















































软件

产品


最近在 学习 数字图像处理,在用MATLAB做一些实验的时候,发现了一些非常有用的知识,这篇文章会对这些知识做一个总结,话不多说,干货奉上。
function [out1, out2, out3] = fun( in1, in2, in3 )
if nargin == 1
% operations
elseif nargin == 2
% operations
elseif nargin == 3
% operations
end
if nargout == 1
% 为out1赋值
elseif nargout == 2
% 为out1,out2赋值
elseif nargout == 3
% 为out1,out2,out3赋值
end
end
>> A = [1 2 0;3 1 2;0 0 1];
>> A > 0 % 将所有大于0的数置1,否则置0
ans =
1 1 0
1 1 1
0 0 1
>> (A > 1) .* A % 保留所有大于1的数,其他置0
ans =
0 2 0
3 0 2
0 0 0
>> A = [1 2 0;3 1 2;0 0 1];
>> fliplr(A) % 左右镜像
ans =
0 2 1
2 1 3
1 0 0
>> imrotate(A,90) % 逆时针旋转90度,若不是90的倍数,矩阵大小会改变
ans =
0 2 1
2 1 0
1 3 0
>> flipud(A) % 上下镜像
ans =
0 0 1
3 1 2
1 2 0
>> A = [1 2 0;3 1 2;0 0 1];
>> [m, n] = size(A); % 得到A的行数和列数
>> r = nextpow2(max(m,n)); % 计算大于m与n且离他们最近的2的幂次数的幂次
>> r = 2 ^ r;
>> B = padarray(A, [r - m r - n], 'post') % 扩充数组,行数扩充r - m, 列数扩充r - n
B =
1 2 0 0
3 1 2 0
0 0 1 0
0 0 0 0
>> A = [1 2 0;3 1 2;0 0 1];
>> [m, n] = size(A); % 得到A的行数和列数
B = padarray(A, [1 1], 'post') % 向最后一行与最后一列扩充1行数据和一列数据,扩充元素为0
B =
1 2 0 0
3 1 2 0
0 0 1 0
0 0 0 0
>> B = padarray(A, [2 1], 'pre', 'replicate') % 向第一行与第一列扩充2行数据和一列数据,扩充元素为复制边界上的数据
B =
1 1 2 0
1 1 2 0
1 1 2 0
3 3 1 2
0 0 0 1
>> B = padarray(A, [1 2], 'both', 'symmetric') % 向所有方向扩充数据,列扩充1列,行扩充2行,扩充元素为镜像边界上的数据
B =
2 1 1 2 0 0 2
2 1 1 2 0 0 2
1 3 3 1 2 2 1
0 0 0 0 1 1 0
0 0 0 0 1 1 0
>> A = diag([1 1 1]) % 生成对角阵
A =
1 0 0
0 1 0
0 0 1
>> sparse(A) % 将A按稀疏矩阵的格式存储
ans =
(1,1) 1
(2,2) 1
(3,3) 1
>> full(ans) % 展开稀疏矩阵
ans =
1 0 0
0 1 0
0 0 1
>> A = [1 2 0;3 1 2;0 0 1];
>> A(:) % 将A的所有元素组织为一个列向量,A(1:end)可以将其组织为行向量
ans =
1
3
0
2
1
0
0
2
1
>> A(1:2:end, :) % 索引从1开始间隔一行的所有行元素,end是最后一行的行号,单个冒号表示全部可索引的列号
ans =
1 2 0
0 0 1
>> ind = logical([1 0 1;0 1 0;1 0 1]); % ind必须为逻辑类型
>> A(ind) % 将所有A中在ind对应位置为1的所有数组织为一个列向量
ans =
1
0
1
0
1
>> ind = [1 4 7]; % 索引第1、4、7个元素,索引号等于ROWs * j + i(i是行号,j是列号,ROWs是行数)
>> A(ind)
ans =
1 2 0
>> A = ones(3,3)
A =
1 1 1
1 1 1
1 1 1
>> co = [1 1;2 3;3 1] % 坐标数组
co =
1 1
2 3
3 1
>> linearIndex = sub2ind([size(A, 1), size(A,2)], co(:,1), co(:,2)) % 返回坐标数组对应的线性索引
linearIndex =
1
8
3
>> A(linearIndex) = 0
A =
0 1 1
1 1 0
0 1 1
>> A = [1 2 0;3 1 2;1 2 0];
>> unique(A) % 返回A中非重复元素
ans =
0
1
2
3
>> unique(A, 'rows') % 以行为单位,返回A中非重复行
ans =
1 2 0
3 1 2
>> [C IA] = unique(A, 'rows') % 以行为单位,返回A中非重复行与其行号
C =
1 2 0
3 1 2
IA =
1
2
>> [C IA] = unique(A, 'rows', 'last') % 重复项保留最后一个重复项,默认保留第一次出现的重复项
C =
1 2 0
3 1 2
IA =
3
2
>> A = [ 1 2 3;4 5 6; 7 8 9];
>> circshift(A, [2 -2]) % A自上向下循环移动2次,自左向右移动2次
ans =
6 4 5
9 7 8
3 1 2
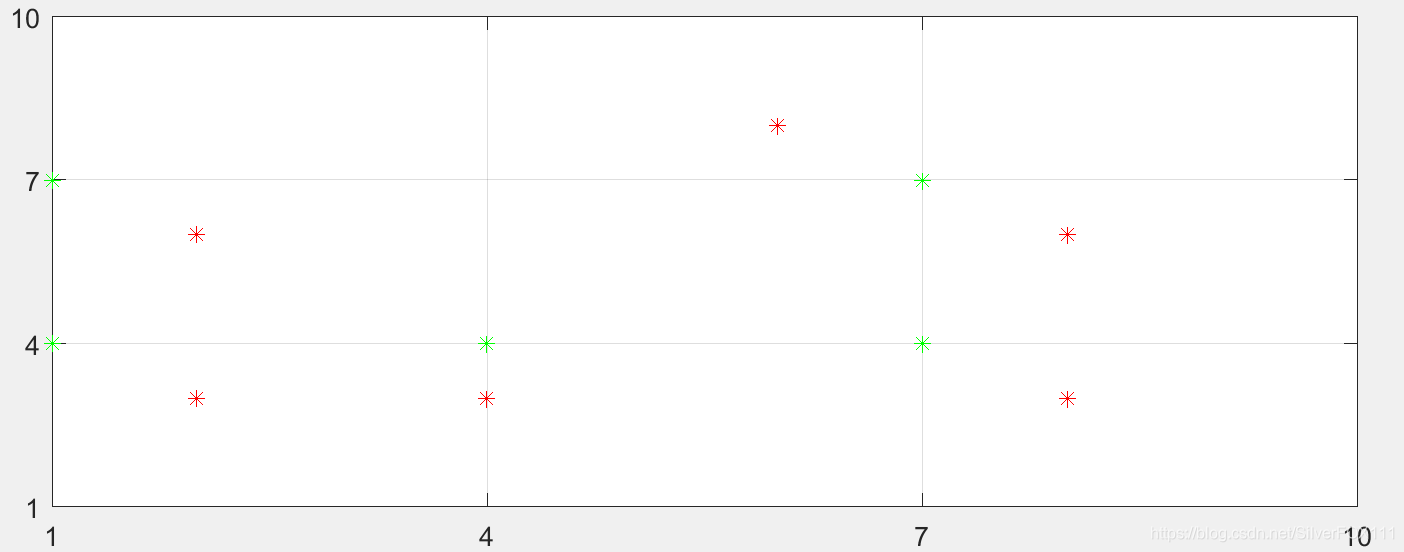
>> A % 红点坐标
A =
2 3
2 6
4 3
6 8
8 3
8 6
>> [C R] = meshgrid(1:3:10,1:3:10);
>> V = [C(1:end);R(1:end)]' % 网格点坐标(包括了绿点的坐标,我们的任务就是从V中取出绿点坐标)
V =
1 1
1 4
1 7
1 10
4 1
4 4
4 7
4 10
7 1
7 4
7 7
7 10
10 1
10 4
10 7
10 10
>> p = size(A,1); % 红点坐标数
>> q = size(V,1); % 网格点坐标数
>> permute(A, [1 3 2]) % 将第二维与第三维交换
ans(:,:,1) =
2
2
4
6
8
8
ans(:,:,2) =
3
6
3
8
3
6
>> t1 = repmat( ans, [1 q 1]) % 扩大第二维,扩大的倍数为网格点坐标数,新增的元素由原列复制
>> % 第三维的两组数据t1(i,j,1)表示红点的x坐标,t1(i,j,2)表示红点的y坐标
t1(:,:,1) =
1 至 14 列
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4
6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6
8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8
8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8
t1(:,:,2) =
3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6
3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8
3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6
>> permute(V, [3 1 2])
ans(:,:,1) =
1 1 1 1 4 4 4 4 7 7 7 7 10 10 10 10
ans(:,:,2) =
1 4 7 10 1 4 7 10 1 4 7 10 1 4 7 10
>> t2 = repmat( ans, [p 1 1]) % 第三维的两组数据t2(i,j,1)表示网格点的x坐标,t2(i,j,2)表示网格点的y坐标
t2(:,:,1) =
1 1 1 1 4 4 4 4 7 7 7 7 10 10 10 10
1 1 1 1 4 4 4 4 7 7 7 7 10 10 10 10
1 1 1 1 4 4 4 4 7 7 7 7 10 10 10 10
1 1 1 1 4 4 4 4 7 7 7 7 10 10 10 10
1 1 1 1 4 4 4 4 7 7 7 7 10 10 10 10
1 1 1 1 4 4 4 4 7 7 7 7 10 10 10 10
t2(:,:,2) =
1 4 7 10 1 4 7 10 1 4 7 10 1 4 7 10
1 4 7 10 1 4 7 10 1 4 7 10 1 4 7 10
1 4 7 10 1 4 7 10 1 4 7 10 1 4 7 10
1 4 7 10 1 4 7 10 1 4 7 10 1 4 7 10
1 4 7 10 1 4 7 10 1 4 7 10 1 4 7 10
1 4 7 10 1 4 7 10 1 4 7 10 1 4 7 10
>> D = sqrt(sum(abs( double(t1) - double(t2) ) .^ 2, 3)) % 计算得到每个红点距离每个网格点的距离,因为红点共p个,网格点共q个,所以距离数组大小为p*q
D =
2.2361 1.4142 4.1231 7.0711 2.8284 2.2361 4.4721 7.2801 5.3852 5.0990 6.4031 8.6023 8.2462 8.0623 8.9443 10.6301
5.0990 2.2361 1.4142 4.1231 5.3852 2.8284 2.2361 4.4721 7.0711 5.3852 5.0990 6.4031 9.4340 8.2462 8.0623 8.9443
3.6056 3.1623 5.0000 7.6158 2.0000 1.0000 4.0000 7.0000 3.6056 3.1623 5.0000 7.6158 6.3246 6.0828 7.2111 9.2195
8.6023 6.4031 5.0990 5.3852 7.2801 4.4721 2.2361 2.8284 7.0711 4.1231 1.4142 2.2361 8.0623 5.6569 4.1231 4.4721
7.2801 7.0711 8.0623 9.8995 4.4721 4.1231 5.6569 8.0623 2.2361 1.4142 4.1231 7.0711 2.8284 2.2361 4.4721 7.2801
8.6023 7.2801 7.0711 8.0623 6.4031 4.4721 4.1231 5.6569 5.0990 2.2361 1.4142 4.1231 5.3852 2.8284 2.2361 4.4721
>> B = zeros(p, 2);
>> for i = 1:p
% D第i行中最小的数对应着第i个红点距离所有网格点最近的距离
idx = find(D(i,:) == min(D(i,:)), 1);
B(i, :) = V(idx, :);
end
>> B
B =
1 4
1 7
4 4
7 7
7 4
7 7
2020-2-15
>> A = [1 2 0;0 2 1;3 0 2]
A =
1 2 0
0 2 1
3 0 2
>> res = find(A == 0) % 最基本的用法是返回A中符合条件表达式的元素索引,在这句代码中返回A中为0的元素,索引号是线性索引ROWs * j + i(i是行号,j是列号,ROWs是行数)
res =
2
6
7
>> [R, C] = find(A == 0) % 当然也可以返回行列号索引
R =
2
3
1
C =
1
2
3
>> [R, C, res] = find(A); % find的参数如果只是一个数组,函数会默认查找非零元素作为索引结果,这句代码会返回所有非零元素及其行列号
>> res'
ans =
1 3 2 2 1 2
>> [R, C, res] = find((A > 1) .* A); % 我们也可以对上句代码的参数稍作修改,返回所有大于1的所有元素及其行列号
>> R'
ans =
3 1 2 3
>> C'
ans =
1 2 2 3
>> res'
ans =
3 2 2 2
>> ind = find(A ~= 0, 3 ,'last'); % find 查找最后三个非零元素,查找顺序为第一列、第二列、...,find 在不指定last的情况下默认查找前3个数
>> ind'
ans =
5 8 9
>> A = tril(ones(4), -1) % 生成缺少主对角线的左下三角矩阵
A =
0 0 0 0
1 0 0 0
1 1 0 0
1 1 1 0
>> [idx(:,2), idx(:,1)] = find(A) % A 的行列号可以构成这样的序列对
idx =
1 2
1 3
1 4
2 3
2 4
3 4
>> rows = [1 2 3 4]';
>> cols = [1 2 3 4]'; % 4个点 (1,1)(2,2)(3,3)(4,4)
>> t1 = rows(idx) % 4个点可以产生6个距离,idx是13得到的序列对,通过idx作为索引得到t1,对t1做列差每行相当于计算(x2 - x1)
t1 =
1 2
1 3
1 4
2 3
2 4
3 4
>> t2 = cols(idx) % 对t2做列差相当于每行计算(y2 - y1)
t2 =
1 2
1 3
1 4
2 3
2 4
3 4
>> D = sqrt( (t1(:,2) - t1(:,1)).^2 + (t2(:,2) - t2(:,1)).^2 )
D =
1.4142 % (1,1) - (2,2)
2.8284
4.2426 % (1,1) - (4,4)
1.4142 % (2,2) - (3,3)
2.8284
1.4142 % (3,3) - (4,4)
| 索引 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 值 | 0.1 | 0.3 | 0.2 | 0.1 | 0.3 |
| 累计和 | 0.1 | 0.4 | 0.6 | 0.7 | 1 |
累计和在 算法 中概率计算方面有很重要的作用,下面给了一个轮盘赌的实例。
>> f = [0.1 0.3 0.2 0.1 0.3]; % 为数字1,2,3,4,5设置概率
>> c = cumsum(f) % 计算累计和
c =
0.1000 0.4000 0.6000 0.7000 1.0000
>> p = 0.65; % 假设在[0,1]区间随机一个数p
>> idx = find(c <= 0.65, 1, 'last') % 最后一个小与等于p的索引即为轮盘赌的结果
idx =
3
>> A = [1 0 0;0 2 0;0 0 3]
A =
1 0 0
0 2 0
0 0 3
>> [V, r] = eig(A) % 计算A的特征向量V,与特征值r
V =
1 0 0
0 1 0
0 0 1
r =
1 0 0
0 2 0
0 0 3
>> x = [1 1 0 -1 -1]';
>> y = [0 1 1 1 0]';
>> [theta, rho] = cart2pol(x, y) % 笛卡尔坐标->极坐标
theta =
0
0.7854
1.5708
2.3562
3.1416
rho =
1.0000
1.4142
1.0000
1.4142
1.0000
>> [x, y] = pol2cart(theta, rho)
x =
1.0000
1.0000
0.0000
-1.0000
-1.0000
y =
0
1.0000
1.0000
1.0000
0.0000
考虑如下一种扩大 矩阵 的方式,在matlab中,如何不使用循环完成变换。
(123456789)−>(112233112233445566445566778899778899)
147258369 ( 1 2 3 4 5 6 7 8 9 ) ->
114477114477225588225588336699336699 ( 1 1 2 2 3 3 1 1 2 2 3 3 4 4 5 5 6 6 4 4 5 5 6 6 7 7 8 8 9 9 7 7 8 8 9 9 ) ⎝⎛147258369⎠⎞−>⎝⎜⎜⎜⎜⎜⎜⎛114477114477225588225588336699336699⎠⎟⎟⎟⎟⎟⎟⎞
>> m = 3; % 行扩大倍数
>> n = 3; % 列扩大倍数
>> A = [1 2 3;4 5 6;7 8 9]
A =
1 2 3
4 5 6
7 8 9
>> u = 1 : m
u =
1 2 3
>> u = u(ones(m, 1), :)
u =
1 2 3
1 2 3
1 2 3
>> v = 1 : n
v =
1 2 3
>> v = v(ones(n, 1), :)
v =
1 2 3
1 2 3
1 2 3
>> ind = [u(:), v(:)] % 二维索引ind可得到结果
ind =
1 1
1 1
1 1
2 2
2 2
2 2
3 3
3 3
3 3
>> B = A(ind(:,1), ind(:,2))
B =
1 1 1 2 2 2 3 3 3
1 1 1 2 2 2 3 3 3
1 1 1 2 2 2 3 3 3
4 4 4 5 5 5 6 6 6
4 4 4 5 5 5 6 6 6
4 4 4 5 5 5 6 6 6
7 7 7 8 8 8 9 9 9
7 7 7 8 8 8 9 9 9
7 7 7 8 8 8 9 9 9

免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















