















































软件

产品


目前我们的日志系统收集流为: Filbeat-->Logstash-->Python过滤器--->Kafka--->Consumer--->Kibana。
因为FIlebeat不支持 http 层的output 所以只能依赖Logstash。所以我们决定替换FIlbeat 用Fluentd 的output 到http,减少数据流经过的中间服务。
Fluentd 支持多input和多output,并且插件比filebeat更多。功能更加丰富。
beats/filebeat at master · elastic/beats · GitHub star: 10.4K
GitHub - fluent/fluentd: Fluentd: Unified Logging Layer (project under CNCF) star: 1.7K
https://docs.fluentbit.io/manual/pipeline/outputs/http
https://docs.fluentd.org/
Fluent bit 优点 详见官网: Fluent Bit v1.8 Documentation - Fluent Bit: Official Manual
fluent和fluent bit 都是由Treasure Data创建的,fluent bit 没有fluent的聚合特性。工作原理如下:
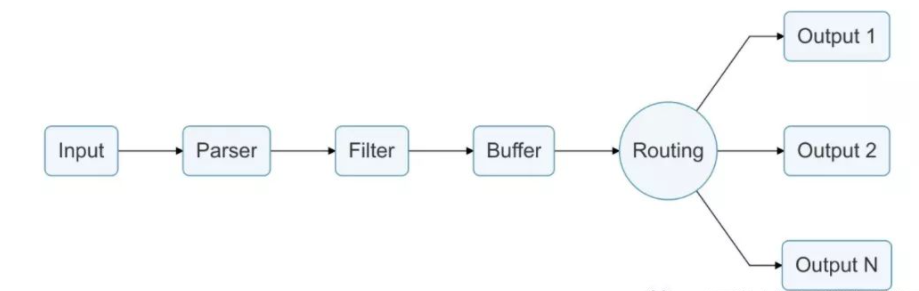
Fluent-bit 是一个简单日志收集工具,上图就是对它 工作流程 的全局概述,它通过输入、转换、过滤、缓冲、路由到输出而完成日志的收集。
对比官网: Fluentd & Fluent Bit - Fluent Bit: Official Manual
| fluentd | fluent-bit | |
| 范围 | 容器/服务器 | 容器/服务器 |
| 语言 | C和Ruby | C |
| 大小 | 约40MB | 约450KB |
| 性能 | 高性能 | 高性能 |
| 依赖关系 | 作为Ruby Gem构建,主要依赖gems | 除了一些安装编译插件(GCC、CMAKE)其它零依赖。 |
| 插件支持 | 超过1000个可用插件 | 大约70个可用插件 |
| 许可 | Apache许可证2.0版 | Apache许可证2.0版 |
所以我们可以用 fluent-bit 做日志收集,如果你不用我们的Python过滤器可以使用fluentd 做聚合操作。
# 修改用户何用户组vim /usr/lib/systemd/system/td-agent.service ## 检测配置文件是否正确的方法/opt/td-agent/embedded/bin/fluentd -c /etc/td-agent/td-agent.conf官网安装链接: https://docs.fluentd.org/installation/install-by-rpm
fluentd以tag值为基准,决定数据的流经哪些处理器
数据的流向为:Events ->source -> parser -> filter -> Matches and Labels (output)
一个event对象通过source标签的input plugin转换为以下结构
Source字段必须加Parse : 详情: Config: Parse Section - Fluentd
(1)http输入流
# http 输入# http://<ip>:9880/myapp.access?json={"event":"data"}<source> @type http port 9000 bind 0.0.0.0</source> # 文件流输出<match file.out> @type file path /home/data/logs/ok/out.log</match> ## 标准输出<match std.logs> @type stdout</match>发送请求:
# 匹配的是match的 std.logs项curl -X POST -d 'json={"name":"knight"}' http://localhost:9000/std.logs # 匹配match的 file.out项curl -X POST -d 'json={"city":"sz"}' http://localhost:9000/file.out 结果如下:
2021-11-15 16:29:08.939551352 +0800 std.logs: {"foo":"bar"}2021-11-15 16:29:22.665292836 +0800 std.logs: {"name":"knight"}match 用来指定动作,通过 tag 匹配 source,然后执行指定的命令来分发日志,最常见的用法就是将 source 收集的日志转存到中间件服务。
*:匹配任意一个 tag;**:匹配任意数量个 tag;a b:匹配 a 或 b;{X,Y,Z}:匹配 X, Y, Z 中的一个。比如我们可以写成这样:
<match a.*><match **><match a.{b,c}><match a.* b.*>fluentd 按照 match 出现的顺序依次匹配,一旦匹配成功就不会再往下匹配,所以如果你先写了一个 match **,然后后面的所有的 match 都会被忽略。
然后我们使用了 @type file 插件来处理事件,这个插件有一个 path 属性,用来指定输出文件。
用法和 source 几乎一模一样,不过 source 是抛出事件,match 是接收并处理事件。你同样可以找到大量的各式各样的输出插件
filter 和 match 的语法几乎完全一样,但是 filter 可以串联成 pipeline,对数据进行串行处理,最终再交给 match 输出。比如往message字段里加新的东西等等。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















