















































软件

产品


文本分析是一种有用的技术,可帮助您从给定文本中发现有用的模型数据,例如问题陈述,业务案例,用例描述,域描述,遗留模型描述,甚至遗留代码。
在本教程中,您将学习如何从问题描述中识别类。 之后,将形成类图和序列图。
每个项目都需要最好的Scrum软件
一个强大的Scrum软件,支持Scrum 项目管理 。 它具有Scrum工具,如用户故事地图,产品积压管理,sprint积压管理,任务管理,日常scrum会议,sprint计划工具,sprint审查工具,sprint回顾工具,burndown,障碍,利益相关者和团队管理。
本教程将使用以下问题描述。
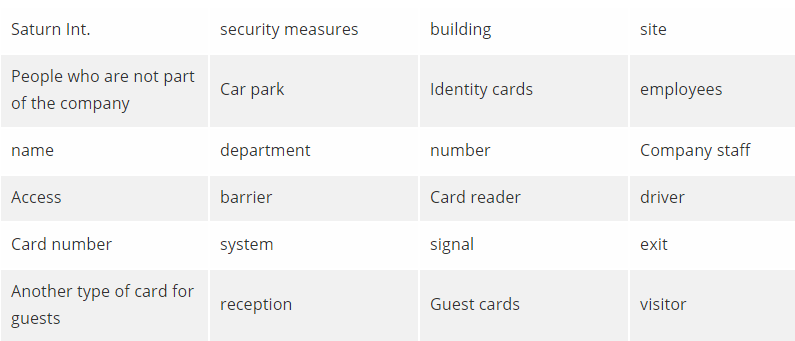
土星国际管理层希望改善他们的建筑和现场安全措施。他们希望阻止不属于公司的人使用他们的停车场。
土星国际已决定向所有员工发放 身份证 。每张卡片记录公司员工的姓名,部门和号码,并允许他们访问公司停车场。要求员工在现场佩戴卡片。
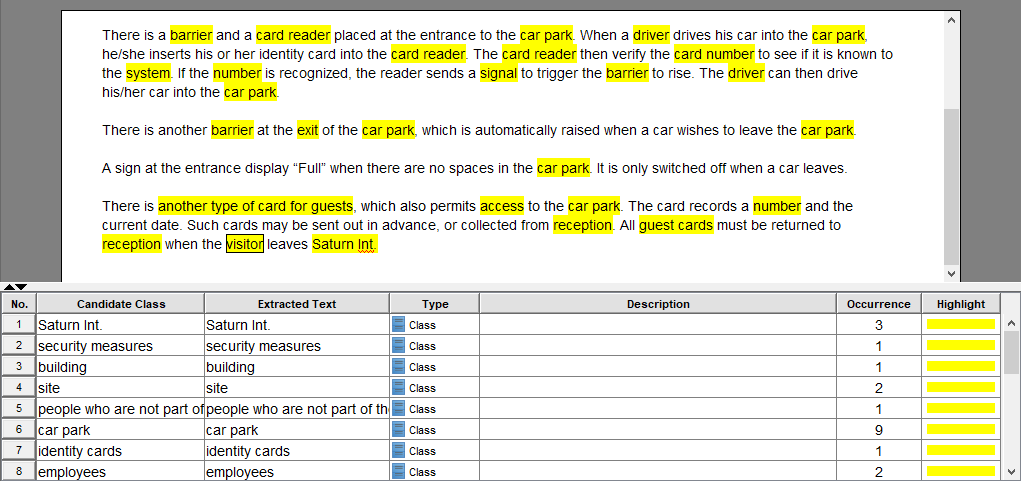
停车场入口处设有障碍物和读卡器。当驾驶员驾驶他的 汽车 进入停车场时,他/她将他或她的身份证插入读卡器。然后,读卡器验证卡号以查看系统是否已知。如果识别出数字,则读取器发送信号以触发屏障上升。然后司机可以将他/她的车开进停车场。
停车场的出口处还有另一个障碍物,当汽车希望离开停车场时,该障碍物会自动升起。
当停车场没有空间时,入口处的标志显示“Full”。它只在汽车离开时关闭。
客人可以使用另一种卡,也可以进入停车场。该卡记录了一个号码和当前日期。这些卡可以提前发送,或从接收处收集。当访客离开Saturn Int时,所有宾客卡必须返回前台。
创建文本分析
从文本中识别候选对象
仔细阅读问题描述以确定候选类。 找到候选项后,右键单击文本段,然后从弹出菜单中选择“Add text as Class”。

候选类列表如下:
到目前为止,Textual Analysis 编辑器 应如下所示:
拒绝候选对象
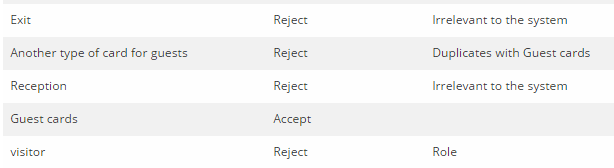
在本节中,将根据拒绝规则列表审查这些候选类。 到本节结束时,将获得一个类模型列表。
现在,根据拒绝规则查看候选类列表:
下表列出了审核结果:
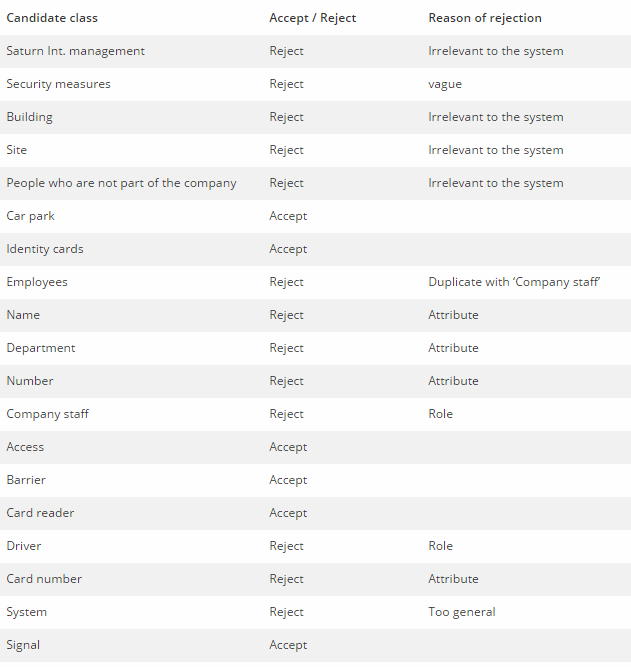
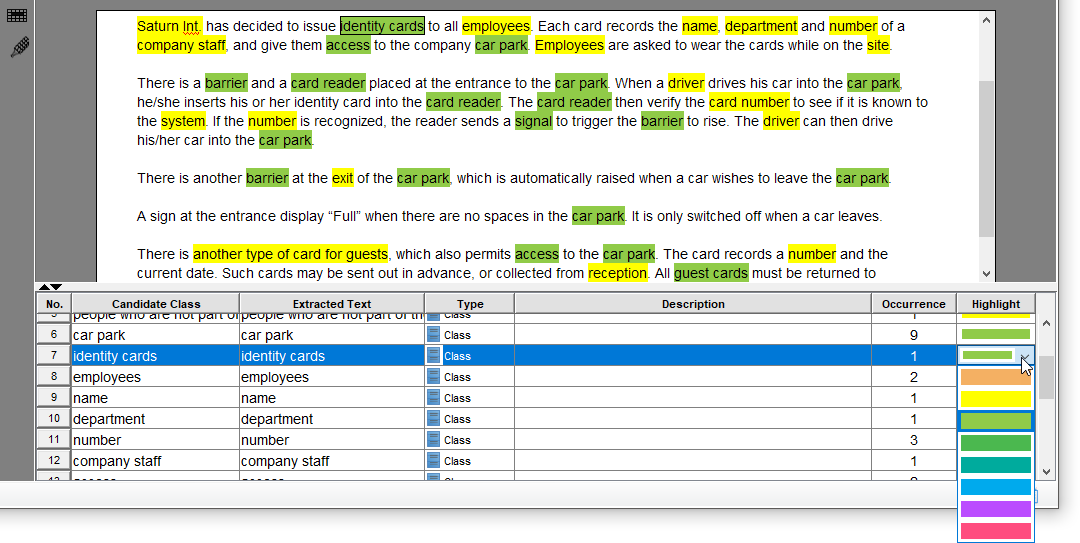
为区分已接受和被拒绝的候选类别,让我们将突出显示颜色更改为绿色。 要执行此操作,请单击带有黄色突出显示的单元格,然后从颜色选择器中选择绿色。
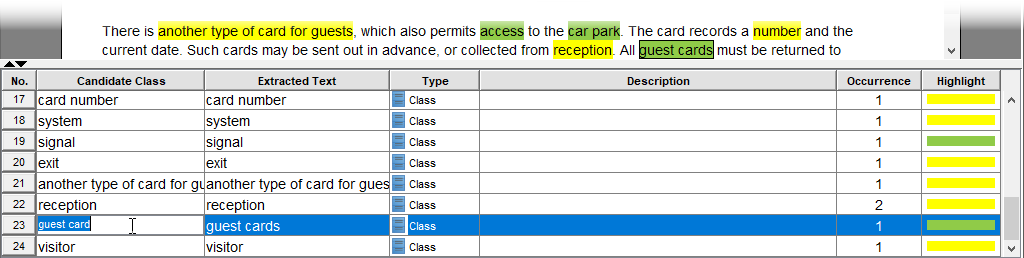
现在,剩下的候选类列表如下:

重新识别已识别的类
让我们将接受的候选者改写为:(1)在使用单数和复数之间统一名词形式和(2)准确地反映提取文本的含义。
请阅读下表,了解所需的更改和更改说明。
| Extracted text | Rephrase to | Reason |
| car park | ||
| identity cards | staff card | “Identity cards”字面意思是各种卡,但根据段落,“Identity cards”一词来自名词短语“identity cards to all employees”,所以它实际上意味着员工卡。 我们将重新措辞以避免混淆。 |
| access | ||
| barrier | ||
| card reader | ||
| signal | ||
| exit | ||
| guest cards | guest card | 使用单数名词改变符合其他单词 |
相应地更新候选类的名称:
从文本创建类模型元素
您已经确定了一个类列表。 要在模型构造中使用它们,您需要将它们从单词转换为模型元素。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















