *)&num, num);
printf("Length = %d\r\n", length);
return 0;
}
其实这种方法也有人常用,我们不去include标准库,因为标准库中有太多的函数了!会很大!占用比较大的空间,可以仅仅声明函数库中的函数原型!这样编译器就既不会报错,又不会出警告;而链接器会自动去标准库中寻找函数的定义 !perfect!!!
int memcmp(void *v1);
// int memcmp(void *v1, void *v2, int size);
int main()
{
int n = 17;
int m = memcmp(&n);
}
这次彻底完蛋啦!编译能够通过,既没有错误,又没有警告,但是运行的时候,极有可能崩溃掉!为什么捏?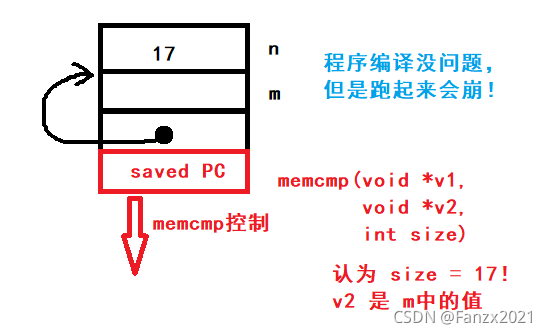
C语言是一种弱类型的系统,它定义了裸指针void *,并支持使用void *进行泛型编程!所以,很容易编译成功,但是新手编写的程序,运行起来很容易崩溃。C语言对硬件操作的自由度很高!是专家级的优秀语言,需要掌握“内存”的编程模型,了解基本的“微架构”和“指令集架构”,对新手并不友好。
C++编译器就像个很挑剔的婚礼筹划者,必须要一切都准备好了才能够开始;C编译器就很随意,只要能用,咱们就开始,出了问题那就是你们自个负责啊!
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















