















































软件

产品


取材于2020.11的资料,文档整理于2021.2.7
如果运行abaqus报错如下图:
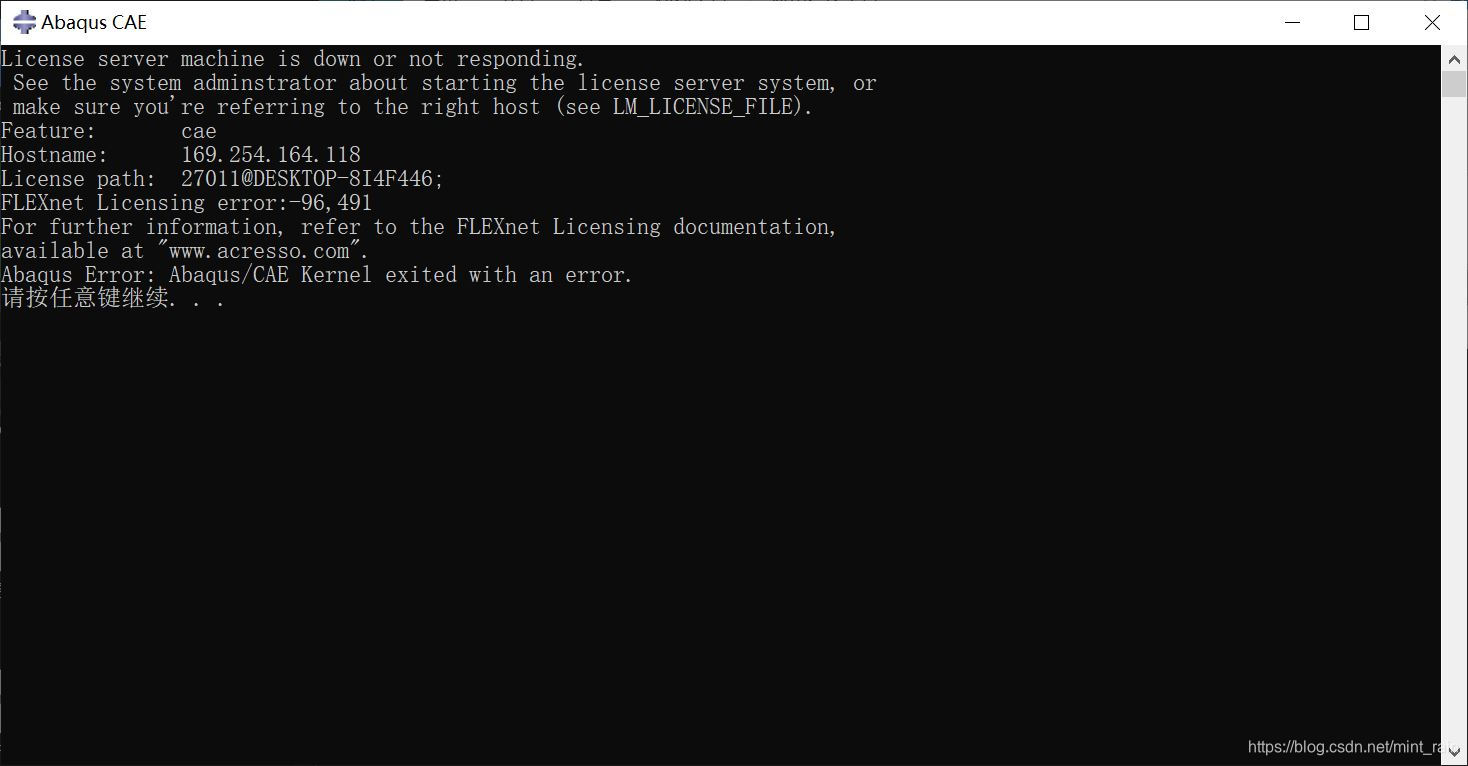
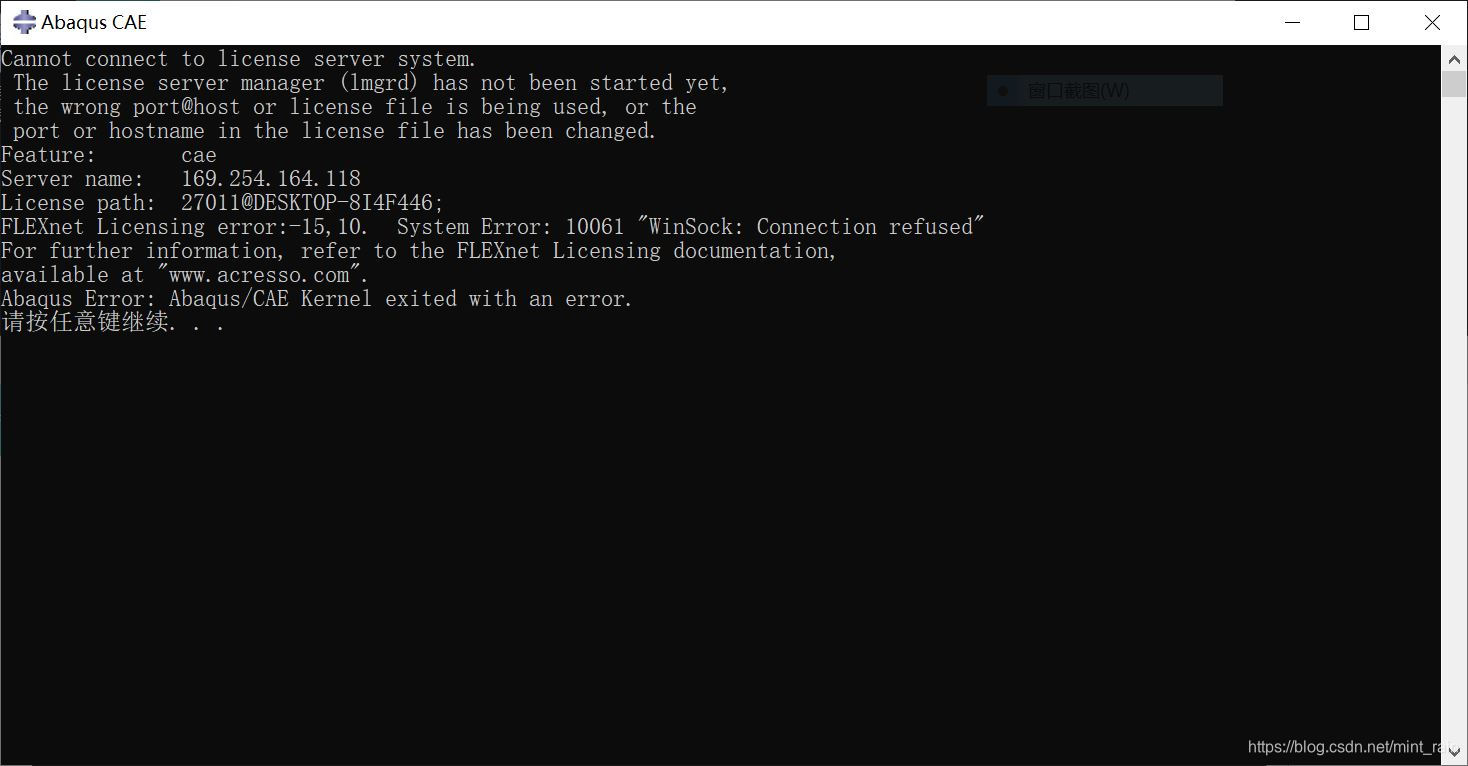
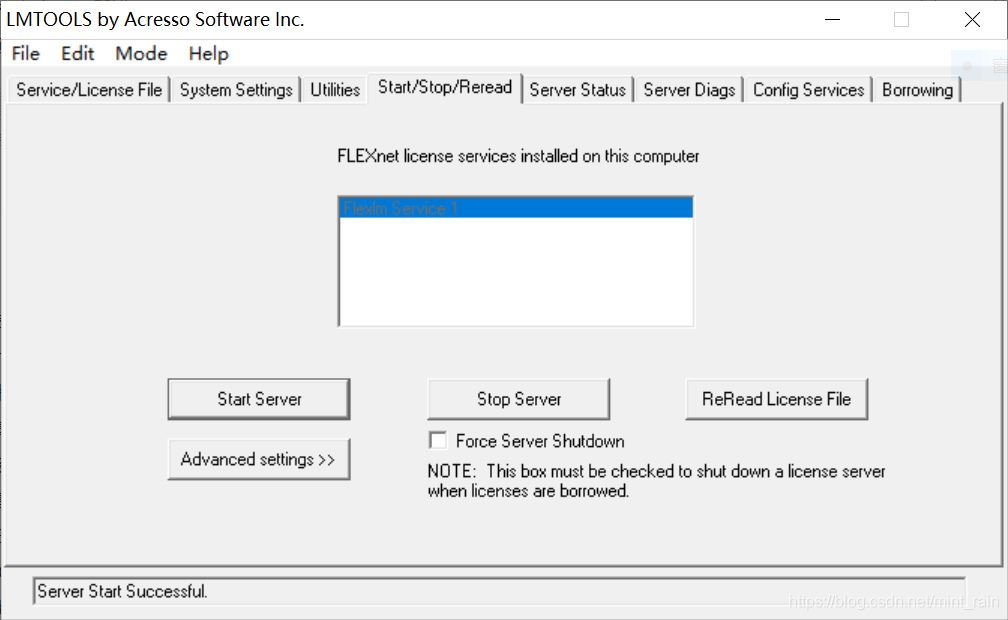
则点击abaqus licensing,选择第四个【Start/Stop/Reread】,点击第一个按钮【Start Server】,下方显示框中显示【Server Start Successful.】,再次打开abaqus ACE即可,如果还是报错就再开一次。
abaqus licensing界面:
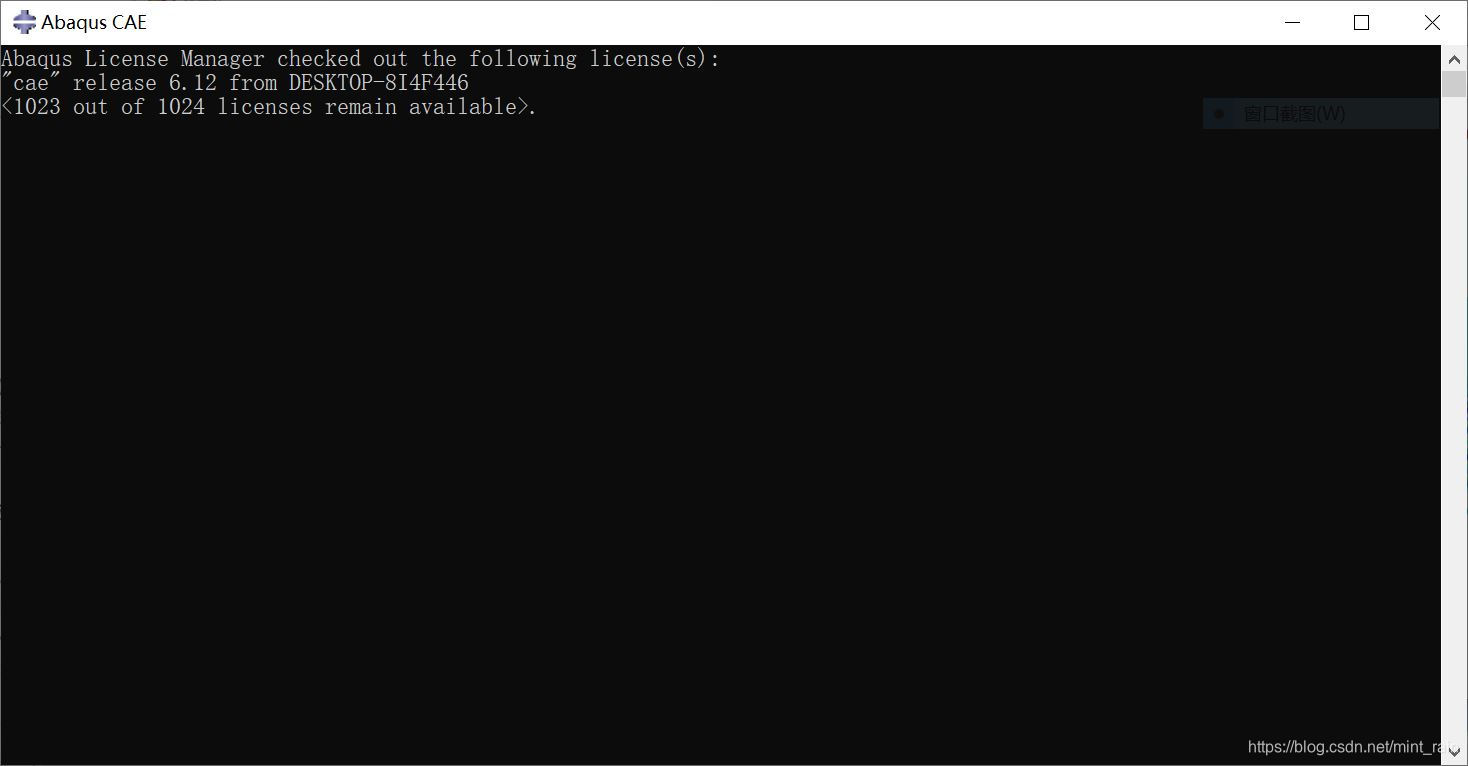
正常打开的abaqus提示框:
注:本文所用的接口函数runabaqus.m、get_history_output.m、odbHistoyOutput.py与这篇博客相同。
一、abaqus中完成有限元建模,得到 模型 文件,进行一次仿真,得到自动生成的.inp文件。
具体建模方法在前两篇博客里已有详细描述。
二、matlab调用abaqus引擎进行仿真
利用matlab调用abaqus引擎获取变载荷的仿真过程变量(例如端点位移量)的原理是,多次调用abaqus进行仿真,每次只仿真分析步长的时间,获取本次仿真中最后一个时刻变量值,再进行下一次仿真。例如仿真时长为 0.4 s 0.4s 0.4s,分析步长为 0.01 s 0.01s 0.01s,则要进行 0.4 / 0.01 = 40 0.4/0.01=40 0.4/0.01=40次仿真。两次仿真之间可以通过修改inp文件修改载荷力,即可实现变载荷力仿真,如正弦载荷。
所以运行一次仿真的时间都比较长,需要根据仿真结果调pid参数的时候可以酌情减少仿真时长阶节约时间,毕竟pid参数好不好前两次超调的一小段就已经能说明很多问题了。
我进行软体手指的受力位移仿真时,报错:
>> finger
Abaqus License Manager checked out the following license(s):
"cae" release 6.12 from DESKTOP-8I4F446
<1022 out of 1024 licenses remain available>.
KeyError: Node finger_8-1.45
File "odbHistoyOutput.py", line 38, in <module>
region =step_n.historyRegions[node_set]
Abaqus Error: cae exited with an error.
错误使用 movefile
未找到匹配的文件。
出错 finger (line 15)
movefile('COOR1.txt', 'N_X.txt');
我修改了odbHistoyOutput.py,增加了提示性输出,发现运行到region =step_n.historyRegions[node_set]一句就不会再往下运行。我猜到是传入的参数node_set即matlab中req的第二个参数有问题,但穷尽想象力尝试到凌晨四点也没能 解决 ,第二天去问师姐,师姐说名称必须大写,我改成大写果然可以了。这个离谱规定让我记忆犹新。
1、runabaqus.m、get_history_output.m、odbHistoyOutput.py必须与运行的.m文件放在同一目录下,否则会报错类似:
>> beam1
未定义函数或变量 'runabaqus'。
出错 beam1 (line 24)
runabaqus(Path,InpFile,cpus); %运行abaqus进行计算
2、未找到匹配文件的报错可能原因有很多,从仿真运行到结果读取,任何一个小环节出问题最后大概率在movefile处报错。
排查思路:
(1)看生成的.odb文件的大小,若没有这个文件或文件过小(正常应该至少10M),就是仿真环节已经出问题了。检查abaqus licensing是否运行,若仿真环节没有问题会输出提示类似:
----------ABAQUS complete----------
time costed 0:0:26
Abaqus License Manager checked out the following license(s):
"cae" release 6.12 from DESKTOP-8I4F446
<1023 out of 1024 licenses remain available>.
(2)若.odb文件大小正常,逐个检查req参数,软体手指仿真中此句为:
req=['FINGER_8-1,Node FINGER_8-1.1,COOR1']; %指定部件名,节点名和读取的结果
循环获取多个节点输出时可写为:
nodef='Node FINGER_8-1.'; %用instance的名字,不管在abaqus里是大写还是小写这里都写成大写
%节点顺序按abaqus里查看的顺序排列
node=[19,45,955,1032,1231,1309,1507,185,207,1724,1816,2000,2092,2290,364,397,417,437,2866,468];
nx=zeros(27,20);ny=zeros(27,20);nz=zeros(27,20);
for k=1:1:20
nodename=[nodef num2str(node(k))];
k % 输出进度
req=['FINGER_8-1,' nodename ',COOR1']; %指定部件名,节点名和读取的结果
%其他调用部分...
end
注意部件名和节点名必须和.inp文件中一致,且一定要在abaqus中要创建这些节点所需的历程输出(即输出COOR1)。
当时做联合仿真的时候踩了很多坑,本来想记录一下常见报错及解决思路,结果考试周那会儿太忙了没抽出时间,寒假里倒是有时间了,但有哪些坑都忘得差不多了,尝试重新做了一遍居然一次成功,想踩坑的时候倒踩不到了。。。根据记忆整理了本文,如有缺漏有缘再补充。
参考 链接 :
https://blog.csdn.net/hdpai2018/article/details/106113842
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















