















































软件

产品


我这个是改过的,反正点击下面的text entry settings去添加输入源就好了,我添加的智能拼音,够用了。至于网上其他的什么谷歌拼音啥的也试过,但麻烦,这个设置又快,谷歌拼音也不见得好到那里去。
sudo apt update
sudo apt upgrade
sudo apt install python3-pip python3-dev
更改清华源
pip3 install pip -U #如果版本>=10.0.0) ,可以更给源之后在升级pip
pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
实际上 CUDA 的头文件已经安装在 /usr/local/cuda/targets/aarch64-linux/include/ ,需要让编译make能够找到这些头文件。参考 src/cpp/cuda.hpp:14:10: fatal error: cuda.h: No such file or directory ,在 /etc/profile 中添加:
#cuda
export CUDA_HOME=/usr/local/cuda
export CPATH=${CUDA_HOME}/include:${CPATH}
export LIBRARY_PATH=${CUDA_HOME}/lib64:$LIBRARY_PATH
确保ncvv -V可以正确输出
查看/usr/local/cuda/bin下是否有nvcc可执行程序,如果有则说明nvcc没有被设置为系统变量
vim ~/.bashrc
然后在末尾添加
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
然后source ~/.bashrc
最后安装pycuda
中途会有红色输出,其实是在检测python版本,根据
python要求是~=3.6,而nx是3.6.9,所以是可以安装的,只是有检查的过程
pip3 install pycuda
放在pycuda后面是编译安装torchvision的时候,总感觉会用到nvcc,,
见官网https://forums.developer. nvidia .com/t/pytorch-for-jetson-version-1-9-0-now-available/72048
可以搜索
Illegal instruction (core dumped)
解决 参考
导致的问题,除了无法运行某些脚本以外,还导致了无法用pycharm进程远程调试。哎,,,鬼知道为啥会这样,当我后面通过下面的方式解决以后,就可以远程调试了,当面的方式虽然解决了可用在终端运行脚本,却依然无法远程调试,,,,
自解决,完美
protobuf版本低了升级了一下
然后具体问题应该是 numpy 的bug 我用谷歌搜索该报错的时候发现: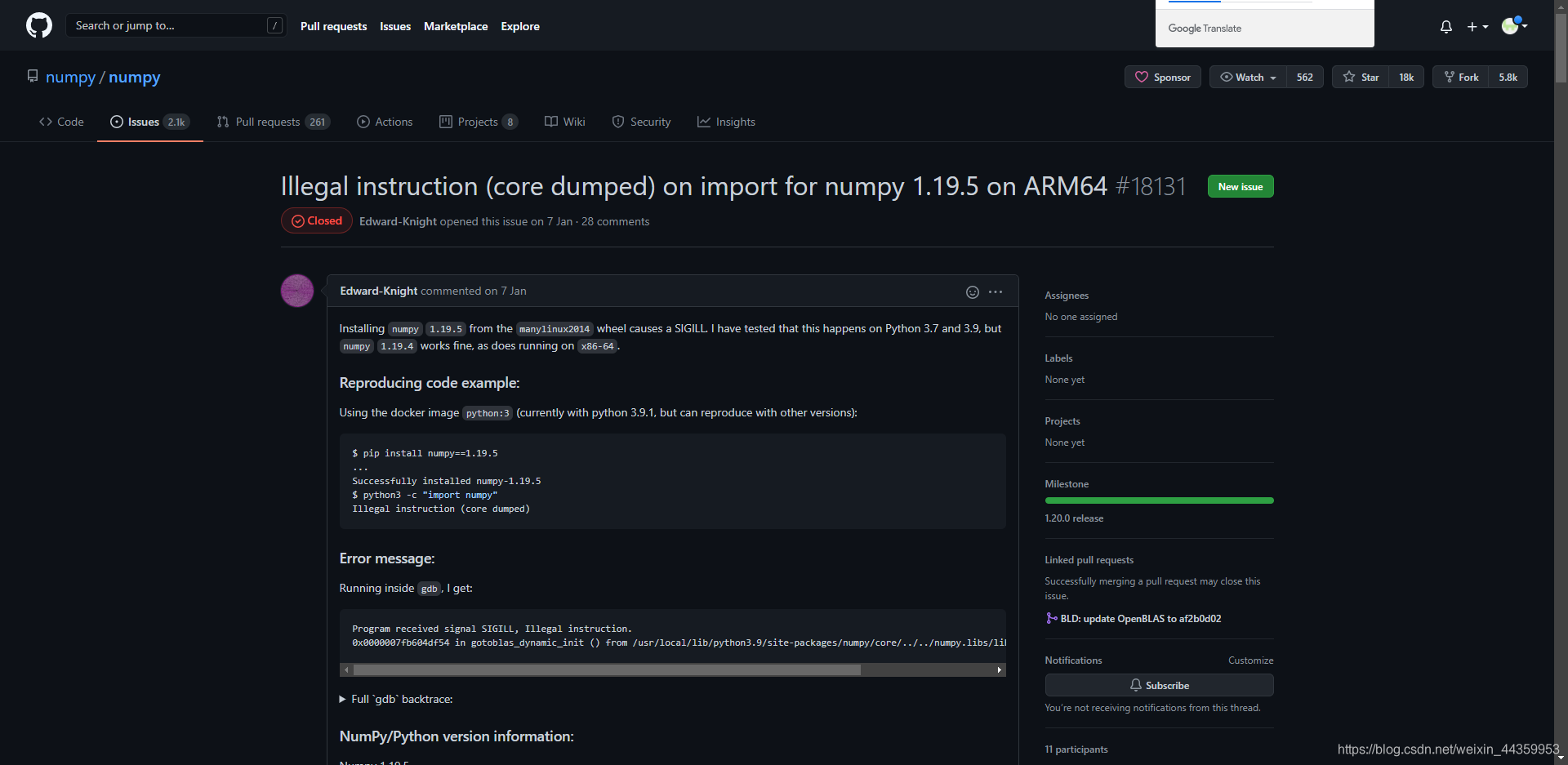
怀疑是1.19.5的版本问题,然后opencv要求1.19.3以上,我就去~/.bashrc把原先添加的环境变量删除并更新后。numpy降级到1.19.3了,然后问题没了,没有报错了
运行yolov5的trt转换时
ModuleNotFoundError: No module named ‘numpy.testing.nosetester’
升级scipy包
sudo pip3 install jetson-stats
jtop #执行
首先,确定tensorrt在jetson上面的版本:
dpkg -l | grep TensorRT
jetson nano截至20210618的jetpack最新 对应tensorrt版本是7.1.3
下载onnx2trt的源码对应tensorrt版本:https://github.com/onnx/onnx-tensorrt 发布里找
有一个坑是下载下来大部分情况是third_party下的onnx是没有,这个是链接到其他仓库的,所以下载可能不下来。自己去下载onnx然后解压到third_party下面。但是要对应onnx2trt的版本的onnx
onnx2trt的对应的onnx版本可以在英伟达tensorrt的发布里查看测试通过的环境查看,得到: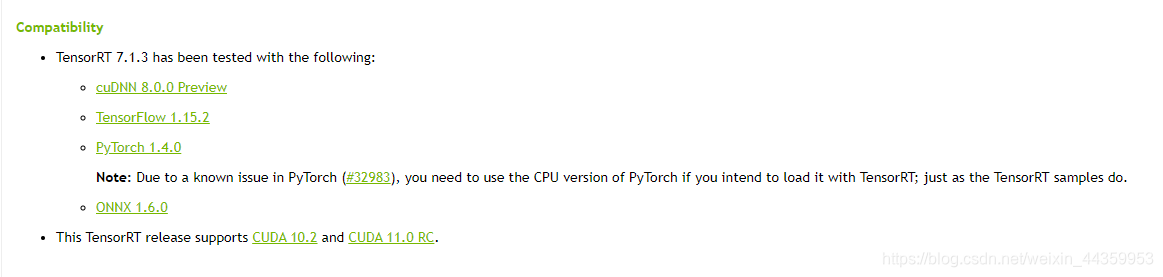
所以下载1.6版本的onnx的源码。
接下来安装官网的提示安装,一般会报错cmake版本,太低了,自己源码编译新版本的cmake,
参考:
wget https://github.com/Kitware/CMake/releases/download/v3.14.4/cmake-3.14.4.tar.gz
tar xvf cmake-3.14.4.tar.gz
cd cmake-3.14.4
./bootstrap --prefix=/usr
这一步很关键,如果没有指定prefix,后面使用时会报错Could not find CMAKE_ROOT
编译安装
make
sudo make install
测试:
执行cmake --version
升级完cmake后在编译onnx2trt还是会报错:c++: internal compiler error: Killed (program cc1plus)
,查报错,原因是内存不足,查资料添加临时内存解决:
https://zhuanlan.zhihu.com/p/50995345
添加临时内存后在安装onnx2trt就顺利了,最后添加环境变量
vim ~/.bashrc
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/你安装的路径/TensorRT-7.1.3/lib
source ~/.bashrc
完了onnx2trt看看安装好没
一些其他的,如安装英伟达发布编译好的arrch即arm版本的torch的时候,报了cpython,以及装了cpython之后又装卡在setup一开始那一步,升级pip解决。
vnc远程配置:https://www.jianshu.com/p/e670a9a26989
实际上onnx2trt生成的.trt文件和python的build engine是一个东西,当然,onnx2trt转是时候参数设置和python的build engine一样,转出来的.trt可以被用,但是一般不这么干,python版本里可以自己生成引擎。而且dynamic batch的时候貌似直接代码好点,实在没研究出来如何用命令行生成。
关于生成动态引擎 参考有dynamic batch
以及 推理 代码
注意#动态尺寸,每次都要set一下模型输入的shape,0代表的就是输入,输出根据具体的网络结构而定,可以是0,1,2,3…其中的某个头。
context.set_binding_shape(0, image .shape)可以设置
参考有推理代码示例
错误:[TensorRT] ERROR: Parameter check failed at: engine.cpp::resolveSlots::1024, condition: allInputDimensionsSpecified(routine)
动态batchsize tensorrt不能直接构建engine,需要设置profile构建
profile = builder.create_optimization_profile()
profile.set_shape(
ModelData.INPUT_NAME,
ModelData.MIN_INPUT_SHAPE,
ModelData.OPT_INPUT_SHAPE,
ModelData.MAX_INPUT_SHAPE)
config.add_optimization_profile(profile)
engine = builder.build_engine(network,config)
一些记录:
1.tensorrt中builder.max_workspace_size的作用
首先单位是字节,比如 builder.max_workspace_size = 1<< 30 就是 2^30 bytes 即 1 GB。
它的作用是给出模型中任一层能使用的内存上限。运行时,每一层需要多少内存系统分配多少,并不是每次都分 1 GB,但不会超过 1 GB。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















