















































软件

产品


kaggle - Jane Street Market Prediction
https://www.kaggle.com/c/jane-street-market-prediction/overview
赛题数据: 匿名时序结构化 数据;
train.csv 训练集,包含历史数据和返回值example_test.csv 样例测试集,它展示了看不见的测试集的结构example_sample_submission.csv 样例提交文件features.csv 匿名特征的元数据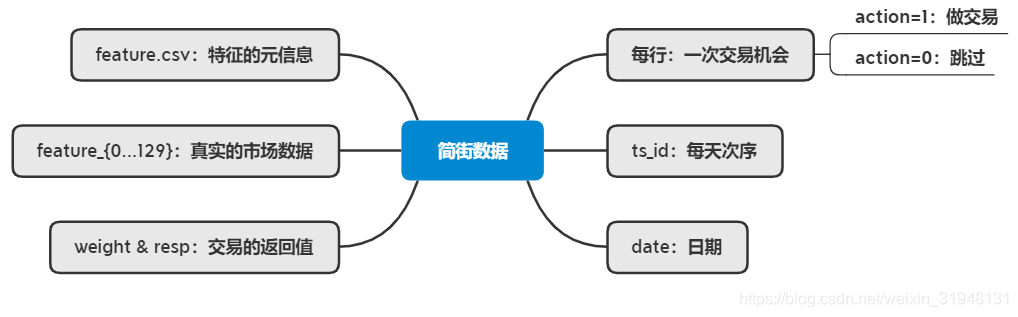
赛题任务:时序数据 的分类任务;
赛题思路:构建 分类模型 来完整;
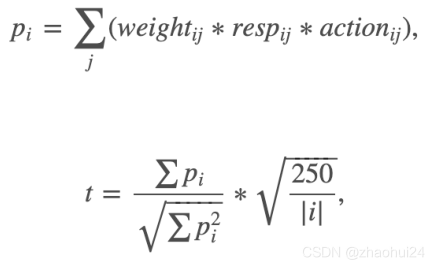
weight 字段:含义未知,但参与最终打分;当 weight 取值为 0 时,不参与打分;resp 字段:收益回报,有正有负;resp 取值为负,则 action 应该为 0,resp大于0,则action为 1
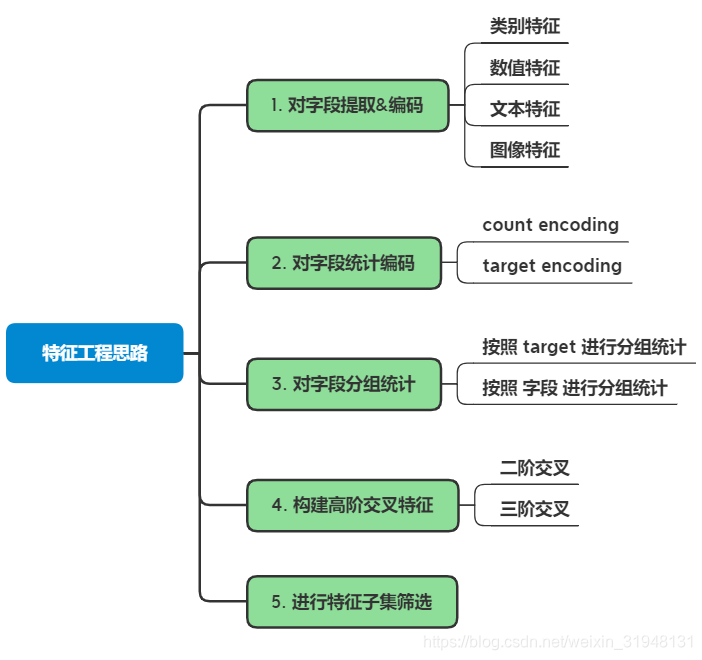
匿名数据如何进行分析,如何做特征工程?
参考链接 - Jane Street: EDA of day 0 and feature importance ⭐️ ⭐️
train.csv 的 dataframe

shape : (2390491, 138),后面未显示是 feature_0 至 feature_129 , ts_id ,action 列。
train.csv 大数据量 使用 datatable 处理,对比 pandas 读取速度快很多。
reading this magnificent kaggle - Tutorial on reading large datasets by Vopani
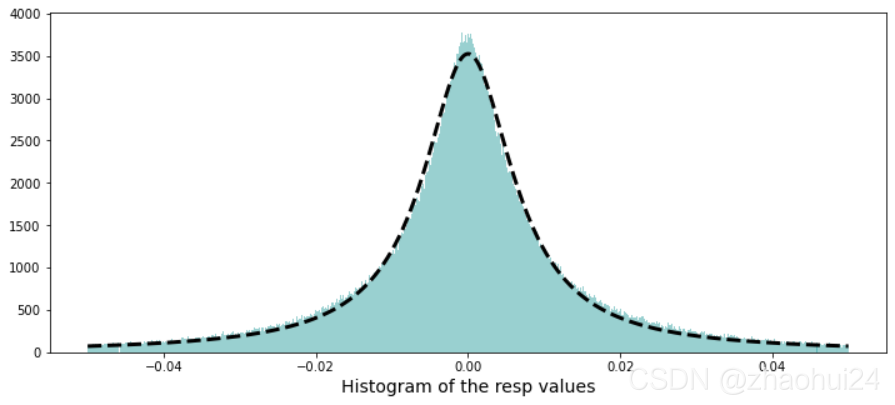
3.1.2 resp 特征 数据格式 形式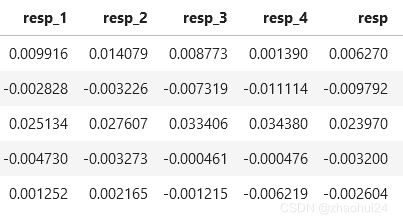
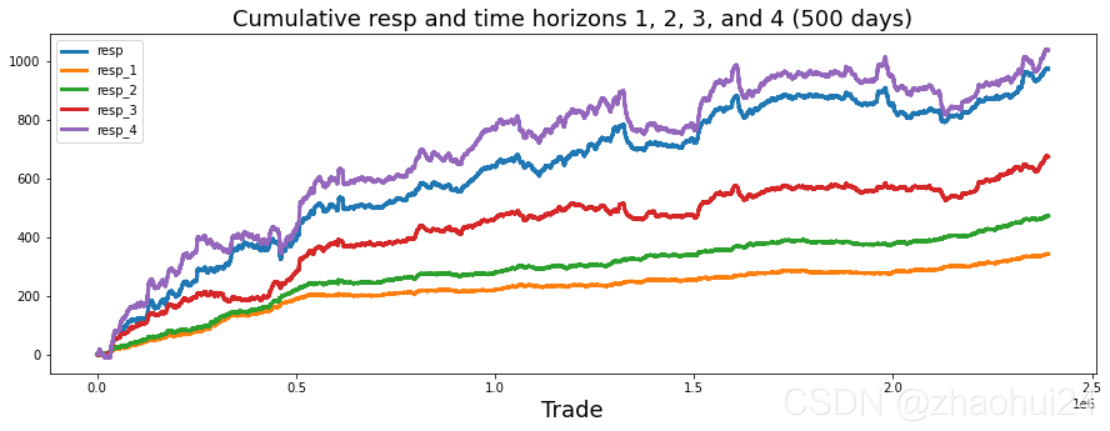
对resp列做画条形图,仅显示值在 -0.05 ~ 0.05 范围。
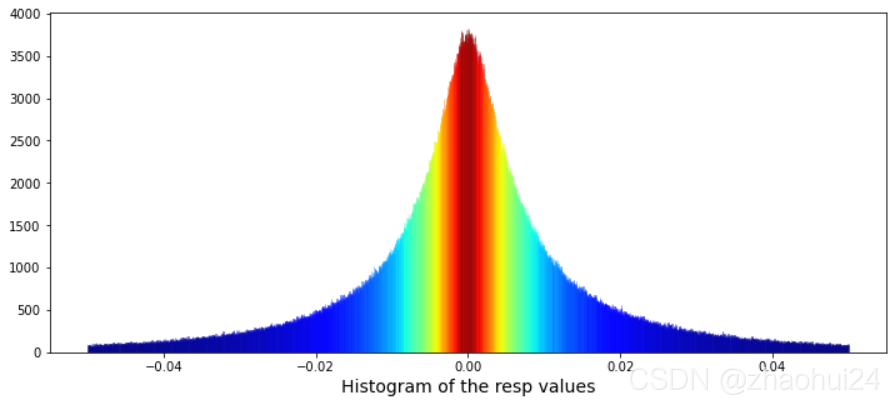
Calculate the skew and kurtosis of this distribution。
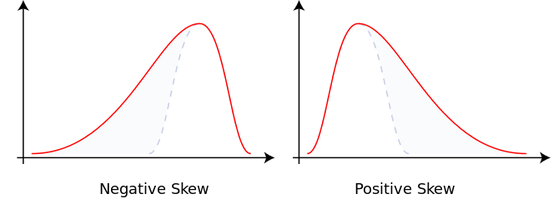
图源:Skewness - wikipedia
使用柯西分布进行线性拟合
由于柯西分布具有长尾特性 参考链接 - 神奇的柯西分布,可以对上面条形图进行拟合。
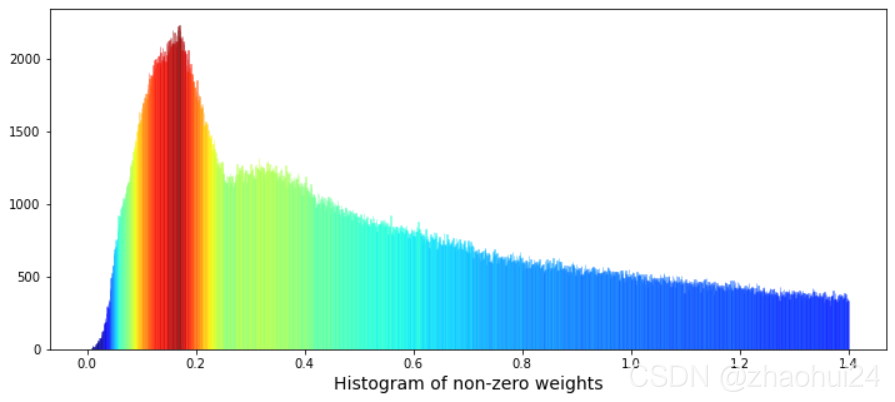
3.1.3 weight 特征 权重值为 0的行进行统计,占 17%。对 weight列画出条形图,显示范围在 0.001~1.4 之间的值。
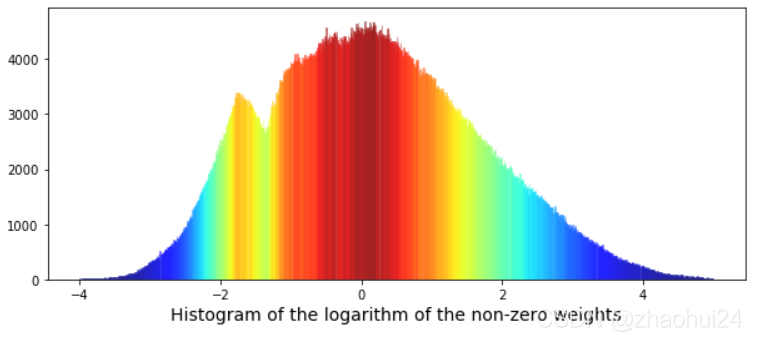
对权重值 weight 进行 降序排序后,再进行画图,发现是一个双峰图。
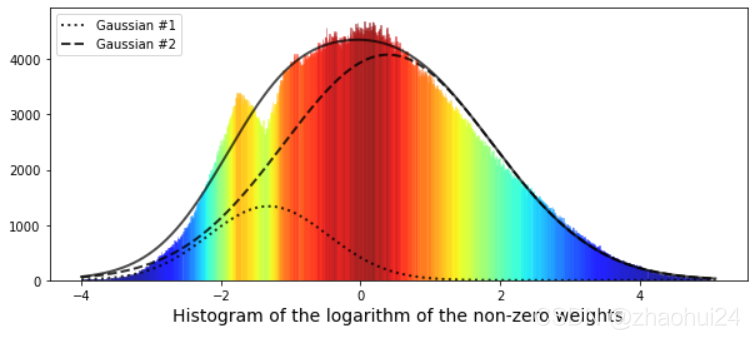
使用 高斯函数 进行拟合,黑色实线 为两条高斯函数曲线的叠加。
3.1.4 date ,ts_id 特征 猜想交易模式发生在第 85 天,分组统计 500天 中的 ts_id 数量。
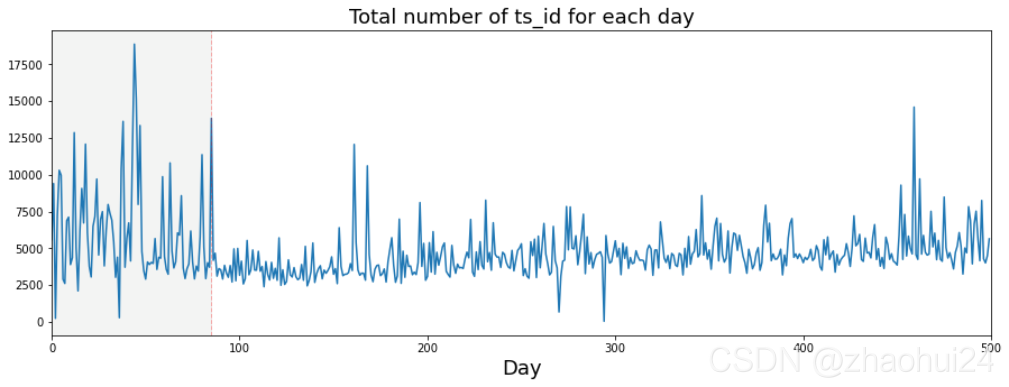
画出每天交易量的条形图

发现 大交易日( more than 9k trades)大多数在 85天 之前。
3.1.5 feature 特征 对特征 feature_0 单独分析,发现值仅有 -1 和 1 两种取值,后面章节对其重点分析。
对 feature_1 至 feature_129 共 129 个特征单独分析,发现似乎有 4 种一般 类型 的特征,下面是4种特征的示例图(举例)
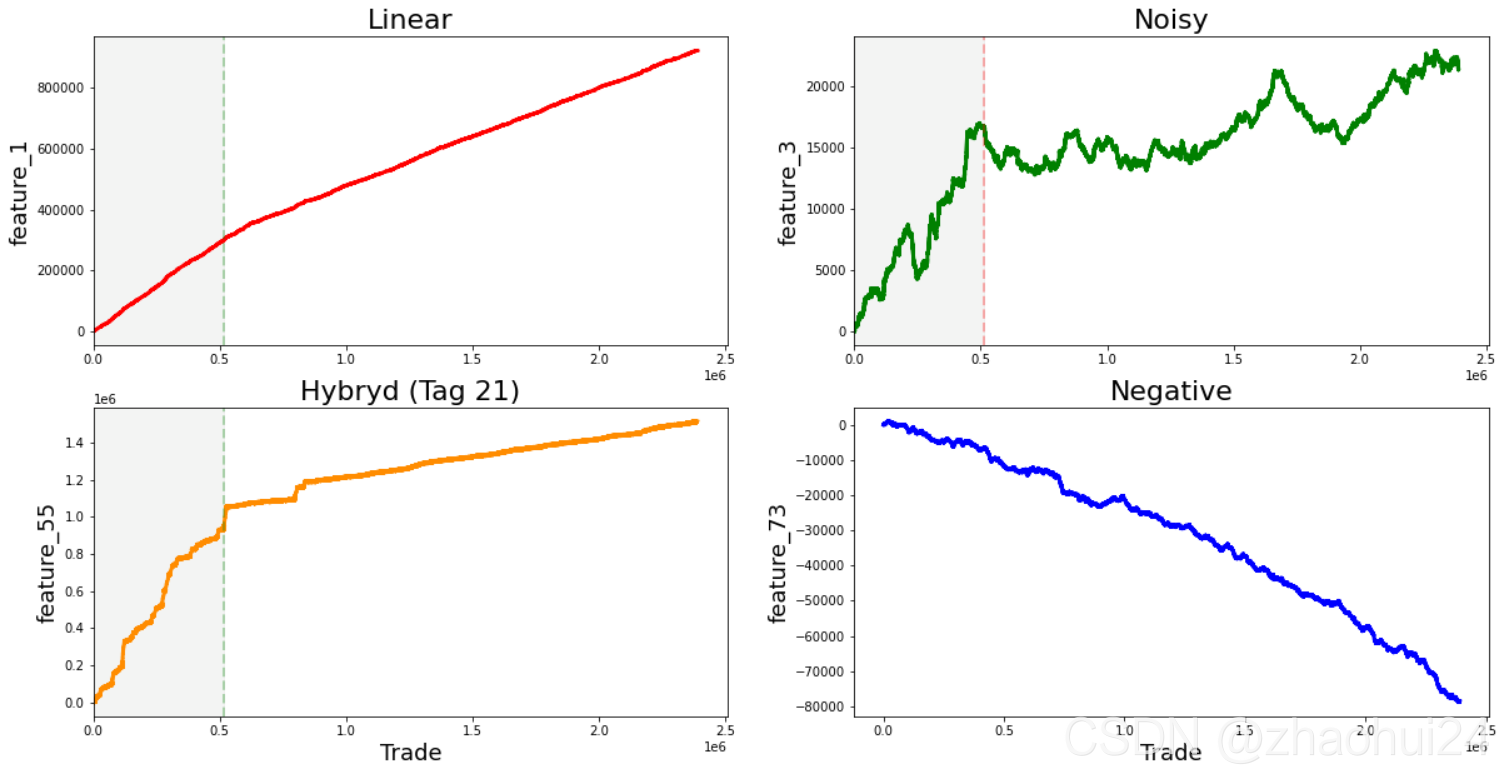
对每一个特征画出其走势图,发现它们符合以上 4 种曲线走势,根据其自身图形进行划分。
1 7, 9, 11, 13, 15 17, 19, 21, 23, 25 18, 20, 22, 24, 26 27, 29, 21, 33, 35 28, 30, 32, 34, 36 84, 85, 86, 87, 88 90, 91, 92, 93, 94 96, 97, 98, 99, 100 102 (strong change in gradient), 103, 104, 105, 106 as well as 41, 46, 47, 48, 49, 50, 51, 53, 54, 69, 89, 95 (strong change in gradient), 101, 107 (strong change in gradient), 108, 110, 111, 113, 114, 115, 116, 117, 118, 119 (strong change in gradient), 120, 122, and 124.
……
3.1.6 action 特征 action的数值为 0,1 两种形式,统计出每天交易为 1 (action=1)的数量占比。
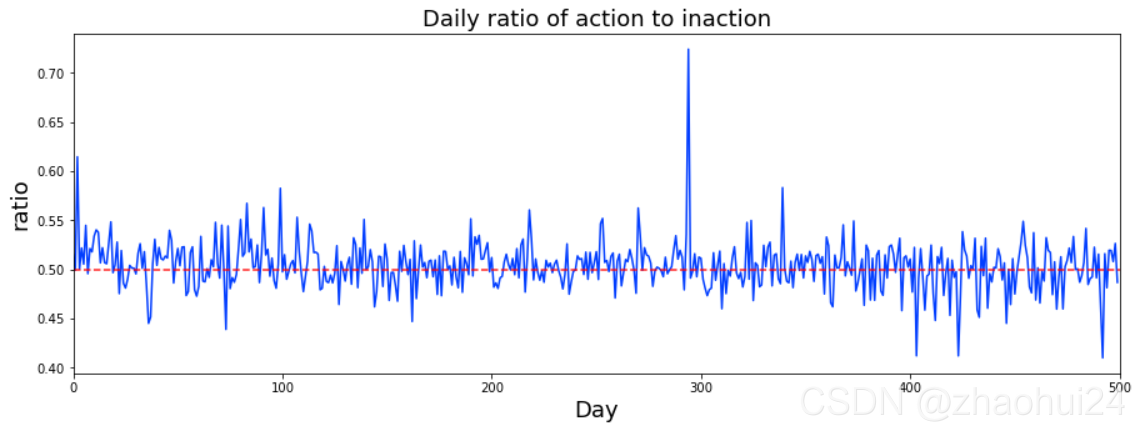
3.1.7 the first day day_0 特征 与 缺失值查看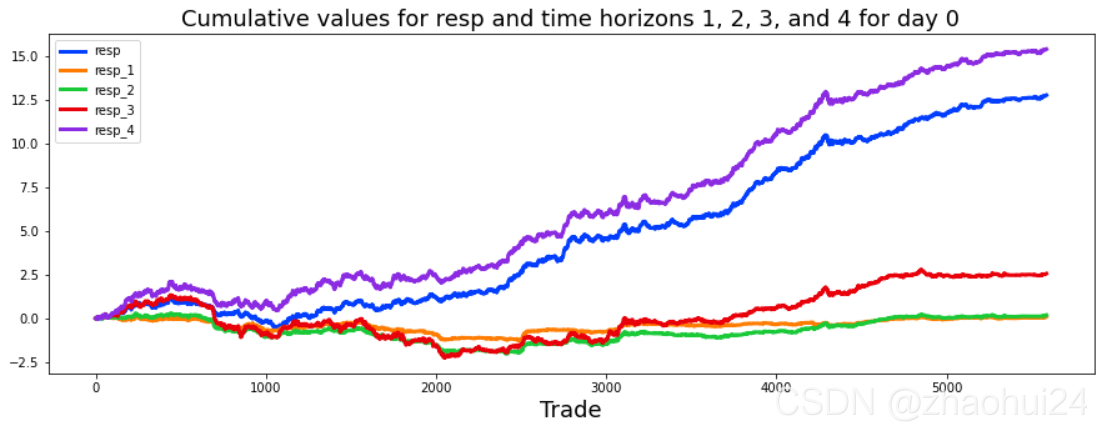
对 day_0 所有139个特征,缺失值的查看
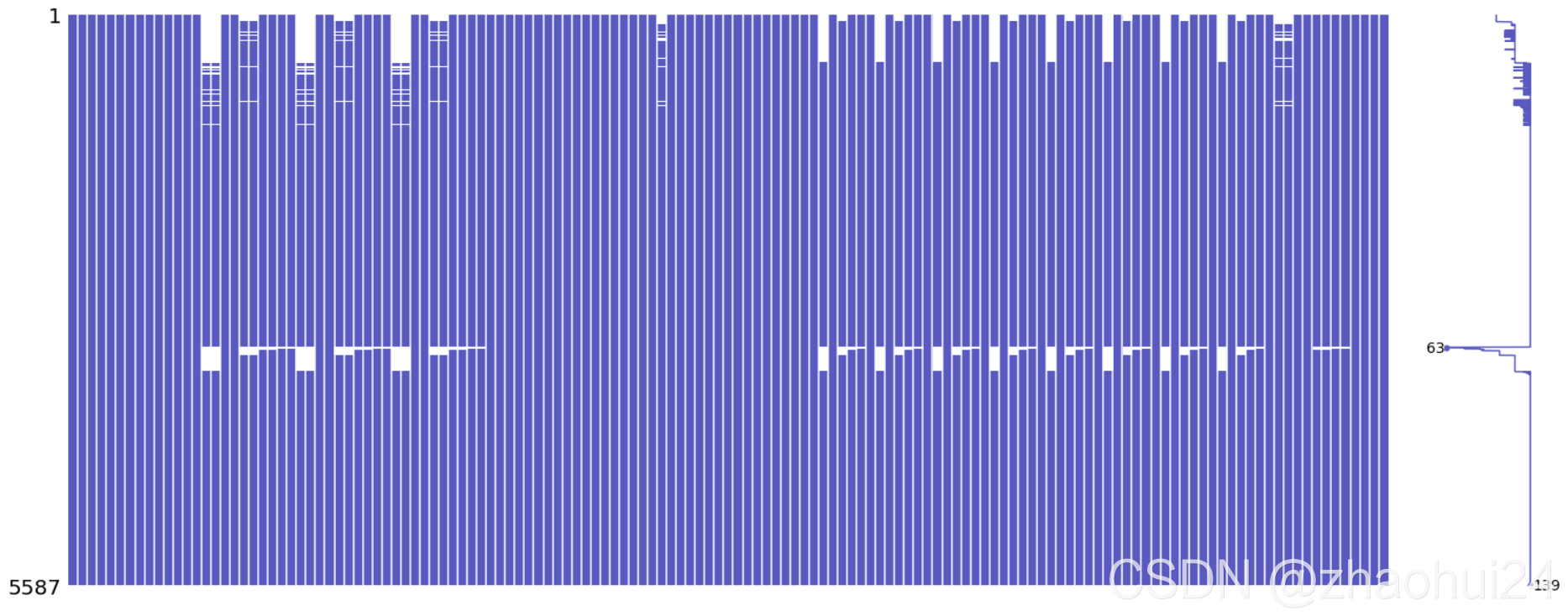
对整个 训练数据集统计缺失值 情况。
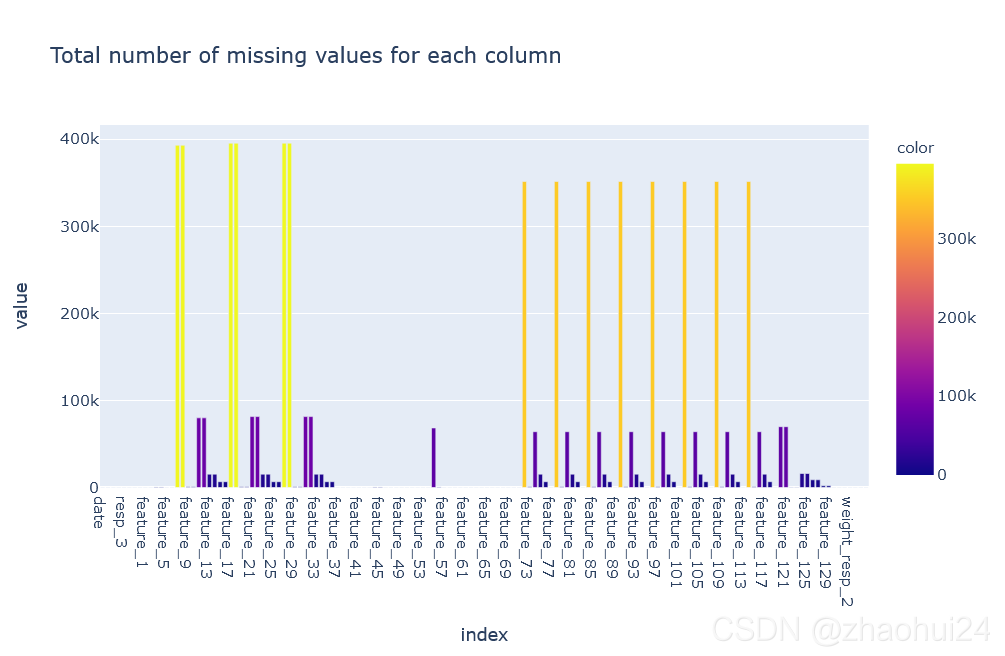
使用 missingno 库画缺失值图
msno.dendrogram(train_data.iloc[:500, :]) # 根据缺失值的特征,将其组合到一起,构成框图
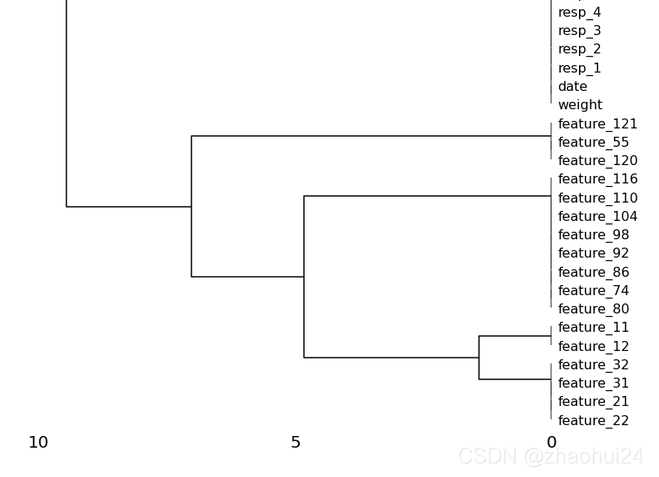
局部图截取
缺失值填充 方法有
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















