















































软件

产品


之前自己学习了Kubernetes,加上Spark还需要依赖JDK和Hadoop,想想还是用Kubernetes安装Spark会更加方便。
我是参考这篇文章:
来看看基于Kubernetes的Spark部署完全指南
https://blog.51cto.com/linux2023/5011645
对应的 Docker 镜像Dockerfile文件和Kubernetes yaml文件下载:
developerhq/spark-kubernetes
https://github.com/developerhq/spark-kubernetes
https://github.com/developerhq/spark-kubernetes
记录一下自己遇到的几个问题:
(1)Error: Unable to initialize main class org.apache.spark.deploy.SparkSubmit Caused by: java.lang.NoClassDefFoundError: org/slf4j/Logger
我把文章里面提到的配置添加到了Dockerfile文件中,在Dockerfile文件末尾添加一行:
ENV SPARK_DIST_CLASSPATH=$HADOOP_HOME/etc/hadoop/*:$HADOOP_HOME/share/hadoop/common/lib/*:$HADOOP_HOME/share/hadoop/common/*:$HADOOP_HOME/share/hadoop/hdfs/*:$HADOOP_HOME/share/hadoop/hdfs/lib/*:$HADOOP_HOME/share/hadoop/hdfs/*:$HADOOP_HOME/share/hadoop/yarn/lib/*:$HADOOP_HOME/share/hadoop/yarn/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*:$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/tools/lib/*
(2)Spark执行样例报警告:WARN scheduler.TaskSchedulerImpl: Initial job has not accepted any resources
我在执行xx.collect命令的时候一直提示资源不足。同样的,我在Dockerfile镜像文件末尾加上以下2行:
ENV SPARK_WORKER_MEMORY=512m
ENV SPARK_WORKER_CORES=1
在上面developerhq/spark-kubernetes下载的spark-container/spark-defaults.conf文件(与Dockerfile同一级目录下)末尾加上:
spark.executor.memory 512m
这个spark.executor.memory不能设置得过小,要求大于471859200kb,不然启动/opt/spark/bin/spark-shell的时候会报错。
(3)用Dockerfile文件构造好镜像之后,需要push到自己的远程仓库,然后kubernetes的yaml文件从自己的远程仓库拉取镜像。
执行三个yaml文件会创建三个Pod,一主二从。
我这里指定了NodePort
进入一个worker pod的容器 执行 /opt/spark/bin/spark-shell
val r1 = sc.makeRDD(List(1,2,3,4),2)
r1.collect
注意得在worker节点执行collect命令。我在master节点执行collect命令 一直会报资源不足异常。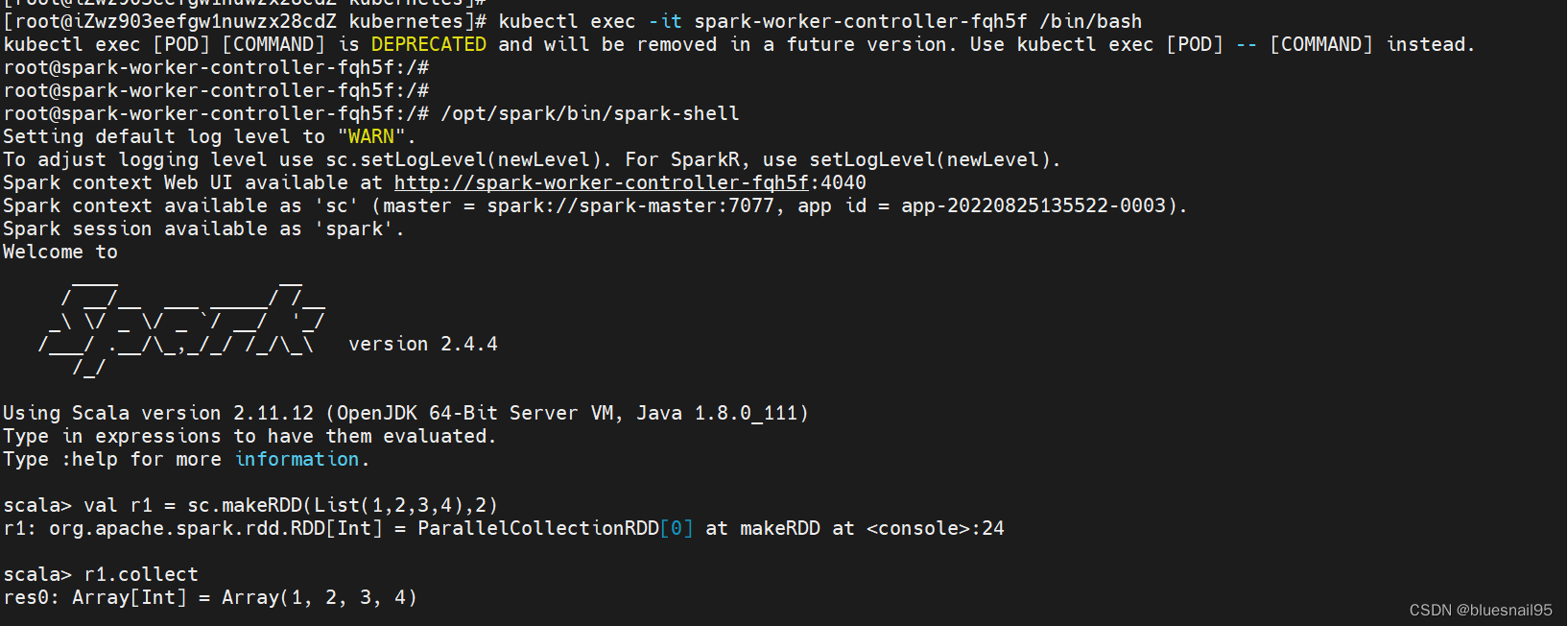
在spark-master-controller.yaml文件了设置了2个容器端口7077和8080。我在spark-master-service.yaml文件指定了NodePort。所有我是访问Node:30011就进入这个cluster UI界面 。
Workers下面有2个worker,每个worker的Memory和Cores是由Dockerfile设置ENV SPARK_WORKER_MEMORY=512m和ENV SPARK_WORKER_CORES=1决定的。
Running Applications是只有启动了/opt/spark/bin/spark-shell才会出现,这里的Memory per Executor是在spark-defaults.conf设置的。这里的State得是Running才是正常的。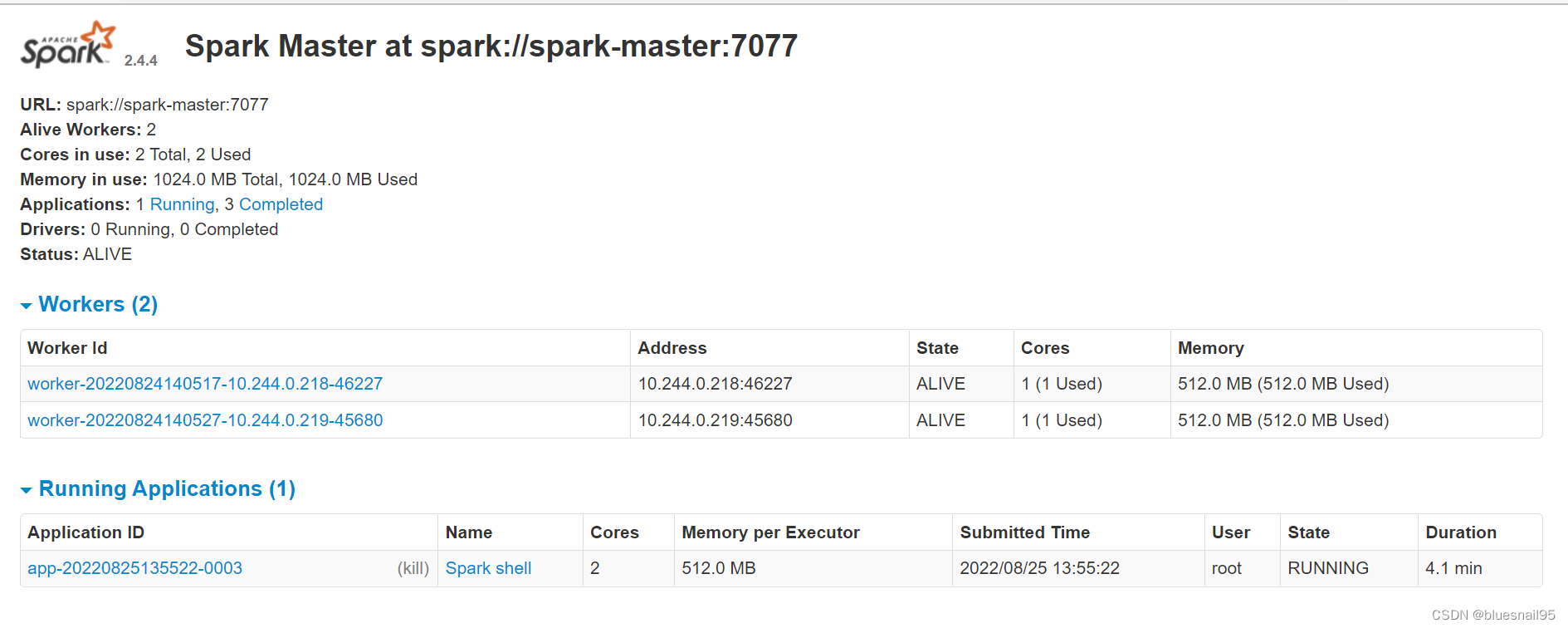
关闭的/opt/spark/bin/spark-shell就会出现在Completed Applications面板中。

免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















