















































软件

产品


MATLAB车牌识别系统
二、 设计原理
该系统主要分为四个部分,分别是图像预处理、车牌定位、车牌字符分割、字符识别。
如下图1-1所示:
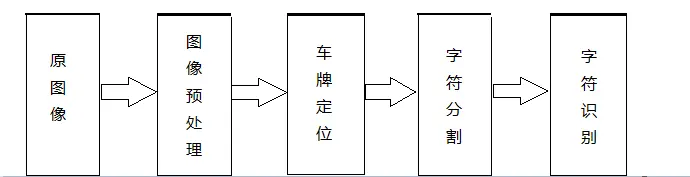
图1-1 牌照识别系统原理图
三、 车牌识别系统设计与实现
3.1提出总体设计方案
整个系统中对于车牌的位置的定位和车牌号码的字符识别最为重要。其中的车牌定位又分为图像图像灰度化、图像边缘检测和图像腐蚀;另外车牌号码的识别又由车牌号码的分割和单号码模块匹配结合。该系统的主要目的是将车牌部分通过对图像预处理后从原始图像中分离出来,再将车牌内车牌号的字符单个分离出来,再对单个字符进行模板匹配识别,所以车牌定位分离、字符定位、分离的结果在体统的识别过程中显得特别重要。
在对车牌定位之前,应对原始图像进行一些预处理前,为减少对后续定位、识别的影响,为图像具有较大的对比度和较大的清晰度,更好地运用于牌照分割和字符识别,应对原始图像进行一些处理。因为对于原始图像的来源主要是摄像机直接拍摄处理道路上行驶的车辆,加上车牌照本身的整洁程度、自然光的照射条件、摄像机镜头的光学畸变产生的噪声、拍摄时摄像机与车牌照的距离、车辆行驶的速度以及摄像头的拍摄角度,在这些负面的影响下有可能造成车牌照的图像清晰度不够、角度不正、等严重损坏影响对车牌字符识别的准确度。导致对于车牌的定位和字符分割的结果不准确。
3.2图像预处理
通常使用摄像头拍摄到的车辆会存在大量的噪省,所以在处理车牌照图像识别前要先对图像做一些预先的处理。由摄像机等所采集到的含车辆的图片的预处理是指将采集到的含车辆车牌的原图像亮度做一定的调整和去除图像本身的噪声处理,让图像变得更清晰,并保留图像本身的纹理构造和增强图像的颜色信息,尽可能减少对后面将要识别的区域纹理和颜色信息的噪声的影响,让后面的车牌定位的准确性有所提高
3.2.1图像灰度化
一张灰度图指的是它只包含了它本身固有的亮度而不含有它的色彩信息,像八九十年代前的黑白照片就是一张亮度连续变化的灰度图。把一张彩色的图像转为灰阶模式就是灰度化处理。一张彩色的图像都是由R、G、B三原色组成,图像的色彩信息会随着三原色的改变而改变。在计算机上,R、G、B的多少决定了这张图像的颜色,通常,R、G、B它们都各有256级亮度,用数字0到255组成。灰度化就是让原彩色图像的R、G、B相等的过程。
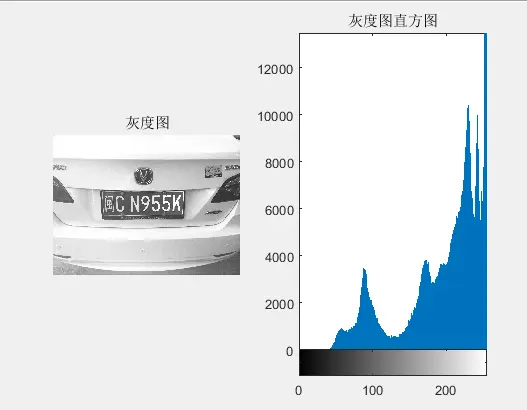
图2-1 车牌灰度图及灰度直方图
3.2.2图像边缘检测
定位和分割的是识别系统技术主要板块,它的主要作用是图像经过预处理后得到灰度图像的照片后,以确定该图像中包含所要字符的特定位置。由于该点是原来的图像象是非常典型的一个子区域的,主要是周围的矩形横向确切的较高水平,相对原始图像也更侧重于的中心位置,并且灰度区域是完全不同的,所以边缘形检测是一个简单方案对于灰度图像检测图像分割。
处理效果图如下图3-2:

图3-2 车牌边缘检测图
3.3车牌定位
3.3.1灰度图像腐蚀
图像腐蚀是一种形态学运算,它仅对二值图并且根据数学形态学集合方式而形成的到目前已经被广泛应用的数字图像处理的方法。图像腐蚀它的根本依据是:为了得到和衡量灰度图像中所要的对应物体形状,而用结构元素对灰度图进行勘测,找到图像中可以容纳下这个结构元素的位置以达到目的。图像腐蚀可以消除图像中小的而且对没有意义的“污点”,如果“污点”之间有着细小的接通,则可以选择较大的结构元素,把它们一起腐蚀掉。如果结构元素的值都是正的,则得到的图像会比输出图像亮。
腐蚀效果图如下图3-3:
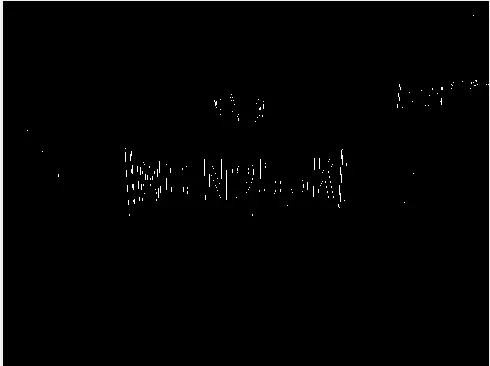
图3-3 灰度图腐蚀后效果图
·
3.3.2平滑图像、移除小对象
为了保存并呈现出图像中有意义的信息且要消除噪声干扰,我们通常对图像采用平滑处理。
效果如下图3-4:
图3-4 平滑、移除小对象效果图
3.3.3牌照区域的分割
到这里要将车牌照从原图像分离出来,这里运用了彩色分离的方法。一般车牌照颜色会区别于车身或者其他颜色,所以这里我们就可以设定一个颜色以及设定一个阈值范围,再经过平滑的区域上再进行扫描车牌颜色所对应的灰度范围,来得到车牌的最终位置。
最终得到的车牌:

图3-5 定位到的车牌
得到了这张带有噪声的目标图像后,我们还要对图像进行再处理,这里我们最经常用到的方法是对图像二值化,再滤波。首先设置一个阈值,然后用这个阈值再讲图像划分为两个部分,再经过平均线性滤波的方法对图像像素进行滤波,再把这个像素值赋予整张图像作为其同意像素。
3.4字符分割
字符分割、归一化
因为车牌本身字符之间的间隔较大,所以我们可以设置一个阈值,在对车牌进行扫描,如果存在有连续大于阈值的空白块,则将在这里从上到下进行分割。
对于分割出来的字符,我们还需要对其进行统一规格的设置,这有利于后面对字符的识别。
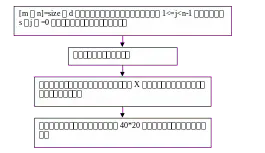
图3-6 字符分割与归一化流程图
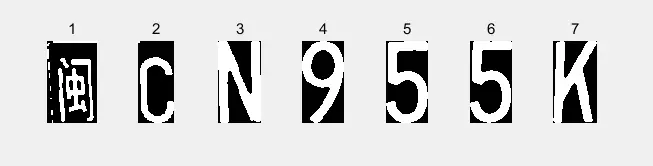
3.5字符的识别
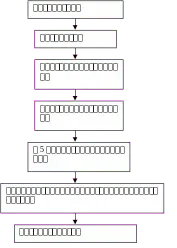
图3-8 字符识别流程图
字符识别的准确性直接决定了该系统是否可靠。在之前的研究中最经常被用于字符的识别主要有模板匹配法和神经网络识别法。在这次研究设计中我们采用的是模板匹配法进行识别,该方法是将分割出来的字符样本进行字符归一化处理,使图像大小与原先已经存储在计算机内的标准字符大小一致,再与标准字符进行一一对比,最后结果取差异最小的相对应的标准字符。这种模板匹配的方法相对比较快速、简单。但是对字符图像要求比较高,一旦图像有噪声或者亮度问题其结果就可以能存在差异。神经网络识别法,它是结合神经网络技术,依靠人的经验来取得字符的特征,再利用神经网络的辨别能力来对字符进行识别,这个方法得到的结果会比较准确,但技术要求较高。
对该系统使用的模板匹配的识别方法,它先依次提取需要识别的字符的二值图像上下左右四个点的像素点,想沿着图像中心方向提取周围像素点,计算出每个像素点与标准模板对应该坐标的像素点的相识度,其中相似度最高的标准字符图就作为需要的字符的对应字。也可以计算出原始图像一些特征像素点之间的距离,再计算出标准模板对应特征点的距离,再判断他们距离的差异。取最小差异的标准模板为结果。但是,由于原始字符在可能会由于拍摄的时候角度原因和图像经过处理后,图像像素点距离发生改变。所以,在对标准模板的设计时应根据实际拍摄角度等多做一些相对于的模板,让比较结果更为精确。

图3-9 最终识别显示结果
四、源码
function [d]=main(jpg)
close all
clc
[filename,filepath]=uigetfile('.jpg','输入一个需要识别的车牌图像');
file=strcat(filepath,filename);
I=imread(file);
figure(1),imshow(I);title('原图')
I1=rgb2gray(I);
figure(2),subplot(1,2,1),imshow(I1);title('灰度图');
figure(2),subplot(1,2,2),imhist(I1);title('灰度图直方图');
%I1=medfilt2(I1);
%figure,imshow(I1);title('中值滤波');
I2=edge(I1,'roberts',0.15,'both');
figure(3),imshow(I2);title('robert算子边缘检测')
se=[1;1;1];
I3=imerode(I2,se);
figure(4),imshow(I3);title('腐蚀后图像');
se=strel('rectangle',[25,25]);
I4=imclose(I3,se);
figure(5),imshow(I4);title('平滑图像的轮廓');
I5=bwareaopen(I4,2000);
figure(6),imshow(I5);title('从对象中移除小对象');
[y,x,z]=size(I5);
myI=double(I5);
tic
Blue_y=zeros(y,1);
for i=1:y
for j=1:x
if(myI(i,j,1)==1)
Blue_y(i,1)= Blue_y(i,1)+1;
end
end
end
[temp MaxY]=max(Blue_y);
PY1=MaxY;
while ((Blue_y(PY1,1)>=5)&&(PY1>1))
PY1=PY1-1;
end
PY2=MaxY;
while ((Blue_y(PY2,1)>=5)&&(PY2<y))
PY2=PY2+1;
end
IY=I(PY1:PY2,:,:);
%%%%%% X方向%%%%%%%%%
Blue_x=zeros(1,x);
for j=1:x
for i=PY1:PY2
if(myI(i,j,1)==1)
Blue_x(1,j)= Blue_x(1,j)+1;
end
end
end
PX1=1;
while ((Blue_x(1,PX1)<3)&&(PX1<x))
PX1=PX1+1;
end
PX2=x;
while ((Blue_x(1,PX2)
PX2=PX2-1;
end
PX1=PX1-1;
PX2=PX2+1;
dw=I(PY1:PY2-8,PX1:PX2,:);
t=toc;
%figure(17),subplot(1,2,1),imshow(IY),title('行方向合理区域');
%figure(17),subplot(1,2,2),imshow(dw),title('定位剪切后的彩色车牌图像')
imwrite(dw,'dw.jpg');
[fn,pn,fi]=uigetfile('dw.jpg','输入一个定位裁剪后的车牌图像');
I=imread([pn fn]);
jpg=strcat(filepath,filename);
a=imread('dw.jpg');
b=rgb2gray(a);
imwrite(b,'1.车牌灰度图像.jpg');
%figure(18);subplot(3,2,1),imshow(b),title('1.车牌灰度图像')
g_max=double(max(max(b)));
g_min=double(min(min(b)));
T=round(g_max-(g_max-g_min)/3);
[m,n]=size(b);
d=(double(b)>=T);
imwrite(d,'2.车牌二值图像.jpg');
%figure(18);subplot(3,2,2),imshow(d),title('2.车牌二值图像')
%figure(18),subplot(3,2,3),imshow(d),title('3.均值滤波前')
h=fspecial('average',3);
d=im2bw(round(filter2(h,d)));
imwrite(d,'4.均值滤波后.jpg');
%figure(9),subplot(3,2,4),imshow(d),title('4.均值滤波后')
% se=strel('square',3);
% 'line'/'diamond'/'ball'...
se=eye(2); % eye(n) returns the n-by-n identity matrix 单位矩阵
[m,n]=size(d);
if bwarea(d)/m/n>=0.365
d=imerode(d,se);
elseif bwarea(d)/m/n<=0.235
d=imdilate(d,se);
end
imwrite(d,'5.膨胀或腐蚀处理后.jpg');
%figure(18),subplot(3,2,5),imshow(d),title('5.膨胀或腐蚀处理后')
d=qiege(d);
[m,n]=size(d);
figure,subplot(2,1,1),imshow(d),title(n)
k1=1;k2=1;s=sum(d);j=1;
while j~=n
while s(j)==0
j=j+1;
end
k1=j;
while s(j)~=0 && j<=n-1
j=j+1;
end
k2=j-1;
if k2-k1>=round(n/6.5)
[val,num]=min(sum(d(:,[k1+5:k2-5])));
d(:,k1+num+5)=0;
end
end
%再切割
d=qiege(d);
%切割出7个字符
y1=10;y2=0.25;flag=0;word1=[];
while flag==0
[m,n]=size(d);
left=1;wide=0;
while sum(d(:,wide+1))~=0
wide=wide+1;
end
if wide<y1
d(:,[1:wide])=0;
d=qiege(d);
two_thirds=sum(sum(temp([round(m/3):2*round(m/3)],:)));
if two_thirds/all>y2
flag=1;word1=temp;
end
d(:,[1:wide])=0;d=qiege(d);
end
end
[word2,d]=getword(d);
[word3,d]=getword(d);
[word4,d]=getword(d);
[word5,d]=getword(d);
[word6,d]=getword(d);
[word7,d]=getword(d);
subplot(5,7,1),imshow(word1),title('1');
subplot(5,7,2),imshow(word2),title('2');
subplot(5,7,3),imshow(word3),title('3');
subplot(5,7,4),imshow(word4),title('4');
subplot(5,7,5),imshow(word5),title('5');
subplot(5,7,6),imshow(word6),title('6');
subplot(5,7,7),imshow(word7),title('7');
[m,n]=size(word1);
word1=imresize(word1,[40 20]);
word2=imresize(word2,[40 20]);
word3=imresize(word3,[40 20]);
word4=imresize(word4,[40 20]);
word5=imresize(word5,[40 20]);
word6=imresize(word6,[40 20]);
word7=imresize(word7,[40 20]);
subplot(5,7,15),imshow(word1),title('1');
subplot(5,7,16),imshow(word2),title('2');
subplot(5,7,17),imshow(word3),title('3');
subplot(5,7,18),imshow(word4),title('4');
subplot(5,7,19),imshow(word5),title('5');
subplot(5,7,20),imshow(word6),title('6');
subplot(5,7,21),imshow(word7),title('7');
imwrite(word1,'1.jpg');
imwrite(word2,'2.jpg');
imwrite(word3,'3.jpg');
imwrite(word4,'4.jpg');
imwrite(word5,'5.jpg');
imwrite(word6,'6.jpg');
imwrite(word7,'7.jpg');
liccode=char(['0':'9' 'A':'Z' '闽鲁苏豫']);
SubBw2=zeros(40,20);
for I=1:7
ii=int2str(I);
t=imread([ii,'.jpg']);
SegBw2=imresize(t,[40 20],'nearest');
if I==1
kmin=37;
kmax=40;
elseif I==2
kmin=11;
kmax=36;
else I>=3
kmin=1;
kmax=36;
end
for k2=kmin:kmax
fname=strcat('字符模板',liccode(k2),'.jpg');
SamBw2 = imread(fname);
for i=1:40
for j=1:20
SubBw2(i,j)=SegBw2(i,j)-SamBw2(i,j);
end
end
Dmax=0;
for k1=1:40
for I1=1:20
if ( SubBw2(k1,I1) > 0 | SubBw2(k1,I1)<0 )
Dmax=Dmax+1;
end
end
end
Error(k2)=Dmax;
end
Error1=Error(kmin:kmax);
MinError=min(Error1);
findc=find(Error1==MinError);
Code(I*2-1)=liccode(findc(1)+kmin-1);
Code(I*2)=' ';
I=I+1;
end
figure(8),imshow(dw),title (['车牌号码:', Code],'Color','b');
如果课题设计中遇到困难疑惑之处,也可向私信小编咨询哟。
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















