















































软件

产品


基于VQ的说话人识别系统,矢量量化起着双重作用。在训练阶段,把每一个说话者所提取的特征参数进行分类,产生不同码字所组成的码本。在识别(匹配)阶段,我们用VQ方法计算平均失真测度(本系统在计算距离d时,采用欧氏距离测度),从而判断说话人是谁。
语音识别系统结构框图如图1所示。

图1 语音识别系统结构框图
语者识别的概念
语者识别就是根据说话人的语音信号来判别说话人的身份。语音是人的自然属性之一,由于说话人发音器官的生理差异以及后天形成的行为差异,每个人的语音都带有强烈的个人色彩,这就使得通过分析语音信号来识别说话人成为可能。用语音来鉴别说话人的身份有着许多独特的优点,如语音是人的固有的特征,不会丢失或遗忘;语音信号的采集方便,系统设备成本低;利用电话网络还可实现远程客户服务等。因此,近几年来,说话人识别越来越多的受到人们的重视。与其他生物识别技术如指纹识别、手形识别等相比较,说话人识别不仅使用方便,而且属于非接触性,容易被用户接受,并且在已有的各种生物特征识别技术中,是唯一可以用作远程验证的识别技术。因此,说话人识别的应用前景非常广泛:今天,说话人识别技术已经关系到多学科的研究领域,不同领域中的进步都对说话人识别的发展做出了贡献。说话人识别技术是集声学、语言学、计算机、信息处理和人工智能等诸多领域的一项综合技术,应用需求将十分广阔。在吃力语音信号的时候如何提取信号中关键的成分尤为重要。语音信号的特征参数的好坏直接导致了辨别的准确性。
特征参数的提取
对于特征参数的选取,我们使用mfcc的方法来提取。MFCC参数是基于人的听觉特性利用人听觉的屏蔽效应,在Mel标度频率域提取出来的倒谱特征参数。
MFCC参数的提取过程如下:
设语音信号的DFT为:
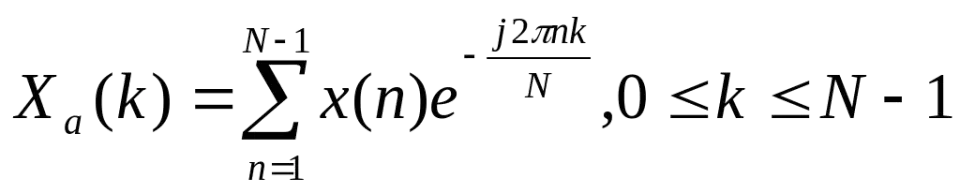
其中式中x(n)为输入的语音信号,N表示傅立叶变换的点数。
我们定义一个有M个滤波器的滤波器组(滤波器的个数和临界带的个数相近),采用的滤波器为三角滤波器,中心频率为f(m),m=1,2,3,···,M
本系统取M=100。
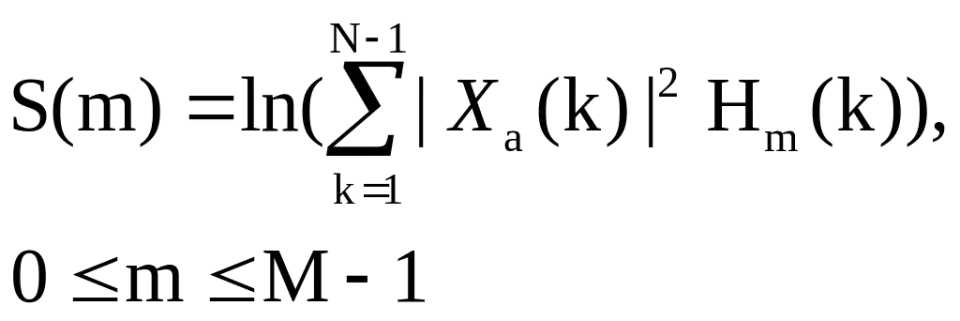
其中为三角滤波器的频率响应。
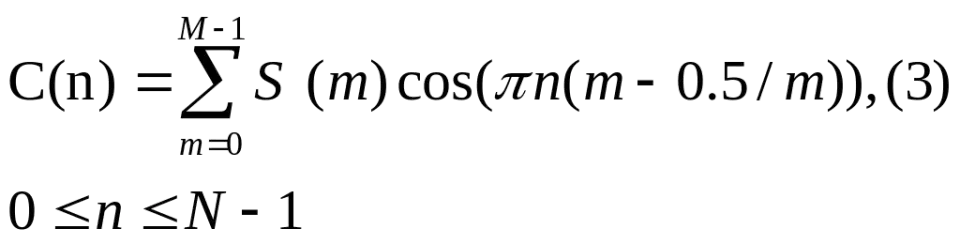
MFCC系数个数通常取20—30,常常不用0阶倒谱系数,因为它反映的是频谱能量,故在一般识别系统中,将称为能量系数,并不作为倒谱系数,本系统选取20阶倒谱系数。
用矢量量化聚类法生成码本
我们将每个待识的说话人看作是一个信源,用一个码本来表征。码本是从该说话人的训练序列中提取的MFCC特征矢量聚类而生成。只要训练的序列足够长,可认为这个码本有效地包含了说话人的个人特征,而与讲话的内容无关。
本系统采用基于分裂的LBG的算法设计VQ码本,为训练序列,B为码本。
具体实现过程如下:
其中m从1变化到当前的码本的码字数,ε是分裂时的参数,本文ε=。
量化失真量和:

相对失真:
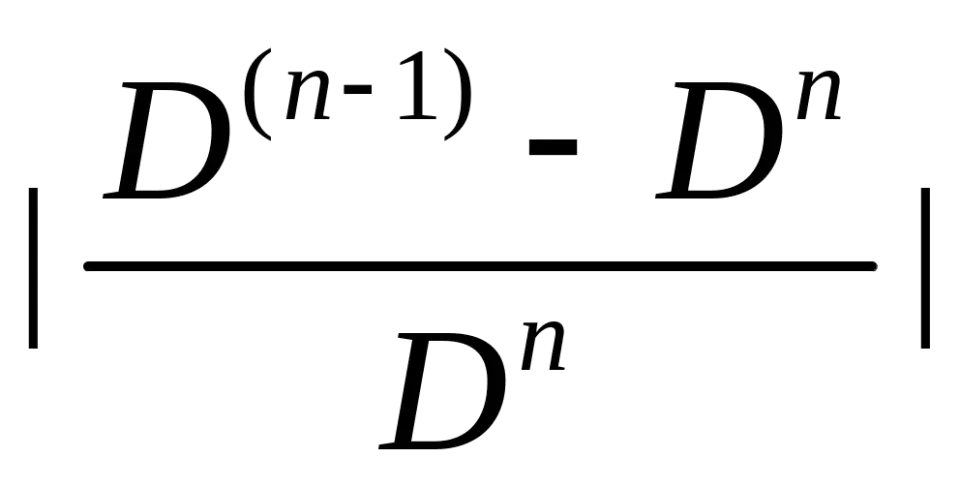
4. 重新计算各个区域的新型心,得到新的码书,转3。
5. 重复2 ,3 和4步,直到形成有M个码字的码书(M是所要求的码字数),其中D0=10000。
VQ的说话人识别
设是未知的说话人的特征矢量,共有T帧是训练阶段形成的码书,表示码书第m个码字,每一个码书有M个码字。再计算测试者的平均量化失真D,并设置一个阈值,若D小于此阈值,则是原训练者,反之则认为不是原训练者。

在具体的实现过程当中,采用了matlab软件来帮助完成这个项目。在matlab中主要由采集,分析,特征提取,比对几个重要部分。以下为在实际的操作中,具体用到得函数关系和作用一一列举在下面。
函数关系
主要有两类函数文件和
在调用获取训练录音的vq码本,而调用获取单个录音的mel倒谱系数,接着调用将能量谱通过一组Mel尺度的三角形滤波器组。
在函数文件中调用计算训练录音(提供vq码本)与测试录音(提供mfcc)mel倒谱系数的距离,即判断两声音是否为同一录音者提供。调用获取单个录音的mel倒谱系数。调用将能量谱通过一组Mel尺度的三角形滤波器组。
具体代码说明
函数mffc:
function r = mfcc(s, fs)
---
m = 100;
n = 256;
l = length(s);
nbFrame = floor((l - n) / m) + 1; %沿-∞方向取整
for i = 1:n
for j = 1:nbFrame
M(i, j) = s(((j - 1) * m) + i); %对矩阵M赋值
end
end
h = hamming(n); %加 hamming 窗,以增加音框左端和右端的连续性
M2 = diag(h) * M;
for i = 1:nbFrame
frame(:,i) = fft(M2(:, i)); %对信号进行快速傅里叶变换FFT
end
t = n / 2;
tmax = l / fs;
m = melfb(20, n, fs); %将上述线性频谱通过Mel 频率滤波器组得到Mel 频谱,下面在将其转化成对数频谱
n2 = 1 + floor(n / 2);
z = m * abs(frame(1:n2, :)).^2;
r = dct(log(z)); %将上述对数频谱,经过离散余弦变换(DCT)变换到倒谱域,即可得到Mel 倒谱系数(MFCC参数)
函数disteu
---计算测试者和模板码本的距离
function d = disteu(x, y)
[M, N] = size(x); %音频x赋值给【M,N】
[M2, P] = size(y); %音频y赋值给【M2,P】
if (M ~= M2)
error('不匹配!') %两个音频时间长度不相等
end
d = zeros(N, P);
if (N < P)%在两个音频时间长度相等的前提下
copies = zeros(1,P);
for n = 1:N
d(n,:) = sum((x(:, n+copies) - y) .^2, 1);
end
else
copies = zeros(1,N);
for p = 1:P
d(:,p) = sum((x - y(:, p+copies)) .^2, 1)';
end%%成对欧氏距离的两个矩阵的列之间的距离
end
d = d.^;
函数vqlbg
---该函数利用矢量量化提取了音频的vq码本
function r = vqlbg(d,k)
e = .01;
r = mean(d, 2);
dpr = 10000;
for i = 1:log2(k)
r = [r*(1+e), r*(1-e)];
while (1 == 1)
z = disteu(d, r);
[m,ind] = min(z, [], 2);
t = 0;
for j = 1:2^i
r(:, j) = mean(d(:, find(ind == j)), 2);
x = disteu(d(:, find(ind == j)), r(:, j));
for q = 1:length(x)
t = t + x(q);
end
end
if (((dpr - t)/t) < e)
break;
else
dpr = t;
end
end
end
函数test
function finalmsg = test(testdir, n, code)
for k = 1:n % read test sound file of each speaker
file = sprintf('%ss%', testdir, k);
[s, fs] = wavread(file);
v = mfcc(s, fs); % 得到测试人语音的mel倒谱系数
distmin = 4; %阈值设置处
% 就判断一次,因为模板里面只有一个文件
d = disteu(v, code{1}); %计算得到模板和要判断的声音之间的“距离”
dist = sum(min(d,[],2)) / size(d,1); %变换得到一个距离的量
%测试阈值数量级
msgc = sprintf('与模板语音信号的差值为:%10f ', dist);
disp(msgc);
%此人匹配
if dist <= distmin %一个阈值,小于阈值,则就是这个人。
msg = sprintf('第%d位说话者与模板语音信号匹配,符合要求! ', k);
finalmsg = '此位说话者符合要求!'; %界面显示语句,可随意设定
disp(msg);
end
%此人不匹配
if dist > distmin
msg = sprintf('第%d位说话者与模板语音信号不匹配,不符合要求! ', k);
finalmsg = '此位说话者不符合要求!'; %界面显示语句,可随意设定
disp(msg);
end
end
函数testDB
这个函数实际上是对数据库一个查询,根据测试者的声音,找相应的文件,并且给出是谁的提示
function testmsg = testDB(testdir, n, code)
nameList={'1','2','3','4','5','6','7','8','9' }; %这个是我们要识别的9个数
for k = 1:n % 数据库中每一个说话人的特征
file = sprintf('%ss%', testdir, k); %找出文件的路径
[s, fs] = wavread(file);
v = mfcc(s, fs); % 对找到的文件取mfcc变换
distmin = inf;
k1 = 0;
for l = 1:length(code)
d = disteu(v, code{l});
dist = sum(min(d,[],2)) / size(d,1);
if dist < distmin
distmin = dist;%%这里和test函数里面一样 但多了一个具体语者的识别
k1 = l;
end
end
msg=nameList{k1}
msgbox(msg);
end
函数train
---该函数就是对音频进行训练,也就是提取特征参数
function code = train(traindir, n)
k = 16; % number of centroids required
for i = 1:n % 对数据库中的代码形成码本
file = sprintf('%ss%', traindir, i);
disp(file);
[s, fs] = wavread(file);
v = mfcc(s, fs); % 计算 MFCC's 提取特征特征,返回值是Mel倒谱系数,是一个log的dct得到的
code{i} = vqlbg(v, k); % 训练VQ码本 通过矢量量化,得到原说话人的VQ码本
end
函数melfb
---确定矩阵的滤波器
function m = melfb(p, n, fs)
f0 = 700 / fs;
fn2 = floor(n/2);
lr = log(1 + f0) / (p+1);
% convert to fft bin numbers with 0 for DC term
bl = n * (f0 * (exp([0 1 p p+1] * lr) - 1));
直接转换为FFT的数字模型
b1 = floor(bl(1)) + 1;
b2 = ceil(bl(2));
b3 = floor(bl(3));
b4 = min(fn2, ceil(bl(4))) - 1;
pf = log(1 + (b1:b4)/n/f0) / lr;
fp = floor(pf);
pm = pf - fp;
r = [fp(b2:b4) 1+fp(1:b3)];
c = [b2:b4 1:b3] + 1;
v = 2 * [1-pm(b2:b4) pm(1:b3)];
m = sparse(r, c, v, p, 1+fn2);
我们的功能分为两部分:对已经保存的9个数字的语音进行辨别和实时的判断说话人说的是否为一个数.在前者的实验过程中,先把9个数字的声音保存成wav的格式,放在一个文件夹中,作为一个检测的数据库.然后对检测者实行识别,系统给出提示是哪个数字.
在第二个功能中,实时的录取一段说话人的声音作为模板,提取mfcc特征参数,随后紧接着进行遇着识别,也就是让其他人再说相同的话,看是否是原说话者.
实验过程及具体功能如下:
先打开Matlab 使Current Directory为录音及程序所所在的文件夹
再打开文件“”,点run运行,打开enter界面,点击“进入”按钮进入系统。(注:文件包未封装完毕,目前只能通过此方式打开运行。)(如下图figure1)
figure1
在对数据库中已有的语者进行识别模块:

选择载入语音库语音个数;
点击语音库录制模版进行已存语音信息的提取;
点击录音-test进行现场录音;
点击语者判断进行判断数字,并显示出来。
在实时语者识别模块:

点击实时录制模板上的“录音-train”按钮,是把新语者的声音以wav格式存放在”实时模板”文件夹中, 接着点击“实时录制模板”,把新的模板提取特征值。随后点击实时语者识别模板上的“录音-train”按钮,是把语者的声音以wav格式存放在”测试”文件夹中,再点击“实时语者识别”,在对测得的声音提取特征值的同时,和实时模板进行比对,然后得出是否是实时模板中的语者。另外面板上的播放按钮都是播放相对应左边录取的声音。
想要测量多次,只要接着录音,自动保存,然后程序比对音频就可以。
退出只要点击菜单File/Exit,退出程序。
程序运行截图:
()运行后系统界面
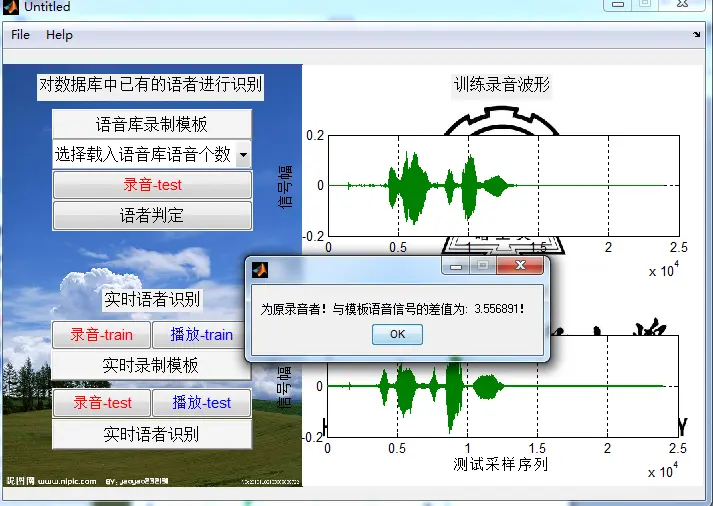
六、结论
实验表明,该系统能较好地进行语音的识别,同时,基于矢量量化技术 (VQ)的语音识别系统具有分类准确,存储数据少,实时响应速度快等综合性能好的特点.
矢量量化技术在语音识别的应用方面,尤其是在孤立词语音识别系统中得到很好的应用,特别是有限状态矢量量化技术,对于语音识别更为有效。
通过这次课程设计,我对语音识别有了更加形象化的认识,也强化了MATLAB的应用,对将来的学习奠定了基础。
如果课题设计中遇到困难疑惑之处,也可向小编咨询哟。
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















