















































软件

产品


1)functools.partial()主要用于将原函数的某些参数固定,减少代码冗余,减少函数调用时的参数。
import functools
import operator
triple = functools.partial(operator.mul, 3)
print(list(map(triple, range(10))))
# [0, 3, 6, 9, 12, 15, 18, 21, 24, 27]
2)functools.partialmethod 函数(Python 3.4 新增)的作用与partial 一样,不过是用于处理方法的
from functools import partialmethod
class Cell(object):
def __init__(self):
self._alive = False
@property
def alive(self):
return self._alive
def set_state(self, state):
self._alive = bool(state)
set_alive = partialmethod(set_state, True)
set_dead = partialmethod(set_state, False)
set_alive_p = functools.partial(set_state, True)
c = Cell()
print(c.alive)
c.set_alive()
print(c.alive)
# c.set_alive_p() #报错,partial()不用于处理方法
print(c.alive)
参考:
偏方法partialmethod
python中partial的使用规则
原书5.10.2节
1)python中非容器类型(比如数字、 字符串 和其他“原子”类型的对象,像xrange对象等)没有被拷贝一说,浅拷贝是用完全切片操作来完成的。
2)其他浅复制的几种情况:
使用切片[:]操作
使用工厂函数(如list/dir/set)
使用copy模块中的copy()函数
3)python中的 赋值 (=)实际上是一种引用,对赋值、浅拷贝和深拷贝,讲的很清楚了。
4) 元组 不可修改和浅拷贝的问题
4.1)元组是相对不可变的,其不可修改指的是不可使用=(assignmen),但元组内存在list等可变对象可使用append/extend,因为append/extend只是增加了列表中的值,而列表的内存地址并没有发生改变。
l1 = [1, 2]
print(id(l1))
l1.extend([3, 4])
print(id(l1))
print(l1)
# 2108870255176 内存地址并没有发生改变,元组中存储的是引用,内存地址没变当然可以使用
# 2108870255176
# [1, 2, 3, 4]
t1 = (1, 2, [3, 4])
t1[2].append(5)
print(t1)
# (1, 2, [3, 4, 5])
4.2)元组中+=的问题
首先需要重温+=这个运算符,如a+=b:
>>> a = ([1, 2], 3, 4)
>>> a[0] += [3, 4]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>> print(a)
([1, 2, 3, 4], 3, 4)
#+=相当于首先进行a[0].extend([3,4]),改变了元组a引用的值,而后进行=操作,
#报错(元组不可修改,不支持=操作),但实际上a引用的值已经发生了改变。
Why does += of a list within a Python tuple raise TypeError but modify the list anyway? [duplicate]
1) 散列函数是一种从任何一种数据中创建小的数字”指纹”的方法。散列函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来。该函数将数据打乱混合,重新创建一个叫做散列值的指纹。散列值通常用来代表一个短的随机字母和数字组成的字符串。好的散列函数在输入域中很少出现散列冲突。在散列表和数据处理中,不抑制冲突来区别数据会使得数据库记录更难找到。你可以把哈希值简单地理解成是一段数据(某个文件,或者是字符串)的DNA,或者身份证;
2)通过一定的哈希算法(典型的有MD5,SHA-1等),将一段较长的数据映射为较短小的数据,这段小数据就是大数据的哈希值。他有这样一个特点,他是唯一的,一旦大数据发生了变化,哪怕是一个微小的变化,他的哈希值也会发生变化。另外一方面,既然是DNA,那就保证了没有两个数据的哈希值是完全相同的。
3)正是因为这样的特点,它常常用来判断两个文件是否相同。比如,从网络上下载某个文件,只要把这个文件原来的哈希值同下载后得到的文件的哈希值进行对比,如果相同,则表示两个文件完全一致,下载过程没有损坏文件。而如果不一致,则表明下载得到的文件跟原来的文件不同,文件在下载过程中受到了损坏。
4)相同的数据有相同的哈希值。
5) python术语对照表中有:
由此可知可哈希对象要满足:哈希值在其生命周期内不改变、有__hash__方法、有__eq__方法(原书3.1节也对此进行了讲解);
5.1)解析以下原书9.6节的代码vector2d.py,改代码将Vector2d变成了一个可哈希对象:
from array import array
import math
class Vector2d:
typecode = 'd'
def __init__(self, x, y):
self.__x = float(x) #将x,y变成私有属性使其不能够改变创建的实例,保持创建的实例不发生改变
#进而保持实例的哈希值不变
self.__y = float(y)
@property
def x(self):
return self.__x
@property
def y(self):
return self.__y
def __iter__(self):
return (i for i in (self.x, self.y))
def __repr__(self):
class_name = type(self).__name__
return '{}({!r}, {!r})'.format(class_name, *self)
def __str__(self):
return str(tuple(self))
def __bytes__(self):
return (bytes([ord(self.typecode)]) +
bytes(array(self.typecode, self)))
def __eq__(self, other): #实现__eq__方法
return tuple(self) == tuple(other)
def __hash__(self): #实现__hash__方法
#官方文档建议的做法是把参与比较的对象全部组件的哈希值混在一起,即将它们打包为一个元组并对该元组做哈希运算,即:hash((self.x,self.y)),
#参见:https://docs.python.org/zh-cn/3/reference/datamodel.html?highlight=__hash__#object.__hash__
return hash(self.x) ^ hash(self.y) #
def __abs__(self):
return math.hypot(self.x, self.y)
def __bool__(self):
return bool(abs(self))
def angle(self):
return math.atan2(self.y, self.x)
def __format__(self, fmt_spec=''):
if fmt_spec.endswith('p'):
fmt_spec = fmt_spec[:-1]
coords = (abs(self), self.angle())
outer_fmt = '<{}, {}>'
else:
coords = self
outer_fmt = '({}, {})'
components = (format(c, fmt_spec) for c in coords)
return outer_fmt.format(*components)
@classmethod
def frombytes(cls, octets):
typecode = chr(octets[0])
memv = memoryview(octets[1:]).cast(typecode)
return cls(*memv)
5.2)官方文档解释了“默认用户定义的实例为可哈希的”(用户定义的类默认带有__eq__()和__hash__()方法…);eq()和__hash__()只实现一个时对象是否可哈希等问题。
__dict__、__class__、__name__、__getattr__、__setattr__返回类、对象的属性、方法,便于交互使用,一致性和完整性差。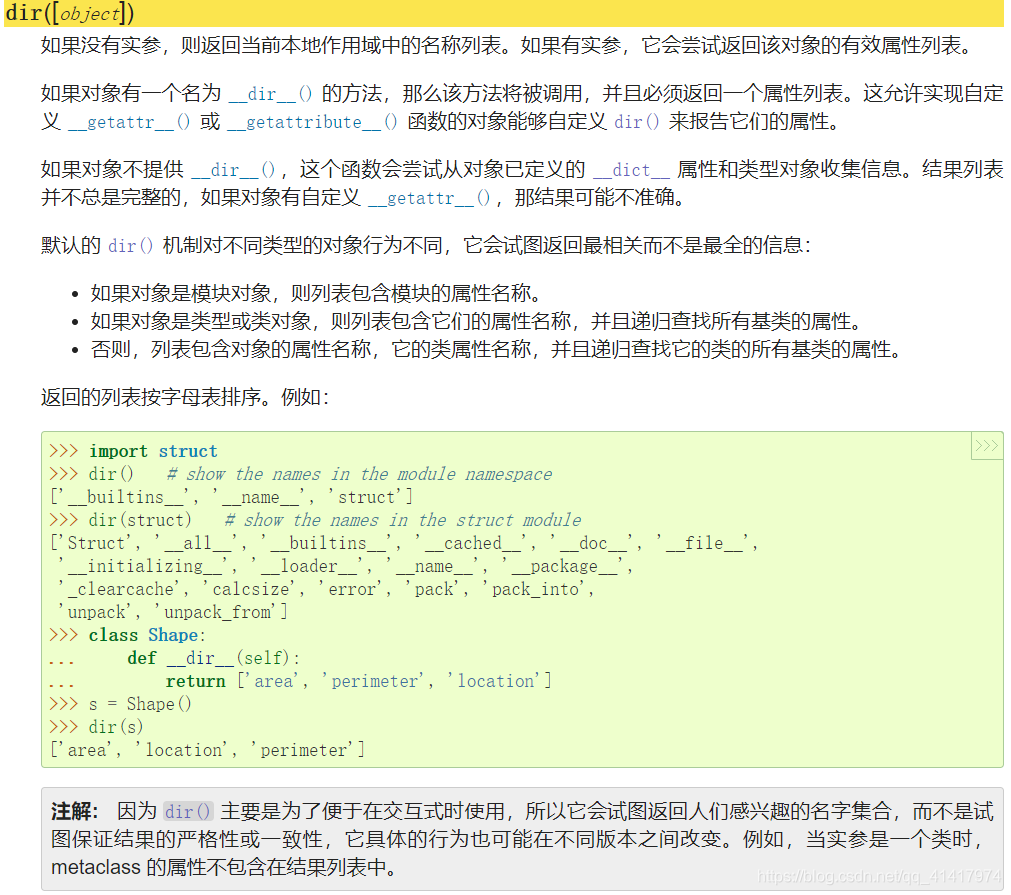
__dict__
1 __dict__属性总结:
from array import array
class Vector2d:
typecode = 'd' # <1>
def __init__(self, x, y):
self.x = float(x) # <2>
self.y = float(y)
def __iter__(self):
return (i for i in (self.x, self.y)) # <3>
def __repr__(self):
class_name = type(self).__name__
return '{}({!r}, {!r})'.format(class_name, *self) # <4>
# END VECTOR2D_V0
v1 = Vector2d(3, 4)
print(v1.__dict__, Vector2d.__dict__)
# {'x': 3.0, 'y': 4.0}
# {'__module__': '__main__', 'typecode': 'd',
# '__init__': <function Vector2d.__init__ at 0x0000024B0D4326A8>,
# '__iter__': <function Vector2d.__iter__ at 0x0000024B0D432730>,
# '__repr__': <function Vector2d.__repr__ at 0x0000024B0D4327B8>,
# '__dict__': <attribute '__dict__' of 'Vector2d' objects>, '__weakref__': <attribute '__weakref__' of 'Vector2d' objects>, '__doc__': None}
__class__实例的__class__属性返回的就是对应的类,而类的__class__返回的是type对象,python内置函数的返回对象通常与类的__class__属性相同。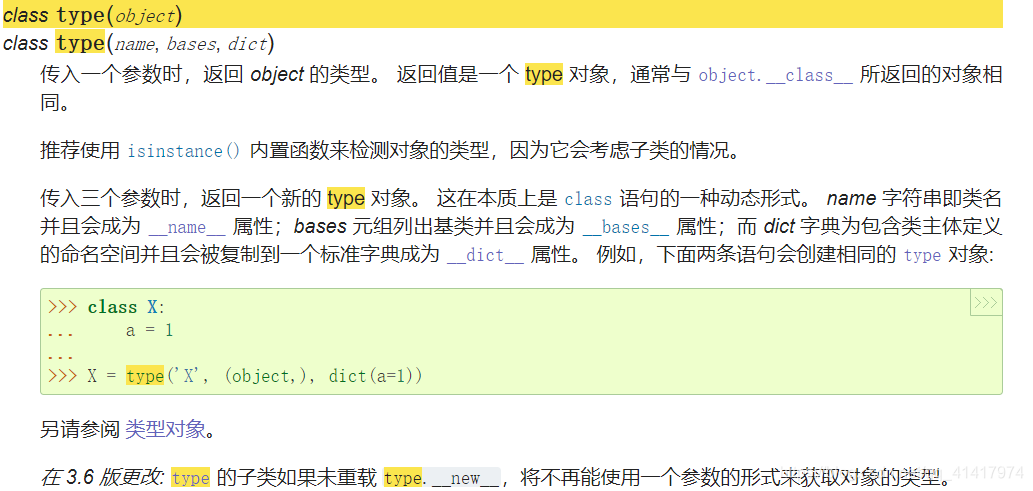
v1 = Vector2d(3, 4)
print(v1.__class__, Vector2d.__class__)
print(v1.__class__.__name__, Vector2d.__name__)
# <class '__main__.Vector2d'> <class 'type'>
# Vector2d Vector2d
__getattr__和__setattr__1 __getattr__:“简单来说,对my_obj.x 表达式,Python 会检查 my_obj 实例有没有名为 x 的属性;如果没有,到类(my_obj.class)中查找;如果还没有,顺着继承树继续查找。 如果依旧找不到,调用 my_obj 所属类中定义的__getattr__ 方法,传入 self 和属性名称的字符串形式(如 ‘x’)” ————《流畅的python》10.5节
2 在使用objexct.x = attr对实例属性值进行设置时就会调用__setattr__方法,同时应当注意避免在重写__setattr__时在其内部使用objexct.x = attr,避免出现无线递归,内存溢出的情况,应该在__setattr__内使用self.__dict__[x] = attr
class A(object):
def __init__(self, value):
self.value = value
def __setattr__(self, name, value):
self.__dict__[name] = value
# self.name = value
a = A(11)
print(a.value) #11
a.value = 12
print(a.value) #12
若在__setattr__内使用self.name = value则当我们实例化这个类的时候,会进入__init__,然后对value进行设置值,设置值会进入__setattr__方法,而__setattr__方法里面又有一个self.name=value设置值的操作,会再次调用自身__setattr__,造成死循环。
1 简单来说实现了__iter__或者__getitem__方法的对象是可迭代的(可以用for循环);实现了__next__方法能够被next()函数不断调用返回下一个值得对象称为迭代器。
2 可迭代对象分为两类,一类:list,tuple,dict,set,str;二类:generator,包含生成器和带yield的generatoe function;而生成器不但可以作用于for,还可以被next()函数不断调用并返回下一个值,但list,dict,str是Iterable,但不是Iterator,要把list,dict,str等Iterable转换为Iterator可以使用iter()函数。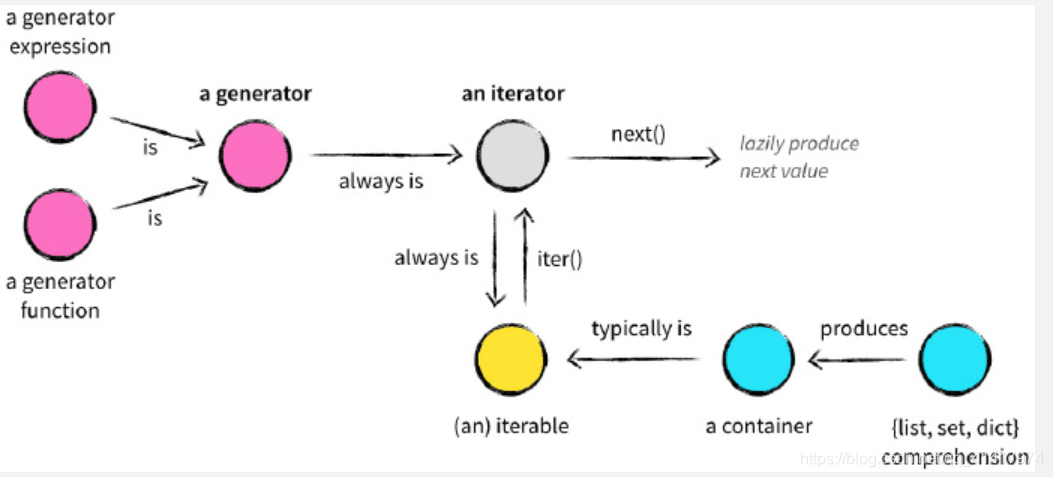
对Python迭代得深入研究
Python 迭代器、生成器和列表解析
1 iter()函数可用用来回去list、tuple等得迭代器,其实际上调用得是可迭代对象得__iter__方法,官方文档得解释为:
2 有官方文档可知:
from random import choice
values = [1,2,3,4,5,6,7]
def test_iter():
return choice(values)
it = iter(test_iter, 2)
for i in it:
print(i)
上面代码的流程:test_iter函数从values列表中随机挑选一个值并返回,调用iter(callable, sentinel)函数,把sentinel标记值设置为2,返回一个callable_iterator实例,遍历这个特殊的迭代器,如果函数返回标记值2,直接抛出异常退出程序。
import collections
Card = collections.namedtuple('Card', ['rank', 'suit'])
class FrenchDeck:
ranks = [str(n) for n in range(2, 11)] + list('JQKA')
suits = 'spades diamonds clubs hearts'.split()
def __init__(self):
self._cards = [Card(rank, suit) for suit in self.suits
for rank in self.ranks]
def __len__(self):
return len(self._cards)
def __getitem__(self, position):
return self._cards[position]
if __name__=="__main__":
from collections.abc import Sequence
deck = FrenchDeck()
print(isinstance(deck, Sequence)) #False,不能通过isinstance检查,但有经验的程序员应该知道其是序列
for card in deck:
print(card) #Card(rank='2', suit='spades') Card(rank='3', suit='spades')...
#deck 实现了__len__和__getitem__是序列,python的迭代会依次尝试调用__iter__,__getitem__
print(Card(rank='2', suit='spades') in deck) #True
# python的in测试会依次尝试调用__contains__,__iter__,__getitem__
“FrenchDeck 类能充分利用 Python 的很多功能,因为它实现了序列协议,不过代码中并没有声明这一点。任何有经验的 Python程序员只要看一眼就知道它是序列,即便它是 object 的子类也无妨。
我们说它是序列,因为它的行为像序列,这才是重点。” ————《流畅的python》10.3节
比如不可变序列(Sequence),需要实现__contains__,iter,len,getitem,reversed,index,count。对于其中的抽象方法,子类在继承时必须具体化,其余非抽象方法在继承时可以自动获得,Sequence序列必须具体化的抽象方法是__len__和__getitem__。
from collections import abc
class Foo(abc.Sequence):
def __init__(self, components):
self._components = components
def __getitem__(self, item):
return self._components[item]
def __len__(self):
return len(self._components)
f = Foo(list('abcde'))
print(isinstance(f, abc.Sequence)) # 结果True
print(f[0]) # 'a',__getitem__
print(len(f)) # 5,__len__
print('b' in f) # True,__contains __
for i in f: # __iter__
print(i)
print(list(reversed(f))) # ['e', 'd', 'c', 'b', 'a'], __reversed__
print(f.count('a')) # 1, count
print(f.index('a')) # 0, index
#《流畅的python》11.10节
>>> class Struggle:
... def __len__(self): return 23
...
>>> from collections import abc
>>> isinstance(Struggle(), abc.Sized)
True
>>> issubclass(Struggle, abc.Sized)
True
这里既没有继承,也没有注册,但Struggle依然被issubclass判断为abc.Sized的子类。是因为abc.Sized实现了一个特殊的类方法__subclasshook__:
# 代码3.7,abc.Sized的实现在 _collections_abc.py 中
class Sized(metaclass=ABCMeta):
__slots__ = ()
@abstractmethod
def __len__(self):
return 0
@classmethod
def __subclasshook__(cls, C):
if cls is Sized:
# 源代码中是 return _check_methods(C, "__len__"),这里修改了一下
if any("__len__" in B.__dict__ for B in C.__mro__):
return True
return NotImplemented
“我在 Python 源码中只见到 Sized 这一个抽象基类实现了__subclasshook__ 方法,而 Sized 只声明了一个特殊方法,因此只用检查这么一个特殊方法…在你我自己编写的抽象基类中实现 subclasshook 方法,可靠性很低。”————《流畅的python》11.10节
“collections.abc.Iterable类实现了__subclasshook__方法”——————《流畅的python》14.1节序列可迭代的原因:iter函数。
class Foo:
def __iter__(self):
pass
from collections.abc import Iterable
print(issubclass(Foo, Iterable)) #Ture
在决定自行实现__subclasshook__方法之前,请想清楚你一定需要这个方法吗?你的能力能够保证这个方法的可靠性吗?
参考:guxh的python笔记七:抽象基类
装饰器是Python用于封装函数或类的代码工具,是Python函数的高级特性之一。其主要功能是使某个函数在不需要做任何变动的前提下增加额外功能,即对某个函数进行功能”装饰“;主要作用是可以提高代码的可读性、简洁性以及扩展性,常用于后期功能升级;具体做法是将一些特定或者通用的方法写成装饰器,在待装饰函数定义前加上@+装饰器名称。
“装饰器是可调用的对象,其参数是另一个函数(被装饰的函数)。 装饰器可能会处理被装饰的函数,然后把它返回,或者将其替换成另一个函数或可调用对象。”————《流畅的python》7.1节
装饰器通常把函数替换成另一个函数,即返回另外一个函数,但有时也可以返回传进来的函数
“装饰器的一个关键特性是,它们在被装饰的函数定义之后立即运行。这通常是在导入时(即 Python 加载模块时)”————《流畅的python7.2节》
import time
user_name = "zb"
user_pwd = "123"
def time_func(func1):
print("time")
def inner1():
print("from inner1")
start_time = time.time()
func1()
stop_time = time.time()
print(stop_time-start_time)
return inner1
def auth_func(func2):
print("auth")
def inner2():
print("from inner2")
name = input("input your name:").strip()
pwd = input("input your password:").strip()
if name == user_name and pwd == user_pwd:
print("login successful")
func2()
else:
print("name or password error")
return inner2
############################
@time_func
@auth_func
def test():
print("from test")
上述代码在pythontutor 中执行时内存情况如下图,在@time_func之前,分别为user_name,user_pwd,time_func,auth_func,开辟了内存,在test函数定义后两个装饰器就开始运行了:
装饰器@auth_func 就相当于test = auth_func(test)①执行等号左边代码:test赋值给func2即func2指向了test的内存地址
②auth_func():执行函数auth_func,定义了函数inner2,申请1片内存地址,函数名inner2指向这片内存地址(此处并未调用函数,故看成1行代码),继续向下执行,返回inner2
③test接收返回值inner2即test指向了inner2的内存地址
装饰器@time_func执行,test = time_func(test),
①test赋值给func1即func1指向test的内存地址(此时test指向了inner2),故func1指向了inner2,
②定义了函数inner1,申请1片内存地址,函数名inner1指向这片内存地址(未调用函数,故看成1行代码),继续向下执行,返回inner1
③test接收返回值inner1,test指向了inner1的内存地址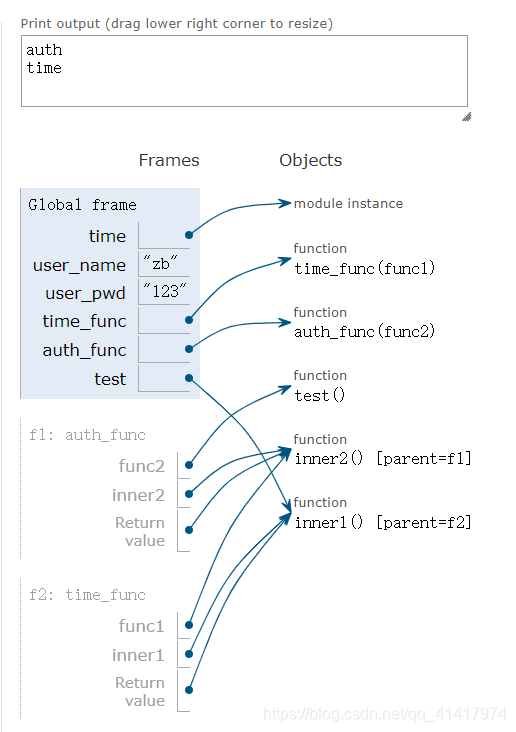
test()
调用函数test(),执行test指向的内存地址代码即inner1,inner1中的func1指向了inner2,inner2中的func2指向了test
inner1()
inner2()
test()
运行结果 inner1,inner2,这里的装饰器time_func计算的是inner2函数和test函数运行所需的时间。
auth
time
from inner1
from inner2
input your name:zb
input your password:123
login successful
from test
10.312341928482056
若是将装饰器代码作为模块直接导入,其会直接运行,结果为:
time
aut
参考:两个装饰器的执行顺序
装饰器简介及多个装饰器执行顺序
“请大家跟我理解一下,如果在一个函数的内部定义了另一个函数,外部的我们叫他外函数,内部的我们叫他内函数。
闭包:
在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用。这样就构成了一个闭包。
一般情况下,在我们认知当中,如果一个函数结束,函数的内部所有东西都会释放掉,还给内存,局部变量都会消失。但是闭包是一种特殊情况,如果外函数在结束的时候发现有自己的临时变量将来会在内部函数中用到,就把这个临时变量绑定给了内部函数,然后自己再结束。”——python中的闭包解释
def make_averager():
series = []
def averager(new_value):
series.append(new_value)
total = sum(series)
return total/len(series)
return averager
###################
avg = make_averager()
print(avg(10))#10
print((avg(11))#10.5
上述代码中series是一个自由变量:,series在其本地作用域averager中并没有被绑定(我们没有给 series 赋值,我们只是调用 series.append),所以其是一个自由变量,但是若在averager中对series赋值(series=[1]),series就会变成局部变量。(==python不声明局部变量,但假定在函数定义体中赋值的变量是局部变量)
按照我们正常的认知,一个函数结束的时候,会把自己的临时变量都释放还给内存,之后变量都不存在了。一般情况下,确实是这样的。但是闭包是一个特别的情况。外部函数发现,自己的自由变量会在将来的内部函数中用到,自己在结束的时候,返回内函数的同时,会把外函数的自由变量送给内函数绑定在一起。所以外函数已经结束了,调用内函数的时候仍然能够使用外函数的自由变量。
参考:python中的闭包解释
def f():
x = 0
y = "*"*10
while x<4:
yield x
x += 1
yield y
for i in f(): #for循环直接自动调用next()方法,f()执行到yield x处被冻结,输出0,for下次循环再调用
print(i)#next()方法,f()从yield x处开始执行,运行到yield y处被冻结,输出"*"*10,下次循环则从
#被冻结的yield y处开始执行
"""
0
**********
1
**********
2
**********
3
**********
"""
def chain(*iterables):
for it in iterables:
for i in it:
yield i
x = "abc"
y = tuple(range(4))
print(list(chain(x, y)))
#['a', 'b', 'c', 0, 1, 2, 3]
def chain_oth(*iterables):
for it in iterables:
yield from it
print(list(chain_oth(x, y)))
#['a', 'b', 'c', 0, 1, 2, 3]
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















