















































软件

产品


March 20, 2019 in efk, fluentd
fluentd2 是一个针对日志的收集、处理、转发系统。通过丰富的插件系统, 可以收集来自于各种系统或应用的日志,转化为用户指定的格式后,转发到用户所指定的日志存储系统之中。
本文由 简悦 SimpRead 转码, 原文地址 https://blog.laisky.com/p/fluentd/
fluentd v1.0 updated at 2016/10/8 updated at 2018/1/9: 完善内容 updated at 2018/1/23: 增加示例,更新为 v1.0 updated at 2018/4/9: 增加负载均衡 updated at 2018/4/25: 增加了负载均衡的一些实践细节
fluentd2 是一个针对日志的收集、处理、转发系统。通过丰富的插件系统, 可以收集来自于各种系统或应用的日志,转化为用户指定的格式后,转发到用户所指定的日志存储系统之中。
通过 fluentd,你可以非常轻易的实现像追踪日志文件并将其过滤后转存到 MongoDB 这样的操作。fluentd 可以彻底的将你从繁琐的日志处理中解放出来。
用图来做说明的话,使用 fluentd 以前,你的系统是这样的:
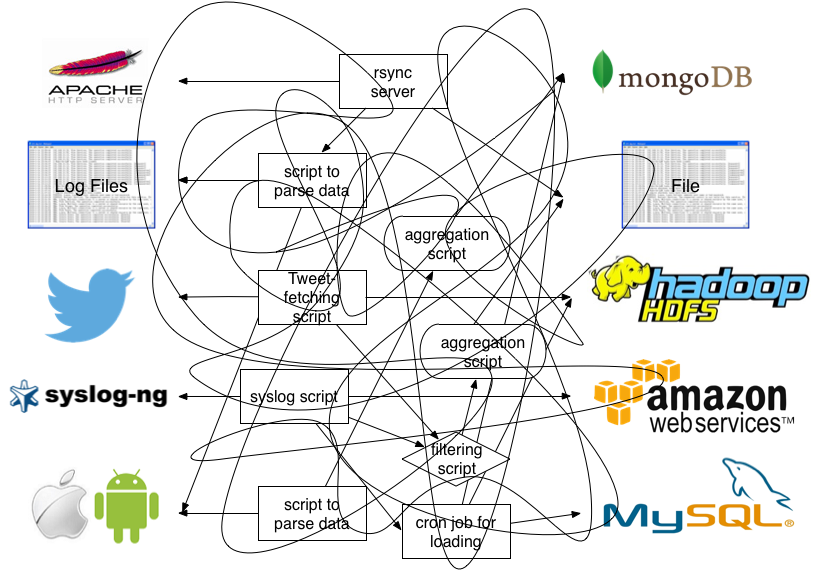
使用了 fluentd 后,你的系统会成为这样:
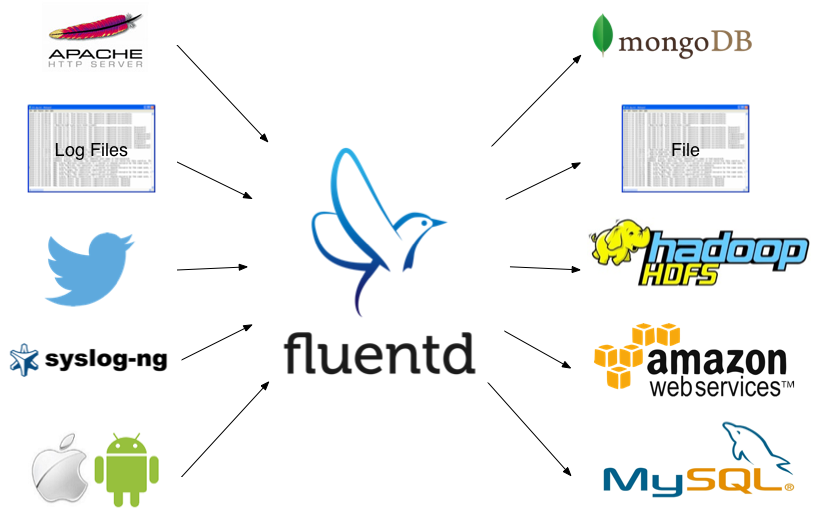
(图片来源3)
此文将会对 fluentd 的安装、配置、使用等各方面做一个简要的介绍。
fluentd 既可以作为日志收集器安装到每一个结点上, 也可以作为一个服务端收集各个结点上报的日志流。 你甚至也可以在各个结点上都部署 fluentd 收集日志,然后上报到一个 fluentd 集群做统一处理, 然后再转发到最终的日志存储服务器。
所以在一个完整的日志收集、处理系统里,你可以构建一个这样的日志处理流:
Apps (with fluentd/fluent-bit) -> broker (kafka) -> fluentd cluster -> elasticsearch -> kibana 其中提到的 fluent-bit 是一个极简版的 fluentd,专门用作日志的收集和转发, 可以在应用结点上取代 fluentd 收集日志,满足极端的资源要求。
通过上述描述,你也许会觉得和 ELK 中的 Logstash 高度相似。事实上也确实如此,你完全可以用 fluentd 来替换掉 ELK 中的 Logstash。
有两篇文章对这两个工具做了很好的对比:
概括一下的话,有以下区别:
2017 年 12 月的时候,fluentd 发布了 v1.0 版本,也就是 td-agent v3 版。
从 gem 安装和从 rpm、yum 安装的名字不一样,连配置文件的路径都不一样,需要记住的是:
td-agent 和 fluentd 是同一个软件,区别在于 td-agent 更注重于稳定性,在更新上会稍晚于 fluentd,而且依赖的一些库也会有不同(如 jemalloc),更适用于用于生产环境。
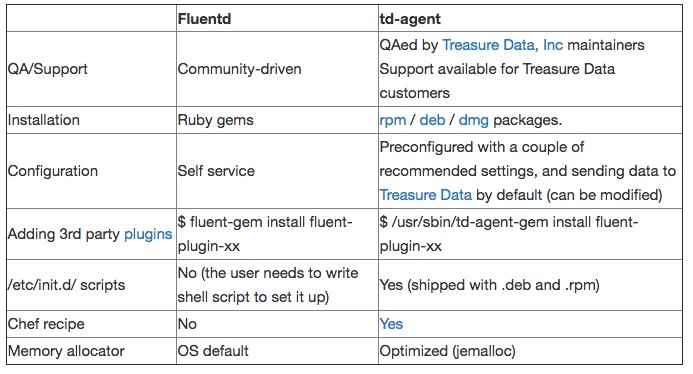
详细可参见官方文档。
以 CentOS 为例:
# 安装$ curl -L https://toolbelt.treasuredata.com/sh/install-redhat-td-agent3.sh | sh # 通过 systemd 启动$ sudo systemctl start td-agent.service$ sudo systemctl status td-agent.service # 或者也可以手动启动$ /etc/init.d/td-agent start$ /etc/init.d/td-agent stop$ /etc/init.d/td-agent restart$ /etc/init.d/td-agent status # 从 rpm 安装的话,# 比如要使用下例的 mongo,需要安装# $ sudo td-agent-gem install fluent-plugin-mongo$ sudo td-agent-gem <PLUGIN_NAME> # 从 gem 安装的话$ sudo gem install <PLUGIN_NAME> 分为两种情况:
你可以在配置文件里使用 @include 来切分你的配置文件,include 支持多种写法:
# 绝对路径include /path/to/config.conf# 相对路径@include conf.d/*.conf# 甚至 URL@include http://example.com/fluent.conf 在配置文件里你需要为很多参数赋值,这些值必须使用 fluentd 支持的数据格式,有下列这些:
string:字符串,最常见的格式,详细支持语法见文档1;integer:整数float:浮点数;size 大小,仅支持整数 time:时间,也只支持整数; array:按照 JSON array 解析;hash:按照 JSON object 解析。配置文件的核心是各种命令块(directives),每一种命令都是为了完成某种处理,命令与命令之间还可以组成串联关系,以 pipline 的形式流式的处理和分发日志。
命令的主要组成部分有:
最常见的方式就是 source 收集日志,然后由串联的 filter 做流式的处理,最后交给 match 进行分发。match 是日志流程的终点,一旦匹配了某一个 match,就不会再继续往下匹配了。
同时你还可以用 label 将任务分组,用 error 处理异常,用 system 修改运行参数。
不同的命令中,都可以通过 @type 指定想要使用的插件名字,而且还可以传入各式各样的插件参数, 由丰富的插件提供强大的功能,下面是详细一些的说明。(关于参数的说明在下面一章。)
source 是 fluentd 的一切数据的来源,每一个 source 内都包含一个输入模块,比如原生集成的包含 http 和 forward 两个模块,分别用来接收 HTTP 请求和 TCP 请求:
# Receive events from 24224/tcp# This is used by log forwarding and the fluent-cat command<source> @type forward port 24224</source> # http://this.host:9880/myapp.access?json={"event":"data"}<source> @type http port 9880</source> 当然,除了这两个外,fluentd 还有大量的支持各种协议或方式的 source 插件,比如最常用的 tail 就可以帮你追踪文件。
每一个具体的插件都包含其特有的参数,比如上例中 port 就是一个参数,当你要使用一个 source 插件的时候,注意看看有哪些参数是需要配置的,然后将其写到 source directive 内。
source dirctive 在获取到输入后,会向 fluent 的路由抛出一个事件,这个事件包含三个要素:
那上例代码中的第二个 source 举例,当我们发起一个 http://this.host:9880/myapp.access?json={"event":"data"} 的请求时,这个 source 会抛出:
# generated by http://this.host:9880/myapp.access?json={"event":"data"}tag: myapp.accesstime: (current time)record: {"event":"data"} 关于如何编写一个输入插件,可以参考文档4。
match 用来指定动作,通过 tag 匹配 source,然后执行指定的命令来分发日志,最常见的用法就是将 source 收集的日志转存到数据库。
# http://this.host:9880/myapp.access?json={"event":"data"}<source> @type http port 9880</source> # 将标记为 myapp.access 的日志转存到文件<match myapp.access> @type file path /var/log/fluent/access</match> 上例中的 myapp.access 就是 tag,tag 有好几种匹配模式:
*:匹配任意一个 tag;**:匹配任意数量个 tag;a b:匹配 a 或 b;{X,Y,Z}:匹配 X, Y, Z 中的一个。比如我可以写成这样:
<match a.*><match **><match a.{b,c}><match a.* b.*> match 是从上往下依次匹配的,一旦一个日志流被匹配上,就不会再继续匹配剩下的 match 了。 所以如果有 <match **> 这样的全匹配,一定要放到配置文件的最后。
用法和 source 几乎一模一样,不过 source 是抛出事件,match 是接收并处理事件。你同样可以找到大量的各式各样的输出插件,也可以参考文档5自己写一个。
而且 match 不仅仅用来处理输出,还可以对日志事件进行一些处理后重新抛出,当成一个新的事件从新走一遍流程,比如可以用 rewrite_tag_filter 插件为日志流重新打上 tag,实现通过正则来对日志进行分流的需求:
<match app> # 捕获被打上了 app tag 的日志 ...</match> <match cp> # 捕获被打上了 cp tag 的日志 ...</match> <match **> # https://docs.fluentd.org/v0.12/articles/out_rewrite_tag_filter # 被打上 tag 的日志会被从头处理,从而被上面的 match 捕获,实现了日志的分流 @type rewrite_tag_filter <rule> key log # 指定要处理的 field pattern ^.*\ c\.p\.\ .* # 匹配条件 tag cp # 打上 tag `cp` </rule> <rule> key log pattern ^.* tag app # 其余日志打上 tag `app` </rule></match> filter 和 match 的语法几乎完全一样,但是 filter 可以串联成 pipeline,对数据进行串行处理,最终再交给 match 输出。
# http://this.host:9880/myapp.access?json={"event":"data"}<source> @type http port 9880</source> <filter myapp.access> @type record_transformer <record> host_param "#{Socket.gethostname}" </record></filter> <match myapp.access> @type file path /var/log/fluent/access</match> 这个例子里,filter 获取数据后,调用原生的 @type record_transformer 插件,在事件的 record 里插入了新的字段 host_param,然后再交给 match 输出。
你可以参考文档6来学习如何编写自定义的 filter。
fluentd 的相关设置,可以在启动时设置,也可以在配置文件里设置,包含:
log_levelsuppress_repeated_stacktraceemit_error_log_intervalsuppress_config_dumpwithout_sourceFluentd 有一个非常活跃社区,提供了大量的插件,你可以在这里看到大多数常见插件的列表:List of All Plugins。
Fluentd 支持 7 种类型的插件:
不同的插件都可以设定不同的参数,拿最简单的 forward 举个例子:
<source> @type http port 9880</source> 其中 @type、port 都是参数,一个指明了插件的名字,另一个指明了监听的端口。
fluentd 里有两种类型的参数:
@ 开头的都是默认参数;fluentd 里只有四个默认参数:
@type:用于指定插件类型;@id:指定插件 id,在输出监控信息的时候有用;@label:指定分组标签,可以对日志流做批处理;@log_level:为每一组命令设定日志级别。label
label 用于将任务进行分组,方便复杂任务的管理。
你可以在 source 里指定 @label @<LABEL_NAME>, 这个 source 所触发的事件就会被发送给指定的 label 所包含的任务, 而不会被后续的其他任务获取到。
需要注意的是,label 一旦被声明了,就必须在后面被用到,否则会报错。
看个例子:
<source> @type forward</source> <source> # 这个任务指定了 label 为 @SYSTEM # 会被发送给 <label @SYSTEM> # 而不会被发送给下面紧跟的 filter 和 match @type tail @label @SYSTEM</source> <filter access.**> @type record_transformer <record> # ... </record></filter><match **> @type elasticsearch # ...</match> <label @SYSTEM> # 将会接收到上面 @type tail 的 source event <filter var.log.middleware.**> @type grep # ... </filter> <match **> @type s3 # ... </match></label> error
用来接收插件通过调用 emit_error_event API 抛出的异常,使用方法和 label 一样,通过设定 <label @ERROR> 就可以接收到相关的异常。
log_level
官方文档
目前支持的日志级别参数值有:
fatalerrorwarninfodebugtrace从上往下依次递减,当你指定了一个级别后,会捕获大于等于该级别的所有日志。
比如如果你指定 @log_level info,就会获取到 info, warn, error, fatal 级别的日志。
除了默认参数外,各个插件还可以定制自己的参数,这个就需要查阅你所用插件的文档页面了。
拿 tail 举个例子,我们可以查阅 文档, 可以看到它有 tag, path, exclude_path, ... 等一系列的参数,比如其中 tag 就可以为日志流打上供 match 使用的 tag。
内容来源于官方文档:Fluentd High Availability Configuration。
任何消息传递系统,都需要考虑消息递交语义(delivery semantics):
一般来说,我们会根据业务场景,在前两种中选择一种,第三种因为性能较差,只适合在小型内部系统上玩玩。
一个日志收集系统由两个角色组成:
fluentd 可以扮演上述两个角色(或者由 fluent-bit 扮演 forwarders 角色),为了保证高可用, 对 aggregators 做多点备份:
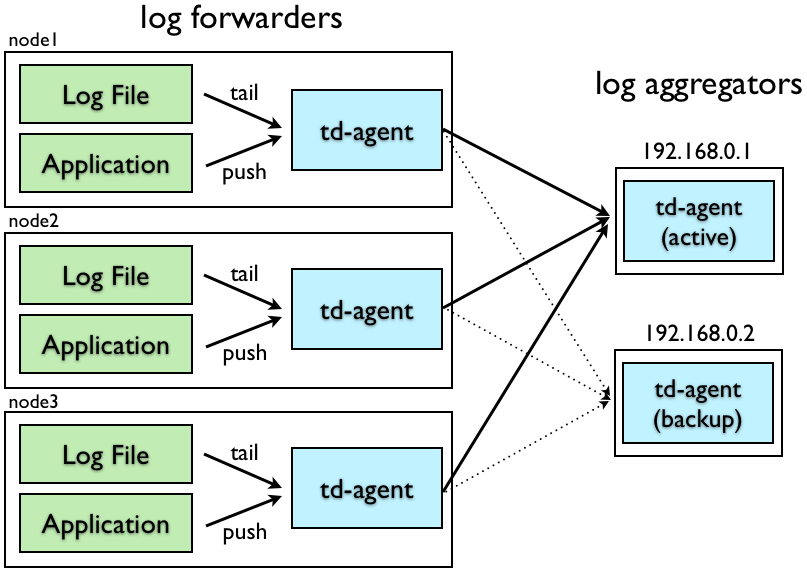
我们需要在 log forwarders 里配置多个 aggregators:
# Log Forwarding<match mytag.**> @type forward # 主 aggregator <server> host 192.168.0.1 port 24224 </server> # 备用 aggregators <server> host 192.168.0.2 port 24224 standby # 声明为备用 </server> # 所有的日志流都会存入磁盘,定期 flush 到 aggregators # 较长的 flush 可以减少 CPU <buffer> flush_interval 60s </buffer></match> Forwarder 会把所有数据存放在 buffer 中,假如你在 match 中配置了 buffer_type file,则会将数据都存放在磁盘中,然后按照 flush_interval 定期将数据发送到 aggregator。
但是,如果 forwarder 进程在将数据写入 buffer 前死掉了,或者存放 buffer 的磁盘坏掉了,就会导致数据丢失。
插件监控
fluentd 内置了一个 HTTP 接口,可以用来获取插件信息,只需要在配置文件里加上:
<source> @type monitor_agent bind 0.0.0.0 port 24220</source> 然后访问:http://localhost:24220/api/plugins.json 就可以拿到插件的信息。
一般来说,fluentd 单节点的吞吐量大概是 10w/sec 左右。
要想提高性能的话,可以在输出端(match)指定 num_threads 来提高并发,在输入端安装 fluent-plugin-multiprocess 插件来提高 CPU 的利用率(Ruby 也有 GIL 问题)。
Fluentd v0.14.12 has been released Multiprocess Input Plugin
fluentd 的 multiprocess 插件非常的鸡肋,只是帮你多启动几个 fluentd 进程,然后每个进程执行自己的配置文件。这个你使用进程管理器(如 supervisor 或 systemd)都能做到。
后来又引入了 multi worker 的参数,但是简单看了下后发现需要插件做适配,而我并没有精力去一个个的排查插件的兼容性,所以也就不考虑了。
为了提高 fluentd 的吞吐量,你有几个办法:
我采用了最后一种方法,使用 haproxy 分发 tcp 到后端的 fluentd,写了一个 docker-compose 文件,开箱即用:
https://github.com/Laisky/HelloWorld/tree/master/docker/docker_log/multi-process
不过在做拆分的时候,要考虑到当前的处理流程是否是无状态的,比如两个典型的场景:
其中多行 合并 就是有状态的,不能很好的进行并行。而日志解析是无状态的,可以根据需求开任意多的进程来处理。为了分担压力,建议将 fluentd 的处理拆为几个不同的步骤,其中第一个步骤仅进行多行合并等有状态的请求,然后第二层再并行的进行较重的解析等操作,最大程度的提高 fluentd 集群的吞吐量。
比如我当前生产环节的 fluentd 集群已经被玩成了这样:

一个监听 Nginx 日志的例子:
<source> @type tail @id nginx-access @label @nginx path /var/log/nginx/access.log pos_file /var/lib/fluentd/nginx-access.log.posg tag nginx.access format /^(?<remote>[^ ]*) (?<host>[^ ]*) \[(?<time>[^\]]*)\] (?<code>[^ ]*) "(?<method>\S+)(?: +(?<path>[^\"]*) +\S*)?" (?<size>[^ ]*)(?: "(?<referer>[^\"]*)" "(?<agent>[^\"]*)")?$/ time_format %d/%b/%Y:%H:%M:%S %z</source><source> @type tail @id nginx-error @label @nginx path /var/log/nginx/error.log pos_file /var/lib/fluentd/nginx-error.log.posg tag nginx.error format /^(?<time>\d{4}/\d{2}/\d{2} \d{2}:\d{2}:\d{2}) \[(?<log_level>\w+)\] (?<pid>\d+).(?<tid>\d+): (?<message>.*)$/</source><label @nginx> <match nginx.access> @type mongo database nginx collection access host 10.47.12.119 port 27016 time_key time flush_interval 10s </match> <match nginx.error> @type mongo database nginx collection error host 10.47.12.119 port 27016 time_key time flush_interval 10s </match></label>为了匹配,你也需要修改 Nginx 的 log_format 为:
log_format main '$remote_addr $host [$time_local] $status "$request" $body_bytes_sent "$http_referer" "$http_user_agent"'; 如果你在启动 docker 时配置了 --log_driver=fluentd 的话,就可以用 fluentd 来接受 docker 的日志。
但是 docker 默认会按照换行符将日志拆成一条条的 json ,所以你需要合并多行日志,并提取日志信息。 下面是一个例子,拆分成两层,先做合并,再做解析:
# 这一层只做合并,做完后就转发给下一层<filter geely.sit> @type concat timeout_label @NORMAL # concat 需要处理好 timeout flush,否则会丢数据 flush_interval 5s key log stream_identity_key container_id multiline_start_regexp /^\d{4}-\d{2}-\d{2} +\d{2}:\d{2}:\d{2}.\d{3} +\|/</filter> <match **> @type relabel @label @NORMAL</match> <label @NORMAL> <match **.sit> @type copy <store> @type forward send_timeout 30s recover_wait 10s hard_timeout 30s <server> host lb port 24225 </server> </store> </match></label> 第二层做解析,因为上一层拼合的日志包含 \n,所以要用 multiline 来做解析:
<filter geely.sit> @type parser key_name log reserve_data true <parse> @type multiline format_firstline /^\d{4}-\d{2}-\d{2} +\d{2}:\d{2}:\d{2}.\d{3} +\|/ format1 /^(?<time>.{23}) {0,}\| {0,}(?<project>[^ ]+) {0,}\| {0,}(?<level>[^ ]+) {0,}\| {0,}(?<thread>[^\|]+) {0,}\| {0,}(?<class>[^\:]+)\:(?<line>\d+) {0,}- {0,}(?<message>.+)/ keep_time_key true </parse></filter> 一个例子,执行的时候需要把 fluent.conf 挂载到 /fluentd/etc/fluent.conf,才能执行:
FROM fluent/fluentd:v1.1.3 RUN apk add --update --virtual .build-deps \ sudo build-base ruby-dev RUN sudo gem install fluent-plugin-elasticsearch -v 2.8.6 \ && sudo gem install fluent-plugin-concat -v 2.1.0 \ && sudo gem install fluent-plugin-rewrite-tag-filter -v 2.0.2 \ && sudo gem install fluent-plugin-kafka -v 0.6.3 \ && sudo gem install fluent-plugin-cadvisor -v 0.3.1 \ && sudo gem install fluent-plugin-flowcounter -v 1.3 \ && sudo gem install fluent-plugin-ignore-filter -v 2.0.0 \ && sudo gem sources --clear-all \ && apk del .build-deps \ && rm -rf /var/cache/apk/* \ /home/fluent/.gem/ruby/2.3.0/cache/*.gem RUN mkdir -p /data/log/td-agent/buffer/ ENV FLUENTD_CONF="fluent.conf" ENTRYPOINT exec fluentd -c /fluentd/etc/${FLUENTD_CONF} -p /fluentd/plugins $FLUENTD_OPT  技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















