















































软件

产品


目录
(Coordinate VS Heatmap , hrnet VS pfld):

凡我不能创造,我就不能理解。 ——What I cannot create,I don't understand. --费曼
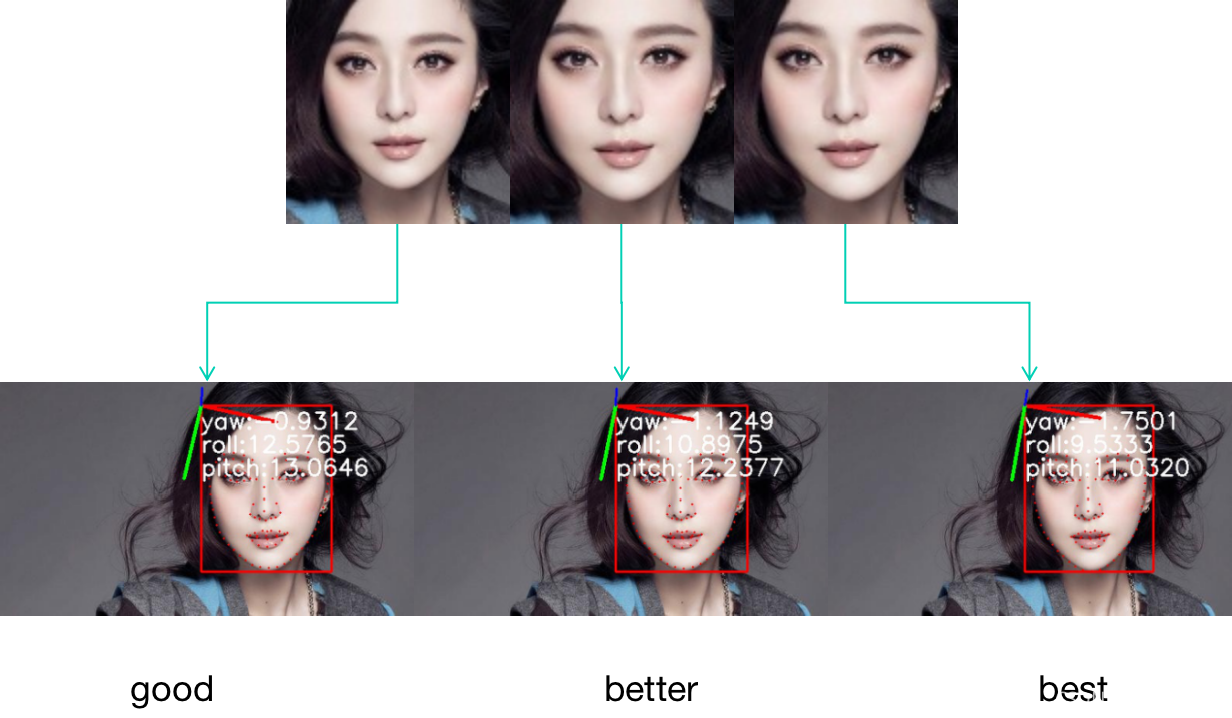
face++,商汤,字节,这些业界标准差异?(人脸106关键点方向)
(1)face++的鼻子中间的关键点更偏高,商汤,字节的更偏低 。
(2)face++的轮廓起点是耳朵前,商汤,字节是耳朵根
(3)唇峰都相对更靠上一些
(4)关键点错误都错的雷同


face++ sdk 商汤sdk 抖音sdk face++服务 我们的


wflw(第一个图): 数量:官方98点,9560张
lapa(第二个图): 数量:官方106点,22175张

感悟,兵不在多而在精,将不在勇而在谋,三千越甲可吞吴,精兵7万,
Garbage in, Garbage Out
关键点回归的Ground Truth 的构建问题,主要有两种思路, Coordinate 和 Heatmap, Coordinate 即直接将关键点坐标作为最后网络需要回归的目标,这种情况下可以直接得到每个坐标点的直接位置信息; Heatmap 即将每一类坐标用一个概率图来表示,对图片中的每个像素位置都给一个概率,表示该点属于对应类别关键 点的概率, 比较自然的是,距离关键点位置越近的像素点的概率越接近 1,距离关键点越远的像素点的概率越接近 0, 具体可以通过相应函数进行模拟,如Gaussian 等。
Coordinate 的优点是参数量少,缺点是效果较差,容易训练学习。
Heatmap 的优点是容易训练,准确性高,缺点是参数量大,随着要检测的点的个数呈爆炸性增长。
(1)heatmap思维,解决不了视觉角度误差 。
(2)人脸检测,半人脸,图像边缘人脸,非端到端的featmap解决不了,端到端的featmap可以解决,需要精心设计 网络结构,centernet思路可以,centerface思路不行 coordinate网络合理设计,有可能解决 ,prelu or leaky relu(fc) , not sigmoid(fc)
(3)泛化性,heatmap >> coordinate
(1)贴合度高
好的关键点能够完美地贴合面部五官,即使在大角度或大动作的视频流中抖动,依然能保持稳定。相反若关键点的贴合能力不够则会大大影响产品的体验和应用效果,比如在美妆应用中唇膏和眼线等美妆特效会贴到真实的五官之外让用户一秒变“如花”。
(2)稳定性强
好的关键点不会抖动而是稳稳地贴在面部。如果关键点的稳定性不强,用户在特效应用中为基于人脸的照片或视频加贴纸的时候,就会造成贴纸抖动。
(3) 跟踪 速度快
好的关键点能实时跟踪每一帧画面,不会造成画面的卡顿、滞后,且人脸快速转头移动时也不会跟丢,相反性能不够好的 SDK 在进行人脸跟踪的时候比较滞后,会引起画面卡顿、占用大量CPU计算资源等情况。
(4)鲁棒性强
好的关键点能在各种极端场景下保持稳定的质量,包括遮挡、大侧脸、运动、恶劣光照等,而鲁棒性差的关键点在大角度的侧脸、遮挡或较差的光照条件下就会丢失或错位。

what's the difference?
小小的眼睛,大大的疑惑
失之毫厘,谬以千里
勿以恶小而为之,勿以善小而不为
一个「像素」引发的血案 小动作能够引发大流行
问题的本质是什么?
动量守恒定律: 物理规律如果具有空间坐标平移不变性则对应地存在一个守恒定律
泛化能力(generalization ability),平移不变性(translation invariant)
Why do deep convolutional networks generalize so poorly to small image transformations?
(1) CNN 丢失平移不变性是下采样(Pooling 和 Stride = 2的Conv)引起的。
(2)Max_Pooling其实对于平移不变性有一定的保持作用。
如何解决:
(1)更多的训练数据
(2)更佳的数据增强方法(Random crop)
(3)增大网络输入分辨率,减少累积误差。
先有鸡,先有蛋?
端到端test 精度 比eval精度低
训练阶段:
(1)基于106关键点groundtruth,生成最小外接矩人脸框(中心点,宽,高)
(2)人脸矩形框中心点x,y,进行10个像素的随机扰动,边长取宽高中最大的边,随机进行(1.05,1.3)的扩大
(3)边界人脸像素补黑边
(4)缩放(112*112)
randshiftx = np.array([random.randint(-10, 10),random.randint(-10, 10)]) randshifty = np.array([random.randint(-10, 10),random.randint(-10, 10)]) xy = np.min(self.landmark, axis=0).astype(np.int32) + randshiftx zz = np.max(self.landmark, axis=0).astype(np.int32) + randshifty wh = zz - xy + 1 center = (xy + wh/2).astype(np.int32) img = cv2.imread(self.path) #print(self.path) randnum = random.uniform(1.05, 1.3) boxsize = int(np.max(wh)* randnum) xy = center - boxsize//2 x1, y1 = xy x2, y2 = xy + boxsize height, width, _ = img.shape dx = max(0, -x1) dy = max(0, -y1) x1 = max(0, x1) y1 = max(0, y1) edx = max(0, x2 - width) edy = max(0, y2 - height) x2 = min(width, x2) y2 = min(height, y2) imgT = img[y1:y2, x1:x2] if (dx > 0 or dy > 0 or edx > 0 or edy > 0): imgT = cv2.copyMakeBorder(imgT, dy, edy, dx, edx, cv2.BORDER_CONSTANT, 0) if imgT.shape[0] == 0 or imgT.shape[1] == 0: imgTT = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR) for x, y in (self.landmark+0.5).astype(np.int32): cv2.circle(imgTT, (x, y), 1, (0, 0, 255)) cv2.imshow('0', imgTT) if cv2.waitKey(0) == 27: exit() imgT = cv2.resize(imgT, (self.image_size, self.image_size))测试阶段:
(1)人脸框上边的边-->下移0.25倍高度
(2)人脸框下边的边-->下移0.05倍高度
(3)取最大宽,高的1.25倍
(4)边界像素判断,不够补黑边
(5)缩放(112*112)
x1, y1, x2, y2 = (box[:4]).astype(np.int32) tt = y2-y1 y1 = int(y1+tt*0.25) y2 = int(y2 + tt*0.05) w = x2 - x1 + 1 h = y2 - y1 + 1 size = int(max([w, h]) * 1.25) cx = x1 + w // 2 cy = y1 + h // 2 x1 = cx - size // 2 x2 = x1 + size y1 = cy - size // 2 y2 = y1 + size dx = max(0, -x1) dy = max(0, -y1) x1 = max(0, x1) y1 = max(0, y1) edx = max(0, x2 - width) edy = max(0, y2 - height) x2 = min(width, x2) y2 = min(height, y2) cropped = img[y1:y2, x1:x2] if (dx > 0 or dy > 0 or edx > 0 or edy > 0): cropped = cv2.copyMakeBorder(cropped, dy, edy, dx, edx, cv2.BORDER_CONSTANT, 0) crop_resized = cv2.resize(cropped, (112, 112))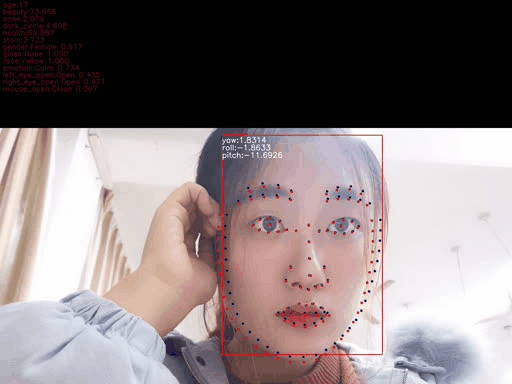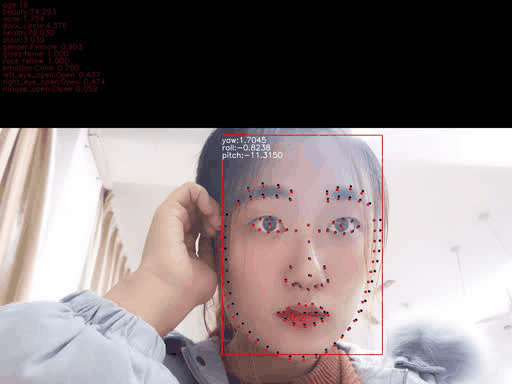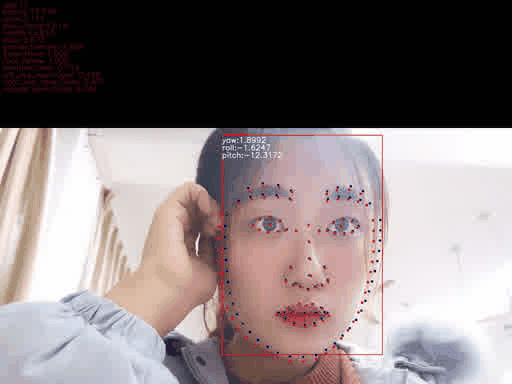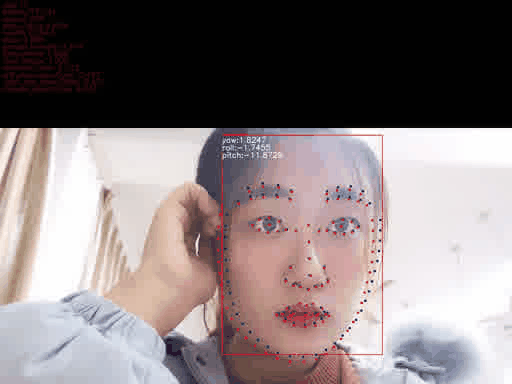
内外分明,内外兼修 轮廓(外),眉毛(内),眼睛(内),鼻子(内),嘴巴(内)
course to fine,增加更多的关键点,增加额头轮廓线,增加眼睛,嘴巴 更细节的关键点(直接训练,或者,贝塞尔插值)



关键点,人脸解析,人脸属性,人脸识别,一个网络多任务学习完成。
机器多,卡多,人多,实验多,大力出奇迹
基于3dmm方法,进行训练数据制造
训练更多的关键点,训练3d关键点


可以得到眼睛,嘴巴是否遮挡
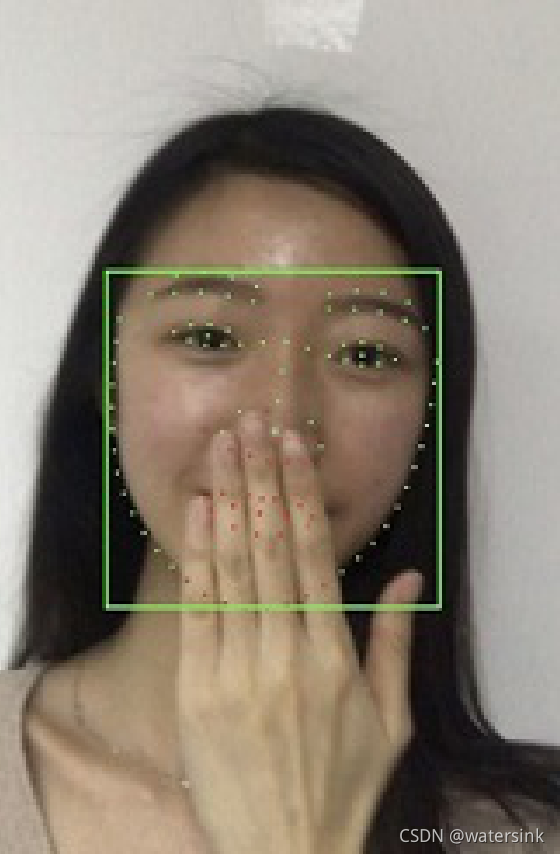
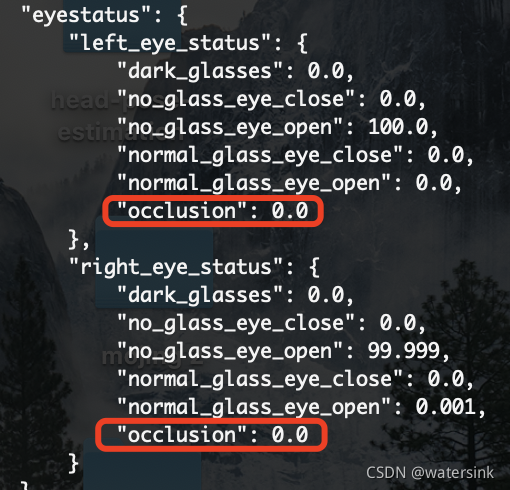
(1)眉毛,短粗,形状不明显,双眉峰,侧脸形变,眉毛头不明显
(2)眼睛,眯眼,内双,斜眼笑
(3)嘴巴遮挡,张开,闭合,抿嘴,嘟嘴,上嘴唇肥大,薄,下嘴唇肥大,薄,香肠嘴
(4)轮廓,披肩发遮挡,垫下巴,双下巴,侧面脸,遮挡

比如在人脸识别系统的中,姿态估计可以辅助进行输入样本的筛选(一般人脸要相对正脸才进行召回和识别) 疲劳驾驶产品中驾驶员的左顾右盼检测
(1)landmark-based,通过2D标定信息来估计3D姿态信息的 算法 ,如先计算人脸的关键点,然后选取一个参考系 (平均正脸的关键点),计算关键点和参考系的变换矩阵,然后通过迭代优化的算法来估计人脸的姿态 (可参考Opencv中的SolvePnP算法) https://github.com/zuoqing1988/ZQCNN/blob/master/SamplesZQCNN/SampleLnet106/ZQ_HeadPoseEstimation.h
(2)landmark-free,通过数据驱动的方式训练一个回归器,由该回归器对输入人脸的块进行一个直接的预测。 (cnn,gcn)
| 算法 | 优点 | 缺点 |
| landmark-based | 1,基于已有的大量关键点标注数据进行训练 2,可获取人脸各部位坐标信息 | 1,平均正脸的选取本身会引入计算误差 2,各类情况的landmark训练样本严重不平衡,长尾效应。 3,2d->3d的优化算法,也会引入计算误差。选取的landmark少,计算误差大,选取的landmark多,计算速度慢 |
| landmark-free | 1,直接回归欧拉角,简洁方便 2,模型设计简单,不需要后处理或者二次算法优化 | 1,需要提供大量含有姿态信息的训练数据,模型训练难收敛。 2,数据标注困难,大多数情况采用2d->3d标注,少数情况可以使用合成数据 |
(1)Dlib68个点中的6个
landmarks_3D = np.float32([ [0.0, 0.0, 0.0], # Nose tip [0.0, -330.0, -65.0], # Chin [-225.0, 170.0, -135.0], # Left eye left corner [225.0, 170.0, -135.0], # Right eye right corner [-150.0, -150.0, -125.0], # Mouth left corner [150.0, -150.0, -125.0], # Mouth right corner ]) / 4.5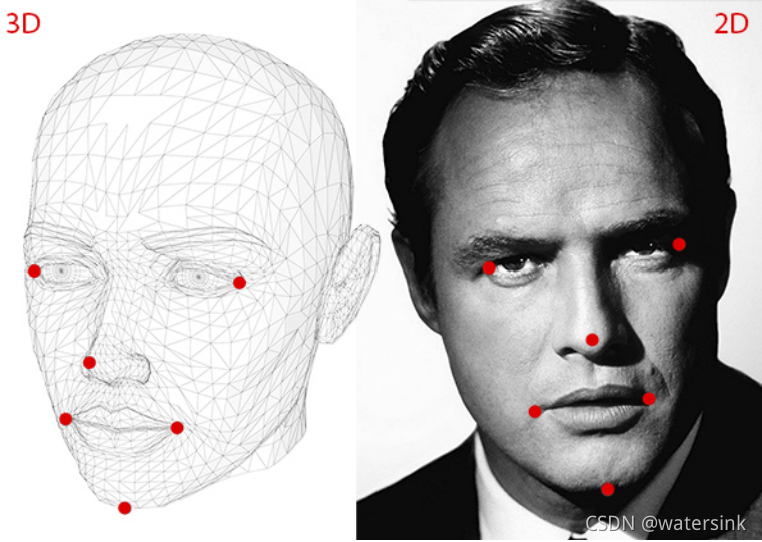
1000张和face++误差: yaw mae :3.4285 roll mae:1.6264 pitch ame:178.1665
(2)Dlib68个点中的68个
landmarks_3D = np.float32([[[-73.393524 -29.801432 -47.667534] [-72.77502 -10.949766 -45.909405] [-70.53364 7.929818 -44.84258 ] [-66.85006 26.07428 -43.141113] [-59.790188 42.56439 -38.6353 ] [-48.368973 56.48108 -30.750622] [-34.1211 67.246994 -18.456453] [-17.87541 75.05689 -3.609035] [ 0.098749 77.06129 0.881698] [ 17.477032 74.758446 -5.181201] [ 32.648968 66.92902 -19.176563] [ 46.372356 56.31139 -30.77057 ] [ 57.34348 42.419125 -37.628628] [ 64.38848 25.45588 -40.88631 ] [ 68.212036 6.990805 -42.28145 ] [ 70.486404 -11.666193 -44.142567] [ 71.375824 -30.36519 -47.140427] [-61.119408 -49.361603 -14.254422] [-51.287586 -58.769794 -7.268147] [-37.8048 -61.996155 -0.442051] [-24.022755 -61.033398 6.606501] [-11.635713 -56.68676 11.967398] [ 12.056636 -57.391033 12.051204] [ 25.106256 -61.902187 7.315098] [ 38.33859 -62.777714 1.022953] [ 51.191006 -59.302345 -5.349435] [ 60.053852 -50.190254 -11.615746] [ 0.65394 -42.19379 13.380835] [ 0.804809 -30.993721 21.150852] [ 0.992204 -19.944595 29.284037] [ 1.226783 -8.414541 36.94806 ] [-14.772472 2.598255 20.132004] [ -7.180239 4.751589 23.536684] [ 0.55592 6.5629 25.944448] [ 8.272499 4.661005 23.695742] [ 15.214351 2.643046 20.858156] [-46.04729 -37.471413 -7.037989] [-37.674686 -42.73051 -3.021217] [-27.883856 -42.711517 -1.353629] [-19.648268 -36.75474 0.111088] [-28.272964 -35.134495 0.147273] [-38.082417 -34.919044 -1.476612] [ 19.265867 -37.032307 0.665746] [ 27.894192 -43.342445 -0.24766 ] [ 37.43753 -43.11082 -1.696435] [ 45.170807 -38.086514 -4.894163] [ 38.196453 -35.532024 -0.282961] [ 28.76499 -35.484287 1.172675] [-28.916267 28.612717 2.24031 ] [-17.533194 22.172188 15.934335] [ -6.68459 19.02905 22.611355] [ 0.381001 20.721119 23.748438] [ 8.375443 19.03546 22.721994] [ 18.876617 22.39411 15.610679] [ 28.794413 28.079924 3.217393] [ 19.057573 36.29825 14.987997] [ 8.956375 39.634575 22.554245] [ 0.381549 40.395645 23.591625] [ -7.428895 39.836407 22.406107] [-18.160633 36.6779 15.121907] [-24.37749 28.67777 4.785684] [ -6.897633 25.475977 20.893742] [ 0.340663 26.014269 22.220478] [ 8.444722 25.326199 21.02552 ] [ 24.474474 28.323008 5.712776] [ 8.449166 30.596216 20.67149 ] [ 0.205322 31.408737 21.90367 ] [ -7.198266 30.844875 20.328022]] ]) 
1000张和face++误差: yaw mae:7.1058 roll mae:150.4720 pitch ame:20.0818
原因:106点的定义和68点的定义有区别
(3)106点中的14个点,最终方案,效果最佳
landmarks_3D = np.float32([ [6.825897, 6.760612, 4.402142], # LEFT_EYEBROW_LEFT, [1.330353, 7.122144, 6.903745], # LEFT_EYEBROW_RIGHT, [-1.330353, 7.122144, 6.903745], # RIGHT_EYEBROW_LEFT, [-6.825897, 6.760612, 4.402142], # RIGHT_EYEBROW_RIGHT, [5.311432, 5.485328, 3.987654], # LEFT_EYE_LEFT, [1.789930, 5.393625, 4.413414], # LEFT_EYE_RIGHT, [-1.789930, 5.393625, 4.413414], # RIGHT_EYE_LEFT, [-5.311432, 5.485328, 3.987654], # RIGHT_EYE_RIGHT, [2.005628, 1.409845, 6.165652], # NOSE_LEFT, [-2.005628, 1.409845, 6.165652], # NOSE_RIGHT, [2.774015, -2.080775, 5.048531], # MOUTH_LEFT, [-2.774015, -2.080775, 5.048531], # MOUTH_RIGHT, [0.000000, -3.116408, 6.097667], # LOWER_LIP, [0.000000, -7.415691, 4.070434], # CHIN ])

问题:计算欧拉角是选取的关键点数目越多越好吗?
结论:左博的代码是质量最高,最值得借鉴的
1.尽量多的数据
2.添加追踪机制,小范围移动内不做检测
3.对点和检测框都做ROI
各自为伍+形状约束,思考端到端,全图出结果的好处 假设训练图片112*112,那么最大精度就是1个像素,小数点后其余的值,叫做尺度因子。 groudtruth = (原使crop图的106个x,y)/crop图的长宽 网络结构需要双分支,双106*2,一个负责112*112,一个负责尺度因子。 x,y回归值制作,取整((0-1)的label*112)/122,可以L1,L2,KL,soft cross_entrop x,y尺度因子制作,取余((0-1)的label*112)/122,L1,L2
基于sort,deepsort,kalman滤波,匈牙利算法。
人脸检测的准确率 = 人脸检测的准确率 = 0.99
人脸关键点的准确率 = 人脸检测的准确率*人脸关键点的准确率 = 0.99*0.99 = 0.9801
人脸欧拉角的准确率 = 人脸检测的准确率*人脸关键点的准确率*人脸欧拉角的准确率 = 0.99*0.99*0.99 = 0.9702
人脸属性的准确率 = 人脸检测的准确率*人脸关键点的准确率*人脸属性的准确率 = 0.99*0.99*0.99 = 0.9702
古今之成大事业、大学问者,必经过三种之境界: “昨夜西风凋碧树,独上高楼,望尽天涯路。”此第一境也;(git clone)
“衣带渐宽终不悔,为伊消得人憔悴”,此第二境也;(选择性clone(star,fork),加入自己思想,完善)
“众里寻她千百度,蓦然回首,那人正在灯火阑珊处”,此第三境也。(返璞归真,大智若愚,工业标准,ssd vs mtcnn,关键点的速度限度,书本上没有,靠经验堆)
王国维《人间词话》

(1)紧跟前沿 掌握足够多的输入。
(2)注重学习 & 不断实践 有属于自己的思考和严谨的产出。
(3)重视基础知识 & 多做总结 理解清楚,事半功倍。
(4)体系实践 三人行必有我师,向身边的人学习。

https://github.com/hpc203/10kinds-light-face-detector-align-recognition https://github.com/zuoqing1988/ZQCNN https://github.com/ShiqiYu/libfacedetection https://github.com/OAID/TengineKit https://github.com/olucurious/Awesome-ARKit https://github.com/google/mediapipe https://github.com/yinguobing/head-pose-estimation Head Pose Estimation using OpenCV and Dlib | LearnOpenCV # https://github.com/yuenshome/yuenshome.github.io/issues/9 https://github.com/qaz734913414/Ncnn_FaceTrack/blob/master/LandmarkTracking.h https://github.com/xiangdeyizhang/FaceTrack_ncnn_HyperFT https://github.com/deepinsight/insightface https://data.vision.ee.ethz.ch/cvl/rrothe/imdb-wiki/ https://github.com/AI-performance/embedded-ai.bench https://zhuanlan.zhihu.com/p/48347016 http://www.pris.net.cn/introduction/teacher/dengweihong https://github.com/gjain307/Skin-Disease-Detection.git https://github.com/microsoft/onnxruntime/tree/v1.0.0/onnxruntime/python/tools/quantization
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















