















































软件

产品


1.starttime = datestr(now,0);
在实验中可以用来描述当前开始运行时间
描述当前的时间节点,个人感觉比较常用的应该是下面两种: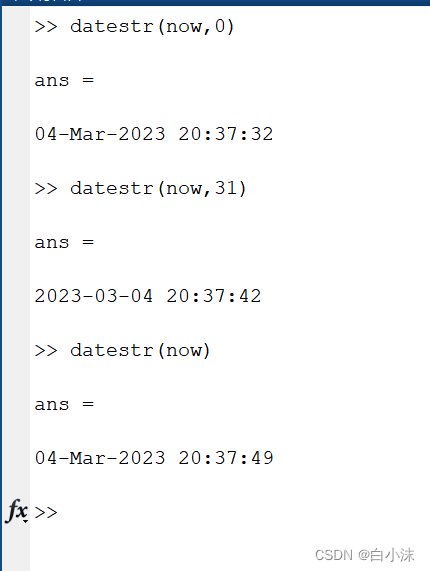
参考文章有:https://blog. csdn .net/Marvelous_Morty/article/details/96477018?spm=1001.2014.3001.5506
2.size的用法
创建一个随机四维数组并返回其大小。
A = rand(2,3,4,5);
sz = size(A)
sz = 1×4
2 3 4 5
仅查询 A 的第二个维度的长度。
szdim2 = size(A,2)
szdim2 = 3
可以通过指定向量维度参数,一次查询多个维度长度。例如,求 A 的第一个维度和第三个维度的长度。
szdim13 = size(A,[1 3])
szdim13 = 1×2
2 4
求 A 的第二个维度至第四个维度的长度。
szdim23 = size(A,2:4)
szdim23 = 1×3
3 4 5
所以这句代码代表,求data中的第一个维度大小
num_data = size(data,1);
参考链接:
https://ww2.mathworks.cn/help/matlab/ref/size.html
3.matlab中RandStream的用法
作用:
RandStream 使用指定的伪随机数生成器算法创建随机数流。
什么是伪随机数?
就是可以通过一个确定的生成器算法生成一些均匀分布的随机数。由于伪随机数是由计算机算法计算出来的,这有一定的规律,不过规律的周期有些长,不太容易观察到,所以可见得到的随机数并不“随机”,只是伪随机的。伪随机数的存在可以保证在可重复性实验中得到的结果是一样的。
什么是随机种子?seed?
我们知道了伪随机数是需要通过一个生成器算法来生成一些伪随机数的,但是再厉害的算法,如果没有一个初始值,它也不可能凭空造出一系列随机数来,我们说的种子就是这个初始值。
random随机数是这样生成的:我们将这套复杂的算法(是叫随机数生成器吧)看成一个黑盒,把我们准备好的种子扔进去,它会返给你两个东西,一个是你想要的随机数,另一个是保证能生成下一个随机数的新的种子,把新的种子放进黑盒,又得到一个新的随机数和一个新的种子,从此在生成随机数的路上越走越远。
也就是说:产生随机种子意味着每次运行实验,产生的随机数都是相同的
原文链接:https://blog.csdn.net/qq_41375609/article/details/99327074
我的理解是:在实验中,我们需要产生大量的伪随机数,“大量”在某种程度上就像“流水”一样,所以说是随机数流。在matlab中,通常用RandStream来创建全局流【均匀分布的随机数流】,其中经常用来生成随机数组的rand、randi、randn 或 randperm 函数就会从这些流中生成随机数,这些随机数独立于全局流或其他流生成的随机数。【疑惑点:类似于父目录和子目录,两者产生的随机数不同?】
参考链接:
https://ww2.mathworks.cn/help/matlab/ref/randstream.html
https://blog.csdn.net/fguknow/article/details/8961866
4.matlab中eps的作用?
eps是一个函数,可以返回某一个数N的最小浮点数精度;是系统进行运算时允许计算机取得最小值;
参考文章:
https://blog.csdn.net/qq_33965676/article/details/96314432?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-96314432-blog-8492655.pc_relevant_multi_platform_whitelistv4&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-96314432-blog-8492655.pc_relevant_multi_platform_whitelistv4&utm_relevant_index=1
5.matlab中的sum用法
参考链接:
https://ww2.mathworks.cn/help/matlab/ref/sum.html
6.matlab中的randperm函数
随机产生一组无序的数
比如:
产生一组4个数的随机序列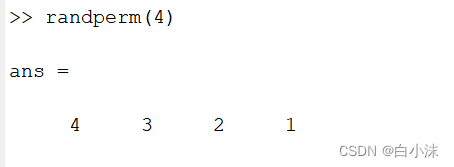
在8个数中,随机产生4个数的随机序列
参考链接:
https://ww2.mathworks.cn/help/matlab/ref/randperm.html
7.matlab中波浪号的作用
大多数代表忽略输出的参数,比如如果我们输出参数有三个,但是我们实际需要的是第二个,那么我们就可以对第一和第三个参数用波浪号表示。
[~,rank,~]=unique(array,'rows');
代表我们忽略了第一和第三个参数,而如果我们不加波浪号的话
如果我们不加波浪号的话:
rank=unique(array,'rows');
8.对于损失函数中含有秩的表达式,发现求导结果不一样,如下图: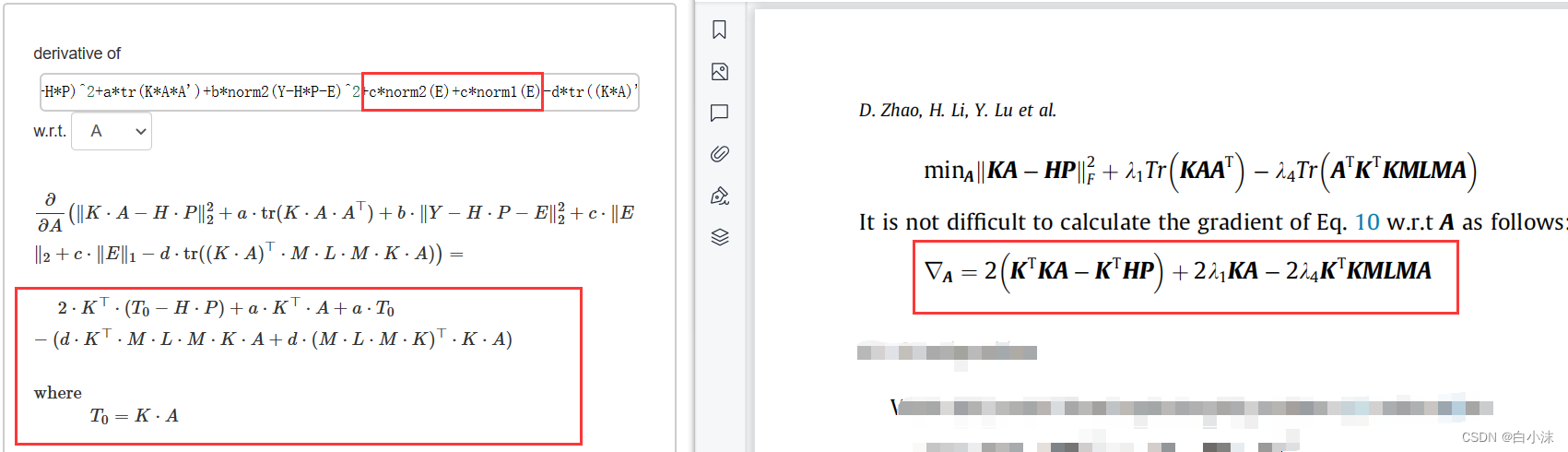
原因,可能是因为其中有一个矩阵是对称矩阵,对称矩阵满足A=A’;在这里引入了HSIC准则,而且结果将最后两项进行了合并,所以KMLMA可能是一个对称矩阵。
9.多标签数据集中的Cardinality和Density
Cardinality:这个一般再论文中都有【别人计算好的】,需要的话可以直接拿来使用就行了
Density:可以用Cardinality/标签的数量,比如1.869/6=0.311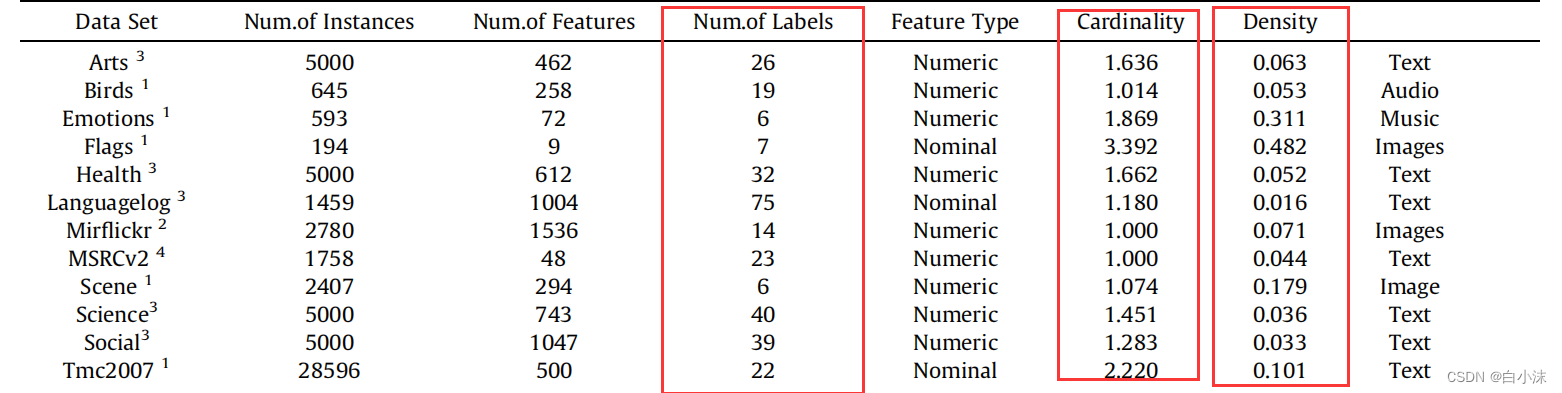
10.对于稀疏矩阵形式可以转换成普通矩阵形式,方法如下:
https://ww2.mathworks.cn/help/matlab/ref/full.html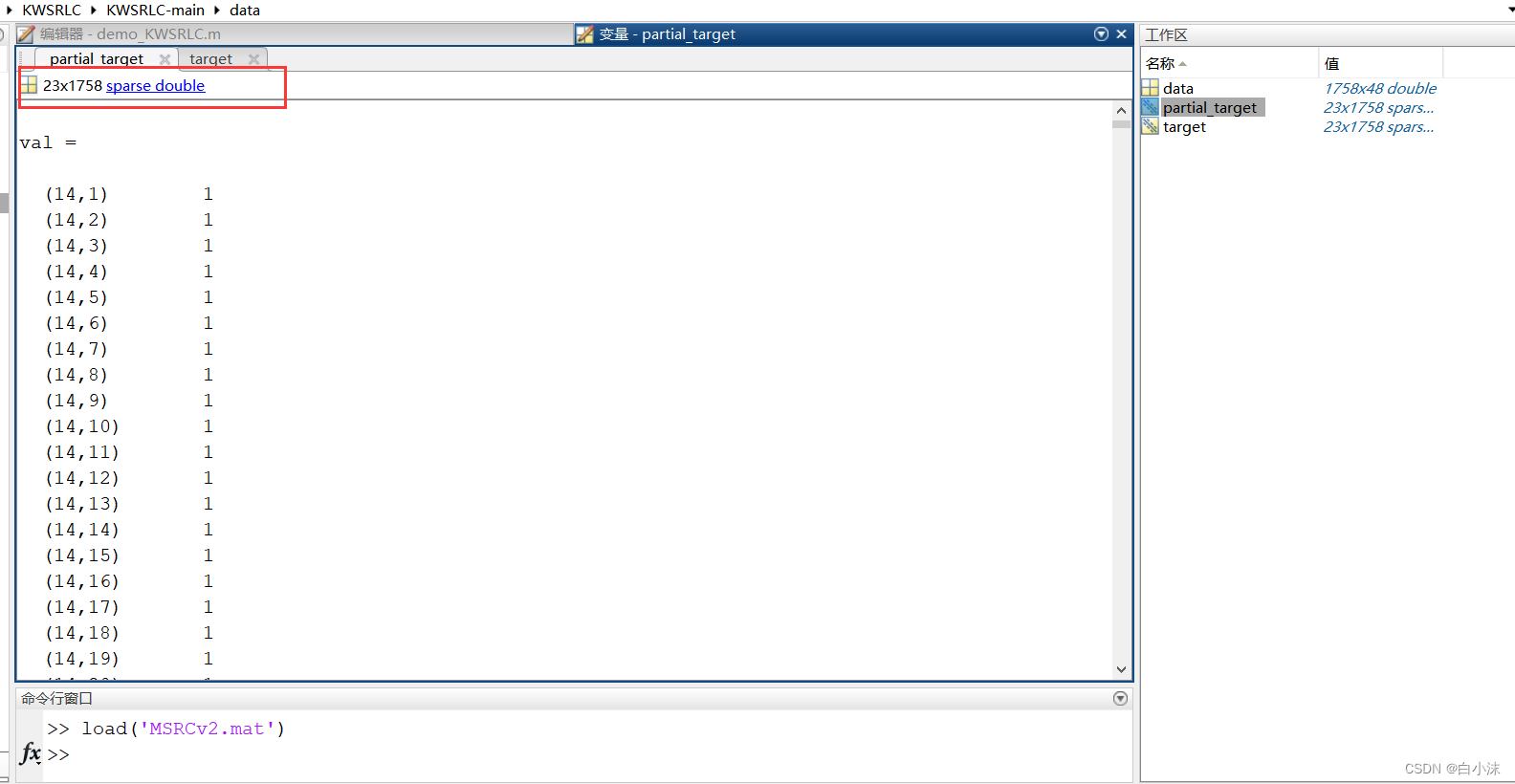
11.matlab中“爆内存"
解决方法:
https://blog.csdn.net/weixin_39613637/article/details/115843371
https://blog.csdn.net/zhenguiqin/article/details/124608468?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-124608468-blog-115843371.pc_relevant_multi_platform_whitelistv3&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-124608468-blog-115843371.pc_relevant_multi_platform_whitelistv3&utm_relevant_index=1
虽然利用这几个方法都没有解决问题,但也不能否认这几个方法不好,也许只是我电脑内存太小了。果然硬件决定一切。 12.如果发现数据集并不适应算法代码,最好的解决方法是在源代码中进行修改,
12.如果发现数据集并不适应算法代码,最好的解决方法是在源代码中进行修改,
比如:遇到数据集没有分开,但是算法要求数据集分开进行运行,这时可以看下代码中对数据的处理是不是一开始就将训练集和测试集合并之后再打乱重新分的,说明一开始的数据集就不是分开的,这时我们就需要把合并数据集的那行代码给注释掉。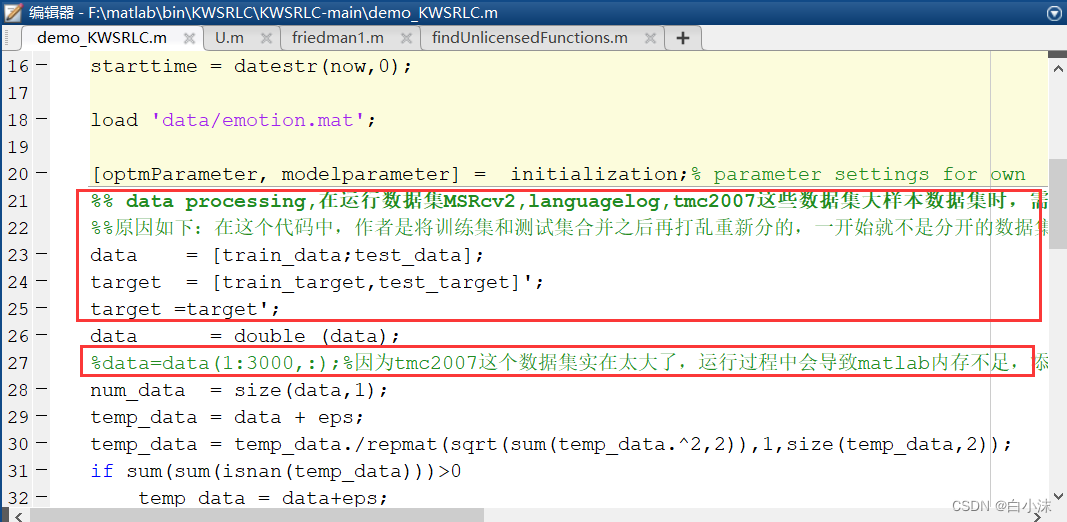
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















