















































软件

产品


该系列文章总纲链接:专题总纲目录 Android Framework 总纲
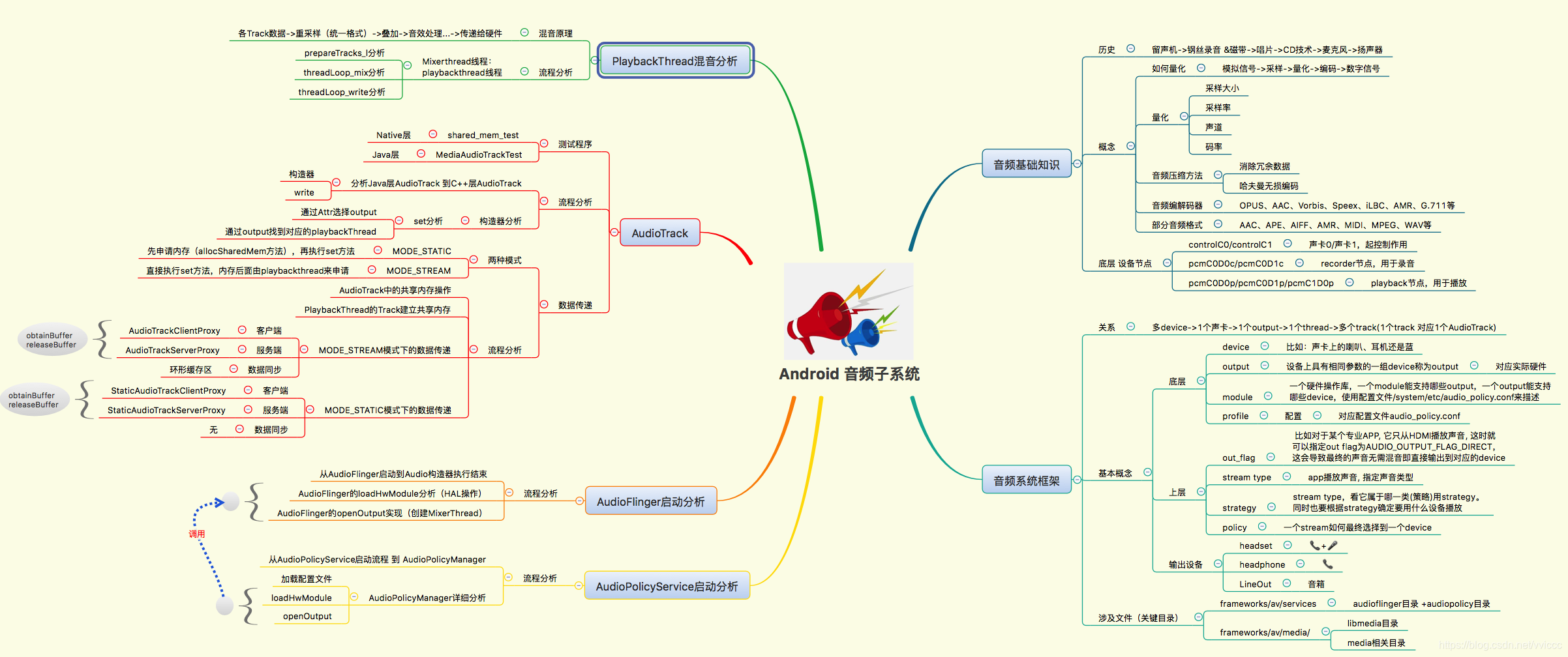
本章节主要关注➕ 以上思维导图左上 PlaybackThread分析 部分 即可。主要是对混音的原理和混音流程进行了分析。
多个应用程序播放,每个 APP 端都会创建AudioTrack,每个AudioTrack都会 通过共享内存 和 播放线程的Track 传递数据,每个应用发送的音频数据 格式可能都不相同,而声卡仅支持固定的几种格式,除非发送的格式就是 声卡本身支持的格式,否则这里都需要进行重采样/混音(playbackthread中使用mAudioMixer的一些操作把硬件不支持的音频格式转化为硬件支持的音频格式,这个过程叫做重采样)。这里我们对MixerThread中的mAudioMixer变量 类 型AudioMixer进行解读,AudioMixer的引用代码如下:
class MixerThread : public PlaybackThread {{public: MixerThread(const sp<AudioFlinger>& audioFlinger, AudioStreamOut* output, audio_io_handle_t id, audio_devices_t device, type_t type = MIXER); virtual ~MixerThread(); //... AudioMixer* mAudioMixer; // normal mixer //...};这里的AudioMixer类 实现如下:
class AudioMixer{public: AudioMixer(size_t frameCount, uint32_t sampleRate,uint32_t maxNumTracks = MAX_NUM_TRACKS); //... //给track使用的hook函数整理 /*进行重采样*/ static void track__genericResample(track_t* t, int32_t* out, size_t numFrames, int32_t* temp, int32_t* aux); /*不做任何处理*/ static void track__nop(track_t* t, int32_t* out, size_t numFrames, int32_t* temp, int32_t* aux); static void track__16BitsStereo(track_t* t, int32_t* out, size_t numFrames, int32_t* temp, int32_t* aux); static void track__16BitsMono(track_t* t, int32_t* out, size_t numFrames, int32_t* temp, int32_t* aux); //... // multi-format track hooks template <int MIXTYPE, typename TO, typename TI, typename TA> static void track__Resample(track_t* t, TO* out, size_t frameCount, TO* temp __unused, TA* aux); template <int MIXTYPE, typename TO, typename TI, typename TA> static void track__NoResample(track_t* t, TO* out, size_t frameCount, TO* temp __unused, TA* aux); //... //给mState使用的hook函数整理 static void process__validate(state_t* state, int64_t pts); /* no-op,如果静音了不做任何处理*/ static void process__nop(state_t* state, int64_t pts); /*如果传递过来的数据,是声卡直接支持的格式,则不需要重新采样*/ static void process__genericNoResampling(state_t* state, int64_t pts); /*如果需要重新采样,则会调用该函数*/ static void process__genericResampling(state_t* state, int64_t pts); static void process__OneTrack16BitsStereoNoResampling(state_t* state,int64_t pts); //... // hook types enum { PROCESSTYPE_NORESAMPLEONETRACK, }; enum { TRACKTYPE_NOP, TRACKTYPE_RESAMPLE, TRACKTYPE_NORESAMPLE, TRACKTYPE_NORESAMPLEMONO, }; //... state_t mState __attribute__((aligned(32))); //...}mAudioMixer中存在成员mstate,state_t结构体的定义如下:
// pad to 32-bytes to fill cache linestruct state_t { uint32_t enabledTracks; uint32_t needsChanged; size_t frameCount; process_hook_t hook; // one of process__*, never NULL int32_t *outputTemp; int32_t *resampleTemp; NBLog::Writer* mLog; int32_t reserved[1]; // FIXME allocate dynamically to save some memory when maxNumTracks < MAX_NUM_TRACKS track_t tracks[MAX_NUM_TRACKS] __attribute__((aligned(32)));};mstate包含了一个 hook 函数,其会指向不同的处理函数。hook针对不同的情况,会指向不同的函数。如果hook函数的指针指向process__genericNoResampling,会有一个outputTemp的临时缓存区,同时这里还有一个tracks(mState成员中变量),每个track跟应用程序的AudioTrack相对应,track_t结构体的定义如下:
struct track_t { uint32_t needs; union { int16_t volume[MAX_NUM_VOLUMES]; // U4.12 fixed point (top bit should be zero) int32_t volumeRL; }; int32_t prevVolume[MAX_NUM_VOLUMES]; int32_t volumeInc[MAX_NUM_VOLUMES]; int32_t auxInc; int32_t prevAuxLevel; int16_t auxLevel; // 0 <= auxLevel <= MAX_GAIN_INT, but signed for mul performance uint16_t frameCount; uint8_t channelCount; // 1 or 2, redundant with (needs & NEEDS_CHANNEL_COUNT__MASK) uint8_t unused_padding; // formerly format, was always 16 uint16_t enabled; // actually bool audio_channel_mask_t channelMask; AudioBufferProvider* bufferProvider; // 16-byte boundary mutable AudioBufferProvider::Buffer buffer; // 8 bytes hook_t hook; //指向不同的处理函数 const void* in; // current location in buffer // 16-byte boundary AudioResampler* resampler; //重采样器 uint32_t sampleRate; int32_t* mainBuffer;//保存重采样之后的最终数据 int32_t* auxBuffer; //... bool needsRamp() { return (volumeInc[0] | volumeInc[1] | auxInc) != 0; } bool setResampler(uint32_t trackSampleRate, uint32_t devSampleRate); bool doesResample() const { return resampler != NULL; } void resetResampler() { if (resampler != NULL) resampler->reset(); } void adjustVolumeRamp(bool aux, bool useFloat = false); size_t getUnreleasedFrames() const { return resampler != NULL ? resampler->getUnreleasedFrames() : 0; };};通过上面对AudioMixer、state_t、track_t等类型的了解,我们可以看到两种hook:
AudioTrack通过共享内存将数据传递给MixerThread(PlaybackThread子类),对MixerThread中的mTracks进行格式分析,看是否为硬件支持的格式,根据不同情况设定不同的hook函数(确定是否重采样),设置完成之后,再去设置总的hook函数(mState中),总结如下:
重采样之后的数据去向说明:在共享内存之中有原始数据,前面提到过outputTemp,各个track其处理之后的数据进入临时缓存区(比如重采样)。所以outputTemp存放的是各个track处理完成之后叠加的数据。这些临时的数据,最终保存到mainBuffer中。每个tracks中的mainBuffer指向PlaybackThread中混合的mMixerBuffer,mMixerBuffer中的数据可以进行播放,但并没有直接发送给硬件,而是发送给mSinkbuffer。当然在android系统中还可以使用mEffectBuffer对声音进行音效处理。他们最后会把buffer发送给硬件mSinkbuffer,如果使用音效,其来源可能是mEffectBuffer与mMixerBuffer。
这里主要以MixerThread为核心进行分析,从MixerThread的父类playbackthread线程开始分析,回顾 AudioPloicyService启动和AudioFlinger启动的源码,playbacktrhead的创建流程分析栈如下:
AudioPolicyService::onFirstRef(...)->AudioPolicyService::createAudioPolicyManager(...);-->AudioPolicyManager(...);--->AudioFlinger::loadHwModule(...);--->AudioFlinger::openOutput(...);---->AudioFlinger::openOutput_l(...);----->创建thread(MixerThread(这里要注意:因为第一次并未传递flag,因此不会创建OffloadThread、DirectOutputThread))----->mPlaybackThreads.add(*output, thread);将thread加入到mPlaybackThreads中即从AudioPolicyService创建之初就开始创建对应output的线程(创建MixerThread,这里要注意:因为第一次并未传递flag,所以不会创建OffloadThread和DirectOutputThread线程。因此这里从playbackthread线程开始分析,构造器代码如下:
AudioFlinger::PlaybackThread::PlaybackThread(const sp<AudioFlinger>& audioFlinger, //... mLatchDValid(false), mLatchQValid(false){ //设置mName snprintf(mName, kNameLength, "AudioOut_%X", id); //...}在onFirstRef中代码实现如下:
void AudioFlinger::PlaybackThread::onFirstRef(){ run(mName, ANDROID_PRIORITY_URGENT_AUDIO);}在创建playbackthread类(以及子类MixerThread等。。。)这里就开始启动线程了。在android线程中threadloop为线程真正的执行体,代码实现如下:
bool AudioFlinger::PlaybackThread::threadLoop(){ //... while (!exitPending()) { cpuStats.sample(myName); Vector< sp<EffectChain> > effectChains; { // scope for mLock Mutex::Autolock _l(mLock); /*处理配置信息*/ processConfigEvents_l(); //... //如果数据为0,则让声卡进入休眠状态 if ((!mActiveTracks.size() && systemTime() > standbyTime) || isSuspended()) { // put audio hardware into standby after short delay if (shouldStandby_l()) { //声卡休眠 threadLoop_standby(); mStandby = true; } if (!mActiveTracks.size() && mConfigEvents.isEmpty()) { IPCThreadState::self()->flushCommands(); //... //线程休眠点,直到AudioTrack发送广播唤醒 mWaitWorkCV.wait(mLock); //... continue; } } //关键点1:混音前的准备工作 mMixerStatus = prepareTracks_l(&tracksToRemove); //... lockEffectChains_l(effectChains); } // mLock scope ends if (mBytesRemaining == 0) { mCurrentWriteLength = 0; if (mMixerStatus == MIXER_TRACKS_READY) { //关键点2:混音 threadLoop_mix(); } else if ((mMixerStatus != MIXER_DRAIN_TRACK) && (mMixerStatus != MIXER_DRAIN_ALL)) { threadLoop_sleepTime(); if (sleepTime == 0) { mCurrentWriteLength = mSinkBufferSize; } } if (mMixerBufferValid) { void *buffer = mEffectBufferValid ? mEffectBuffer : mSinkBuffer; audio_format_t format = mEffectBufferValid ? mEffectBufferFormat : mFormat; //把数据从thread.mMixerBuffer复制到thread.mSinkBuffer memcpy_by_audio_format(buffer, format, mMixerBuffer, mMixerBufferFormat, mNormalFrameCount * mChannelCount); } //... } //... if (mEffectBufferValid) { //把数据从thread.mEffectBuffer复制到thread.mSinkBuffer memcpy_by_audio_format(mSinkBuffer, mFormat, mEffectBuffer, mEffectBufferFormat, mNormalFrameCount * mChannelCount); } // enable changes in effect chain unlockEffectChains(effectChains); if (!waitingAsyncCallback()) { // sleepTime == 0 means we must write to audio hardware if (sleepTime == 0) { if (mBytesRemaining) { //关键点3:音频输出 ssize_t ret = threadLoop_write(); //... } else if ((mMixerStatus == MIXER_DRAIN_TRACK) || (mMixerStatus == MIXER_DRAIN_ALL)) { threadLoop_drain(); } //... } else { usleep(sleepTime); } } //... } threadLoop_exit(); if (!mStandby) { threadLoop_standby(); mStandby = true; } //... return false;}playbackthread负责创建线程,但这里接下来要分析的关键方法都在MixerThread中实现,分析三个关键方法为prepareTracks_l、 threadLoop_mix、threadLoop_write。
MixerThread::prepareTracks_l 的代码实现如下:
AudioFlinger::PlaybackThread::mixer_state AudioFlinger::MixerThread::prepareTracks_l( Vector< sp<Track> > *tracksToRemove){ //默认为空闲状态 mixer_state mixerStatus = MIXER_IDLE; size_t count = mActiveTracks.size(); //... //对于所有在mActiveTracks里面的Track,都需要进行设置 for (size_t i=0 ; i<count ; i++) { const sp<Track> t = mActiveTracks[i].promote(); if (t == 0) { continue; } // this const just means the local variable doesn't change Track* const track = t.get(); // fastTrack不会在这里进行混音,略过 if (track->isFastTrack()) { //... } { // local variable scope to avoid goto warning audio_track_cblk_t* cblk = track->cblk(); /* 获取track的name,这是个索引,AudioMixer会最多维护32个track,分别对应int的32个位, * 如果track的name还没定下来的话,会自行选择一个空位 */ int name = track->name(); size_t desiredFrames; uint32_t sr = track->sampleRate(); if (sr == mSampleRate) { desiredFrames = mNormalFrameCount; } else { desiredFrames = (mNormalFrameCount * sr) / mSampleRate + 1 + 1; desiredFrames += mAudioMixer->getUnreleasedFrames(track->name()); } uint32_t minFrames = 1; if ((track->sharedBuffer() == 0) && !track->isStopped() && !track->isPausing() && (mMixerStatusIgnoringFastTracks == MIXER_TRACKS_READY)) { minFrames = desiredFrames; } //混音的状态下,frameReady = 1,那么会进入下面的条件,进行AudioMixer参数设置 size_t framesReady = track->framesReady(); if ((framesReady >= minFrames) && track->isReady() && !track->isPaused() && !track->isTerminated()) { //音量参数设置 //... //设置AudioMixer参数 mAudioMixer->setBufferProvider(name, track);//源Buffer mAudioMixer->enable(name);//使能该track,可以混音 //音轨 左 右 aux mAudioMixer->setParameter(name, param, AudioMixer::VOLUME0, &vlf); mAudioMixer->setParameter(name, param, AudioMixer::VOLUME1, &vrf); mAudioMixer->setParameter(name, param, AudioMixer::AUXLEVEL, &vaf); //音频格式 mAudioMixer->setParameter( name, AudioMixer::TRACK, AudioMixer::FORMAT, (void *)track->format()); //音轨mask,哪个需要或者不需要混音 mAudioMixer->setParameter( name, AudioMixer::TRACK, AudioMixer::CHANNEL_MASK, (void *)(uintptr_t)track->channelMask()); mAudioMixer->setParameter( name, AudioMixer::TRACK, AudioMixer::MIXER_CHANNEL_MASK, (void *)(uintptr_t)mChannelMask); // limit track sample rate to 2 x output sample rate, which changes at re-configuration uint32_t maxSampleRate = mSampleRate * AUDIO_RESAMPLER_DOWN_RATIO_MAX; uint32_t reqSampleRate = track->mAudioTrackServerProxy->getSampleRate(); if (reqSampleRate == 0) { reqSampleRate = mSampleRate; } else if (reqSampleRate > maxSampleRate) { reqSampleRate = maxSampleRate; } /*进行重采样 *注意:安卓的MixerThread会对所有的track进行重采样 *那么在混音的时候会调用重采样的混音方法。 */ mAudioMixer->setParameter( name, AudioMixer::RESAMPLE, AudioMixer::SAMPLE_RATE, (void *)(uintptr_t)reqSampleRate); if (mMixerBufferEnabled && (track->mainBuffer() == mSinkBuffer || track->mainBuffer() == mMixerBuffer)) { mAudioMixer->setParameter( name, AudioMixer::TRACK, AudioMixer::MIXER_FORMAT, (void *)mMixerBufferFormat); //目的buffer mAudioMixer->setParameter( name, AudioMixer::TRACK, AudioMixer::MAIN_BUFFER, (void *)mMixerBuffer); // TODO: override track->mainBuffer()? mMixerBufferValid = true; } else { //... } //aux buffer mAudioMixer->setParameter( name, AudioMixer::TRACK, AudioMixer::AUX_BUFFER, (void *)track->auxBuffer()); // reset retry count track->mRetryCount = kMaxTrackRetries; if (mMixerStatusIgnoringFastTracks != MIXER_TRACKS_READY || mixerStatus != MIXER_TRACKS_ENABLED) { //状态为 ready表示可以混音 mixerStatus = MIXER_TRACKS_READY; } } else { //... } } // local variable scope to avoid goto warningtrack_is_ready: ; } //... //从mActiveTracks删除需要移除的track removeTracks_l(*tracksToRemove); //... if (fastTracks > 0) { //正常混音准备时,这里返回的是MIXER_TRACK_READY mixerStatus = MIXER_TRACKS_READY; } return mixerStatus;}在准备混音的过程主要做了几件事情:
在prepareTrack_l返回的mMixerStatus值为MIXER_TRACK_READY时,才可以进入threadLoop_mix进行混音。代码实现如下:
void AudioFlinger::MixerThread::threadLoop_mix(){ int64_t pts; status_t status = INVALID_OPERATION; //获取timestamps,即输出时间戳,用于seek到源buffer的某个位置进行混音 if (mNormalSink != 0) { status = mNormalSink->getNextWriteTimestamp(&pts); } else { status = mOutputSink->getNextWriteTimestamp(&pts); } if (status != NO_ERROR) { pts = AudioBufferProvider::kInvalidPTS; } //AudioMixer混音 mAudioMixer->process(pts); //混音了多少音频数据 mCurrentWriteLength = mSinkBufferSize; if ((sleepTime == 0) && (sleepTimeShift > 0)) { sleepTimeShift--; } //等不需要睡眠时直接输出音频 sleepTime = 0; //待机时间更新 standbyTime = systemTime() + standbyDelay;}有了prepareTrack_l设置的参数,在threadLoop_mix中需要做的就是调用AudioMixer的 process 方法进行混音。
threadLoop_write用于混音后的音频输出,代码实现如下:
ssize_t AudioFlinger::MixerThread::threadLoop_write(){ if (mFastMixer != 0) { //...fastMixer处理 } return PlaybackThread::threadLoop_write();}继续分析PlaybackThread::threadLoop_write(),代码实现如下:
// shared by MIXER and DIRECT, overridden by DUPLICATINGssize_t AudioFlinger::PlaybackThread::threadLoop_write(){ // FIXME rewrite to reduce number of system calls mLastWriteTime = systemTime(); mInWrite = true; ssize_t bytesWritten; const size_t offset = mCurrentWriteLength - mBytesRemaining; // If an NBAIO sink is present, use it to write the normal mixer's submix if (mNormalSink != 0) { //将Buffer写到声卡上 ssize_t framesWritten = mNormalSink->write((char *)mSinkBuffer + offset, count); //... // otherwise use the HAL / AudioStreamOut directly } else { //如果用fastMixer的话其实会走该分支,先忽略 // Direct output and offload threads bytesWritten = mOutput->stream->write(mOutput->stream, (char *)mSinkBuffer + offset, mBytesRemaining); //... } //... mNumWrites++; mInWrite = false; mStandby = false; return bytesWritten;//返回输出的音频数据量}整理下threadloop中所做的工作,如下所示:
@1 prepareTracks_l :
@2 threadLoop_mix : 处理数据(比如重采样)、混音
@3 memcpy_by_audio_format:把数据从thread.mMixerBuffer或thread.mEffectBuffer复制到thread.mSinkBuffer
@4 threadLoop_write:把thread.mSinkBuffer写到声卡上
@5 threadLoop_exit
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















