















































软件

产品


MUTANT: A Training Paradigm for Out-of-Distribution Generalization in Visual Question Answering
突变体:视觉问答中外分布泛化的训练范式
起因:作者认为先前的处理语言偏见的任务,如LMH (Clark et al., 2019)试图消除问题-答案对之间的所有偏见,惩罚可以回答不看图像;我们认为这样做会适得其反。与抗生素类似,抗生素的设计目的是清除病原体细菌,但最终也会清除有用的肠道微生物群。
本文提出的方法和CSS有相似之处,区别在于:CSS仅仅对于反事实的处理比较笼统,只是在某种意义上,扩大了数据集。本文提出的突变方法,突变后例子的答案与原来的答案属于同一种类型。这种方法在较大程度上,解决了上面的清除有用偏见的情况。(也就是说,问题虽然具有先验性的偏见,但是仅根据问题的得到的答案未必都是错的。)这其中有两点值得注意,一方面,使预测答案聚焦于对应的类型,不会产生问颜色而回答yes、no的情况。另一方面,和CSS不同的是,这种突变不显著改变输入(改变,但是不显著),显著改变的是答案。CSS中指出的是生成反事实的(不相关的区域或单词),而本文中提出的突变方法是对输入进行更细致地微调,例如对问题的关键词进行遮盖,替换和否定,对图像的关键对象进行颜色反转和去除。本质上还是一种数据扩增的方式。
贡献:
1,和传统的分类方法不同,本文使用噪声对比估计的方法预测正确答案。
2,成对一致性的正则化损失函数,缩小真实答案和预测答案的距离。
3,在VQA-cpv2数据集上达到了最新水平,提高了10.57%。updn上增加2.77%
4,最重要的是制定了图像和问题的突变生成机制。
模型较为复杂,先讲解各部分方法答案预测(AP),类型预测(TE),成对一致性(PC),然后再总体说
答案预测(AP):
标准损失函数使用以下交叉熵损失: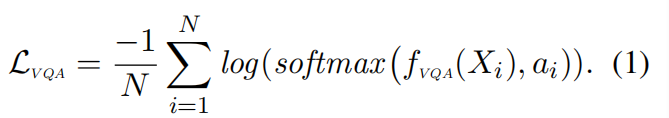
作者认为原来的损失函数对于问答这种分类任务,做决定的时候没有考虑答案的意义。学习的是特征和答案之间的one-hot向量之间的关联。所以作者提出以下噪声对比估计(2010年)的方法作为损失函数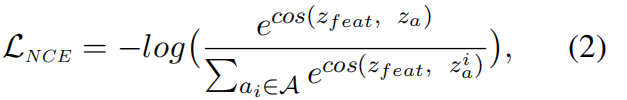
其中zfeat = fproj(z)和za = fproj( glove (a)),A是训练集中可能答案的集合。
注意:这里面相似度指标不是真实答案和预测答案之间,而是输入特征和答案投影之间,以便在回答任务中结合上下文。
类型暴露(TE): 和之前的消除语言偏见的方法不同,模型目标不是消除所有偏见,而是让模型识别问题类型,确定哪些答案对于特定类型是有效的,并不考虑答案再数据集中出现的频率。比如,对于how many问题,答案应该是number,what color问题答案应该是某种颜色。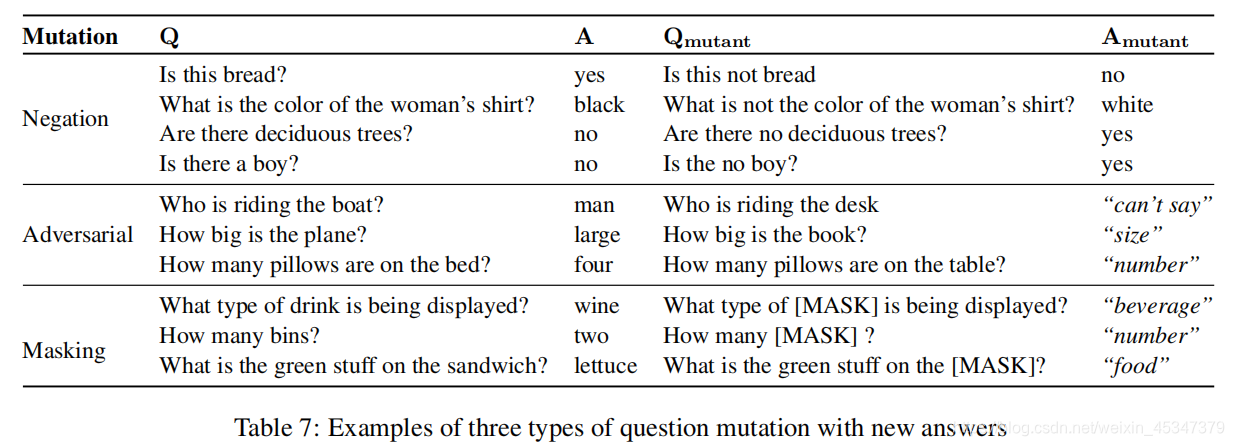
类型暴露模型使用前馈网络来预测问题类型,并在与此类型对应的回答候选人上创建一个二进制掩码。
成对一致性(PC):
用原始样本对和突变样本对共同训练我们的模型,用损失函数确保两个预测答案向量之间的距离接近两个ground-truth答案向量之间的距离。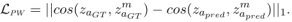
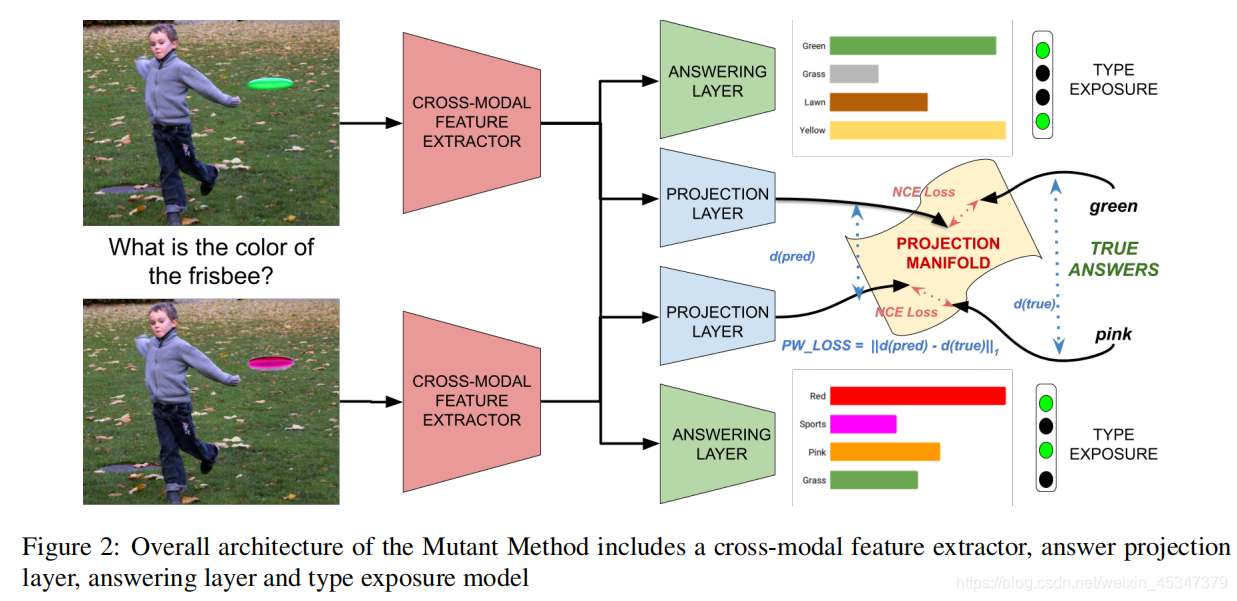
输入包括了基本的跨模态特征和(图像/问题)突变后的跨模态特征,注意在这里使用LXMERT模型,从问题和输入得到跨模态的特征,因为LXMERT模型属于预训练的方式,并且在VQA2.0得到了最新水平。上文中NCE_loss是预测和答案之间的损失函数,用到了两次,一次是原来的,一次是突变的,为了拉近他们之间的距离,使用了PW_loss损失函数。
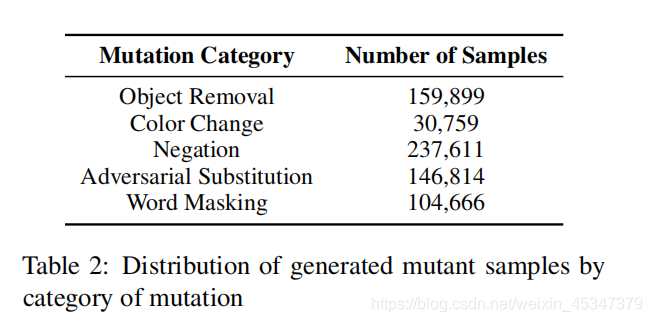
前面的两种对象去除和颜色反转是对图像的突变,否定,对抗词语替换和词语遮盖属于问题的突变。
图像突变产生过程
对象选择:对于每个VQA样本,将创建一个单词W列表,其中包含来自基本事实答案和问题的单词。W中的所有名词都转换为单数形式。从COCO获得对于是非问题、数字问题和关于对象颜色的问题的对象O的列表。从O中过滤出背景对象和人群对象,得到O关键对象OC和非关键对象ONC。如果一个客体词或它的同义词或名词出现在W中,那么它就是一个关键客体。使用这些注释,应用删除操作或颜色反转操作来创建突变图像。
**对象填充:**然后将这张蒙版图像输入到基于 GAN 的图像修复网络。
**颜色反转:**为了使模型更具有一般性,对颜色的改变是对颜色的反转,而不是选取可能的几种颜色,比如香蕉可能是黄,绿,黑,但是如果图像中是蓝色的,也希望模型能够正确识别。
突变的答案产生:
yes/no:如果去除了所有关键实例答案由yes变为no,如果只去除一部分或者实例对象是不关键的,则答案不变。
number:m个实例去除,答案由n改为n-m
color:使用Webcolors将颜色转换为十六进制,并将颜色反向转换,在CSS-21中找到接近这个值的颜色。
问题突变产生过程
否定 加上no,not等否定词
对抗词,对抗词语的选择,创建了一个所有对象词及其同义词的列表,使用 BERT 进行相似度排序,然后对抗关键词选择图像中不存在的最相似的词语。
遮盖,去掉关键对象词,用mask代替。
对于这两种突变,某些时候给不出正确答案,使用广义范畴作为答案。
对于答案的分类,使用K均值聚类和欧式距离度量,手动调整后选择k=50,然后手动注释类别名称。对于部分答案,一些宽泛的类别也无法确定,答案被cant say代替。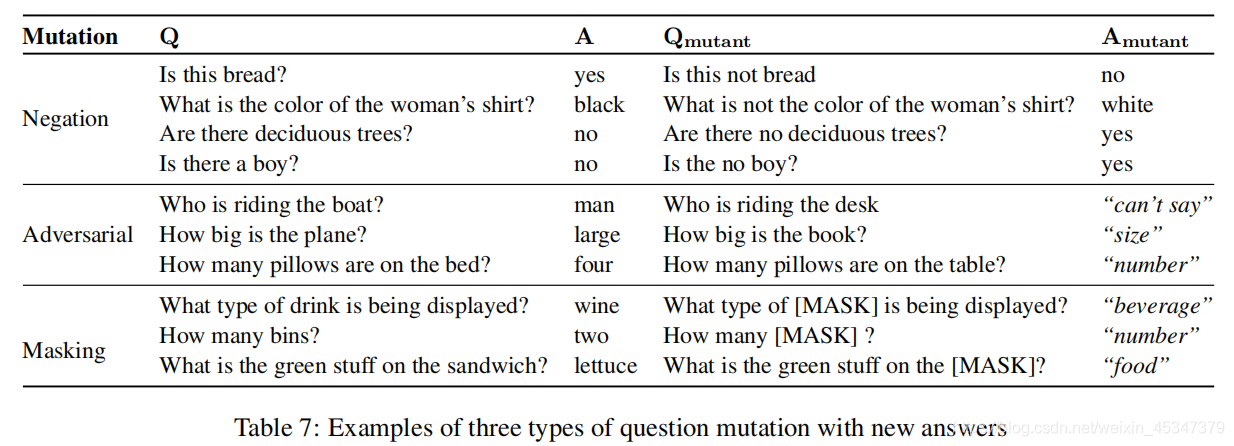
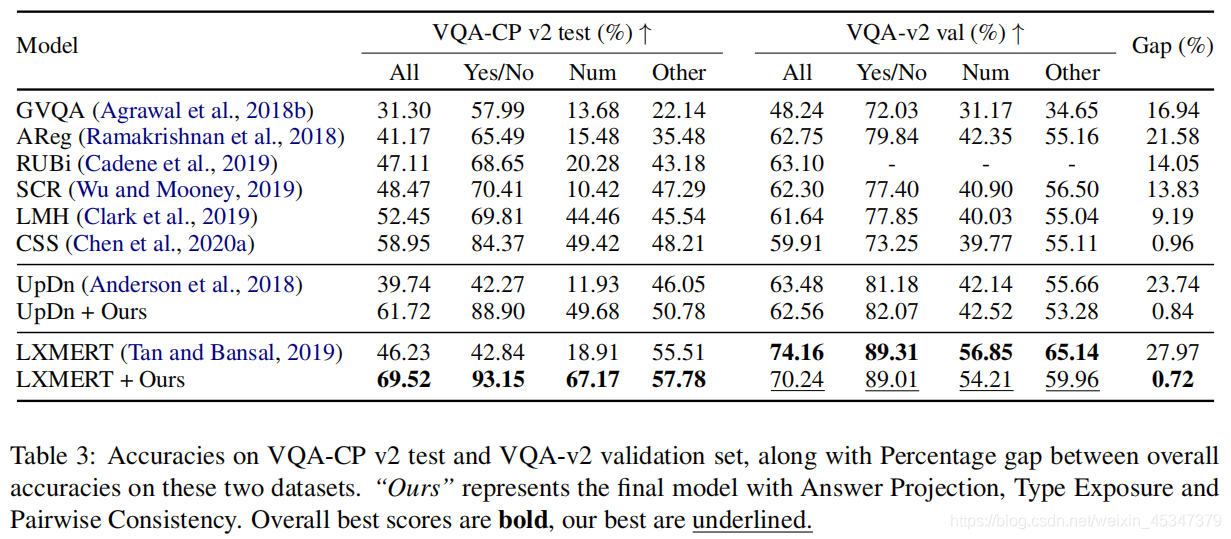
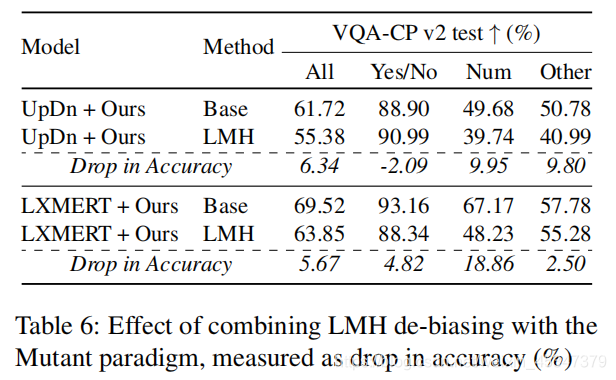
分析了LMH对模型性能的损害
再附几张图帮助理解


免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















