















































软件

产品


Abaqus作为强大的有限元通用软件,可以对许多岩土工程领域进行数值模拟。当然,边坡工程也是其中之一。
我国自然灾害频发,传统的极限平衡法不能得到边坡工程的应力应变数据,而有限元方法可以将土体的本构模型考虑在内,求出土体的应力应变并通过Abaqus强大的后处理功能绘制出云图。故有限元强度折减法近年来被越来越多技术人员熟知,对于较为复杂的边坡模型更加适用。
Abaqus软件分为前处理—计算—后处理三大模块。前处理是指利用Abaqus模仿实际物体的参数、形状、约束等因素。计算是指对模型进行有限元计算。后处理是指对有限元计算结果进行分析、处理、出图等操作。
本章将详细讲述这三部分过程,为可靠度计算提供模型基础。
Abaqus早期是通过命令建立模型,并没有友好的用户交互界面,后期为了方便更多人使用,开发出了CAE模块,win10系统通过系统搜索“cae”即可调出。
当然,也可以试着用命令行控制模型建立,此种方法虽然门槛较高,但是更加容易帮助我们了解有限元软件的运行原理。同样在win搜索中输入“abaqus command”即可
CAE(Computer Aided Engineering)是指计算机辅助工程,顾名思义就是通过计算机对工程问题进行模拟,以达到预测、复现的效果,这样可以减少预算,避免损失。
进入cae界面后,首先要进行模型轮廓的建立,本文使用简单的二维模型进行强度折减计算,并且在后续的章节使用通用的模型进行分析。
Create part—更改模型名称—选择"2D Planar"—Continue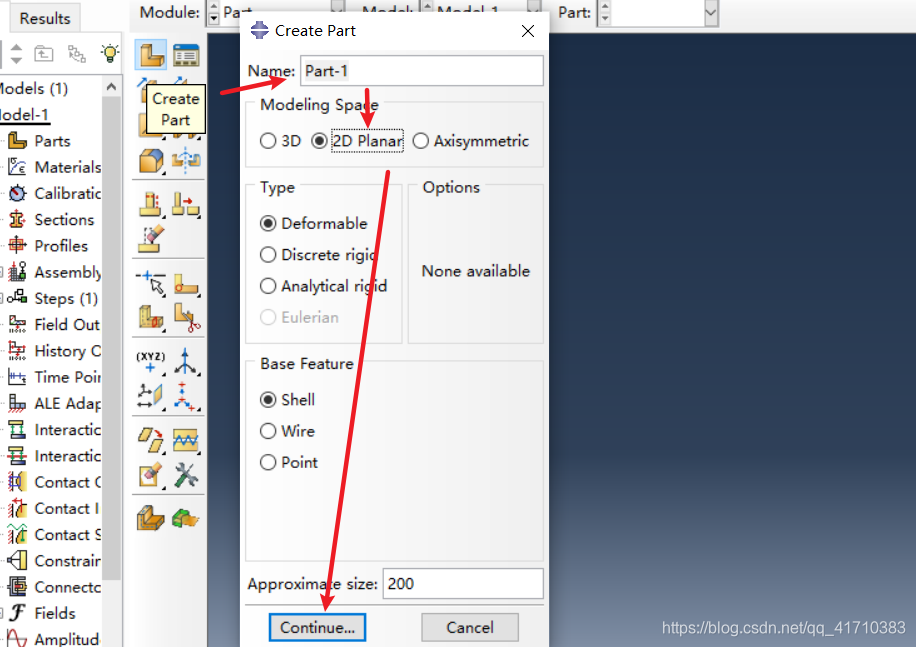
通过以上操作确定模型为二维Deformable模型
用Create lines画出边坡轮廓线(暂时不管尺寸)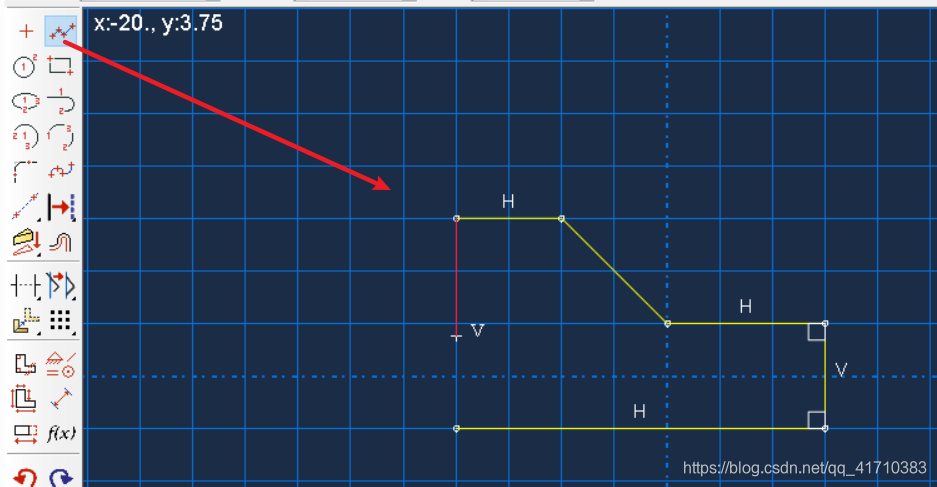
用Add Dimension对每条边进行赋值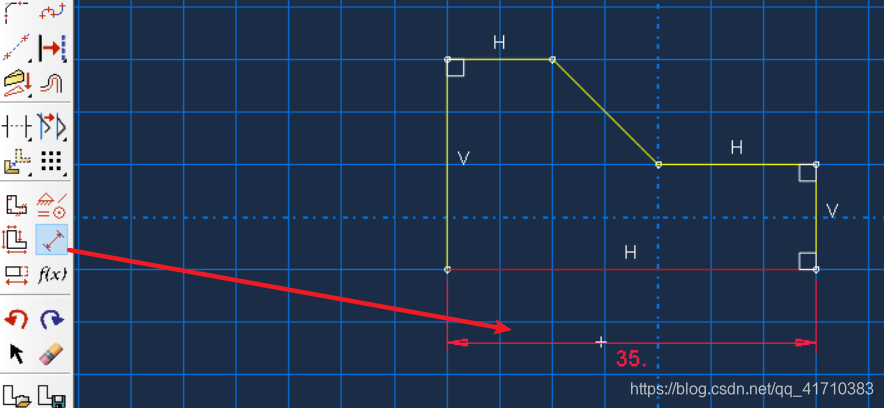
赋值完成后如图所示
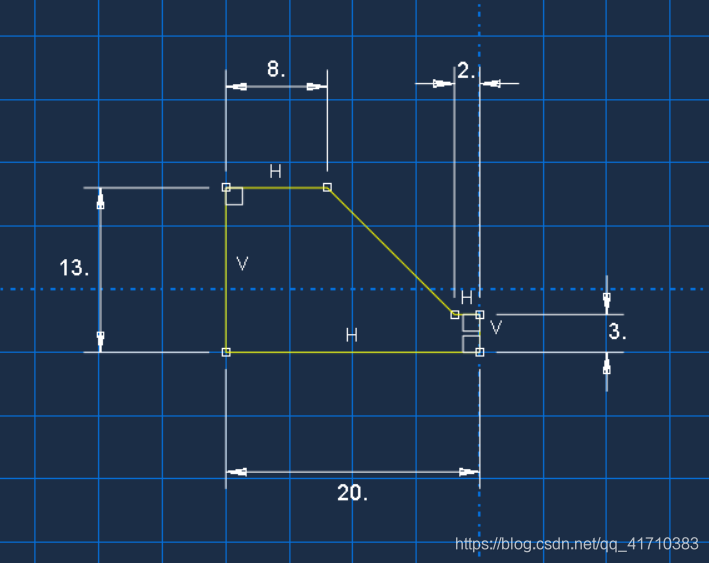
通过上述操作后点击鼠标中键,完成轮廓绘制
至此便完成了边坡轮廓的建立
此算例为费康老师《Abaqus在岩土工程中的应用》强度折减法算例
当然,有时我们需要把已有的较为复杂的CAD图导入CAE中,具体操作参考我的另一篇文章
CAD图形导入Abaqus2020方法
边坡有限元强度折减法建模需要用到七个模块(Module)分别是Part-Property-Assembly-Step-Load-Mesh-Job,接下来按这个顺序操作
网格类型
操作流程:点击Element Type—扩选模型—下拉Family框,选择—Plane Strain(平面应变问题)—OK
网格种类
操作流程:点击Mesh Controls—Element Shape(选择“Quad”)—Technique(“Structure’”)—OK
布种
操作流程:点击Seed Part—默认点击Apply—如果种子较疏松,则通过改变Approximate global size:(改为较小的值)—OK
创建网格
操作流程:点击Mesh Part—选择全部区域—点击鼠标中键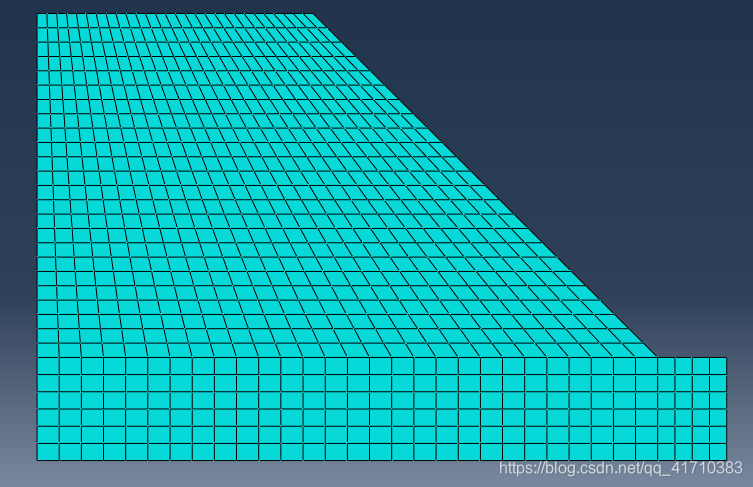
创建完网格后要修改关键字,将关键字插入,具体操作见动态图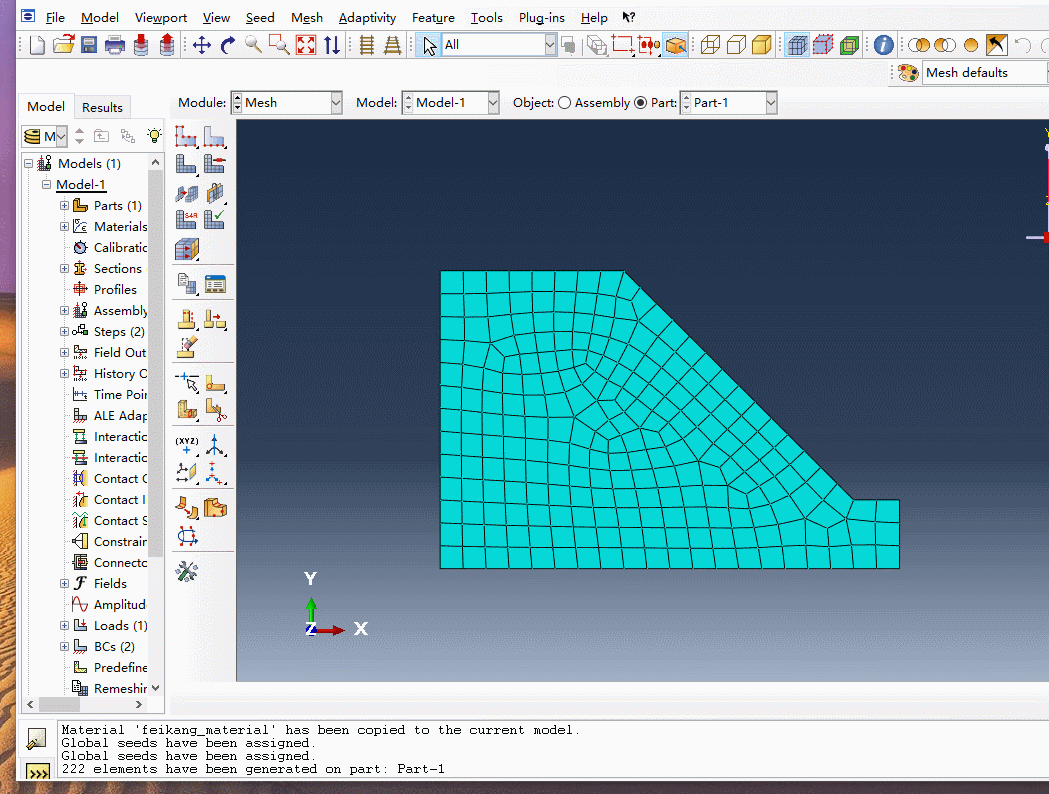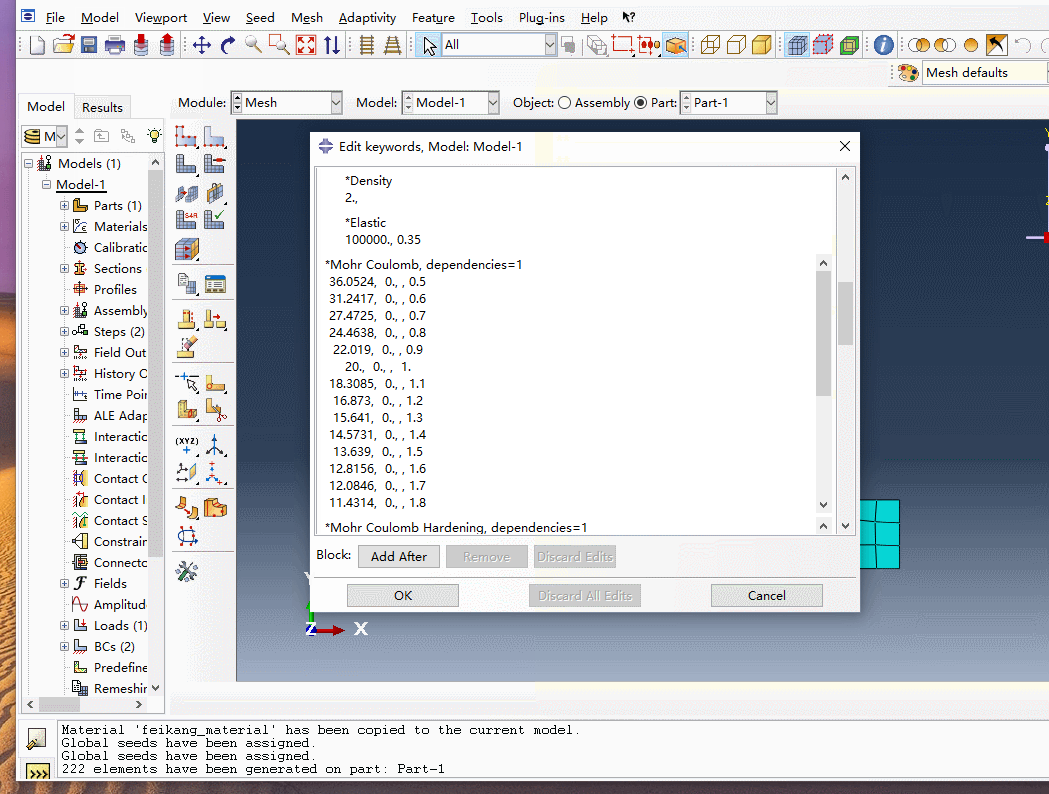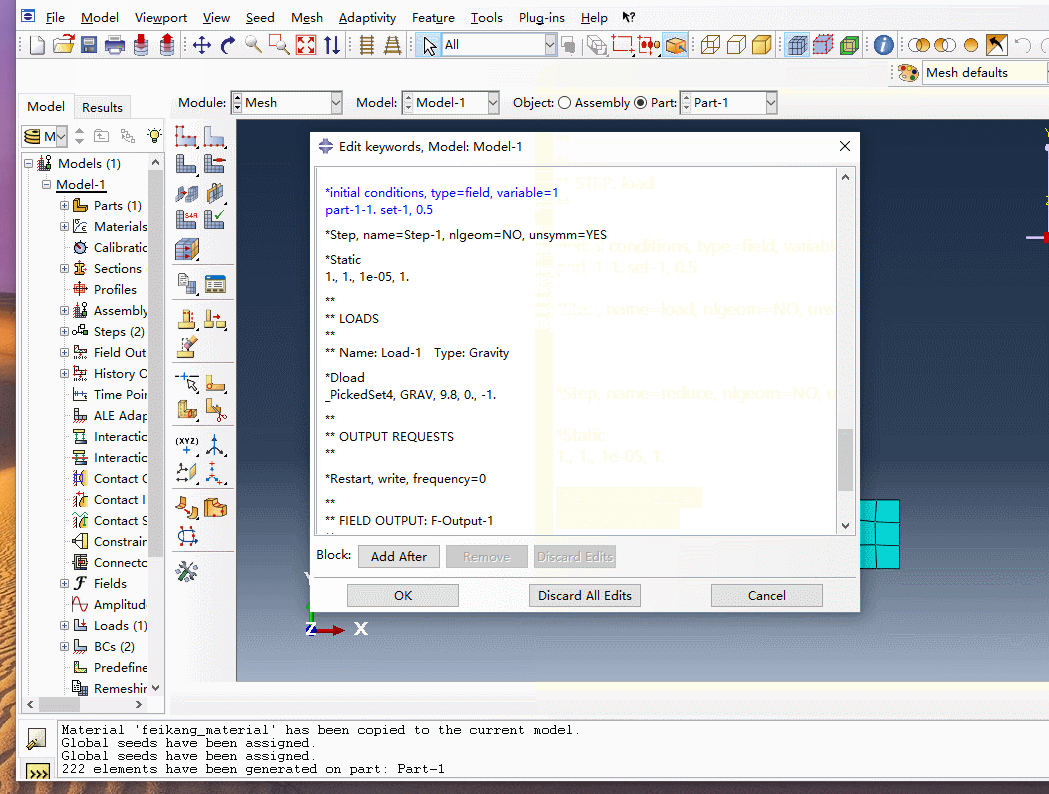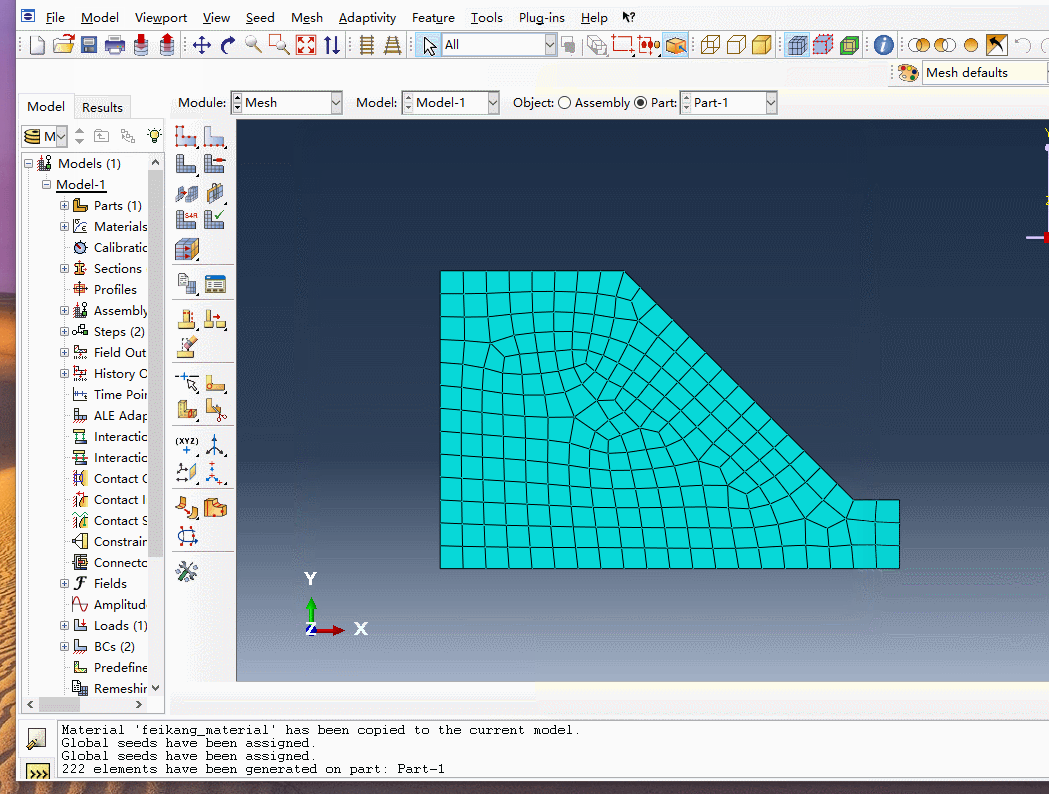
第一个关键字
*initial conditions, type=field, variable=1
part-1-1. set-1, 0.5
其中set-1为一开始创建的点集,表示强度折减的区域为整个边坡,0.5表示强度折减从0.5开始进行
第二个关键字
*field, VARIABLE=1
part-1-1. set-1,3
其中3表示强度折减最多折减到3
注意“set-1”必须与之前整个边坡的点集名称一致!!!
7. Job
操作流程:Create Job—Continue—OK—Job Manager—Submit
通过以上7步就完成了边坡强度折减法的建模和计算过程
计算完成后可以任意的将计算结果进行后处理分析,比如绘制出U1-FV1曲线,观察位移和折减系数的变化关系,通过上述建模后并利用费康老师书中的绘制方法会弹出错误信息
"X Value is not monotonic and interpolation is undefined"
经过尝试后发现,是因为我修改了折减系数的步长,如果将材料中内摩擦角和粘聚力按照费康老师书中设置,就可以绘制出曲线。
在了解INP文件之前,首先要注意,INP并不是一种语言,而是按照Abaqus书写要求组织成的一个文档,其中包括模型的全部信息(部分子程序没有),在CAE中对模型进行计算,等同于调用Abaqus引擎对INP文件进行计算。所以,如果想要传输模型信息,INP当然是首选。
本文针对强度折减法INP文件进行讲解,避免陈述太多与强度折减法无关的讲解。
首先INP文件包括模型数据和历史数据两部分组成:1.模型数据 2.历史数据
1.模型数据的作用:定义一个有限元模型.包括单元,节点,单元性质,定义材料等等有关说明模型自身的数据.模型数据可被组织到零件中(零件可以被组装成一个有意义的模型)。
2.历史数据的定义是模型发生了什么----事情的进展,模型响应的荷载,历史被分成一系列的时步层序.每一步就是一个响应。
不论哪种数据,他们都由关键字行、数据行和注释行组成。关键字行一般用*开头,数据行必须紧跟关键字行,注释行以**开头
强度折减INP文件一般有下面这些关键字行
*Heading :写作规范,INP文件必须以此为开头
*Part :定义部件名称
* Node :节点信息,包括所有节点的编号和坐标
*Element:单元信息,包括所有单元的编号、单元类型,单元对应节点编号
*Nset:节点点集
*Elset:单元点集
*Solid Section:实体截面定义
*End Part:结束部件部分
*Assembly:装配
*Instance
*End Instance
*Nset:装配后的点集名称
*Elset:装配后的单元铭恒
*End Assembly:结束装配
*Material:定义材料
*Density:密度
*Mohr Coulomb:定义内摩擦角
*Mohr Coulomb Hardening:定义粘聚力
*Boundary:定义边界条件
*Step:定义分析步1,一开始为load分析步
*Static:
*Dload:定义重力加速度
*Output, field:定义场输出变量
*Node Output:定义节点输出
*Element Output,:定义单元输出
*End Step:结束分析步1
*Step:分析步2,一般为reduce分析步
*Static
*Node Output:节点输出
*Element Output:单元输出
*End Step:结束分析步2
1.一个数据行包括空格在内不能超过256个字符。
2.所有的数据条目之间必须用“,”格开。
3.一行中必须包括指定说明的数据条目的数字。
4.每行结尾的空数据域可以省略。
5.浮点数最多可以占用20个字符。
6.整数可以是10个
7.字符串可以是80个
8.延续行可以被用到特定的情况。
Abaqus是通过控制关键字实现强度折减法的,关键字中包含场变量的起始值和终止值,还包括参与强度折减单元的点集,这在之前建模时都有所提及,下面再细致的讲解一下
第一个关键字
*initial conditions, type=field, variable=1
part-1-1. set-1, 0.5
其中part1-1.set-1就是模型在装配后的点集编号,可以从cae界面左侧模型树中查询,Model-1—Assembly—Sets,只要关键字中的点集和装配后总体模型的点集名称一致,则关键字设置正确。“0.5”是指场变量的起始值。
** 第二个关键字**
field, VARIABLE=1
*part-1-1. set-1,3
其中"3"是指强度折减的终止值
从关键字可知,强度折减法通过变换场变量的值,将内摩擦角和粘聚力进行折减,首先从0.5折减,也就是将强度乘以二倍,如果边坡计算收敛,则继续增加折减系数,通过不断的折减最终以计算不收敛为结束准则。
由于可靠度的计算和蒙特卡罗方法密不可分,而蒙特卡洛法又和抽样密不可分,故本章会大致介绍一下抽样方法的相关知识。
蒙特卡洛法:蒙特卡洛(Monte Carlo)方法首先生成随机变量的样本,然后将随机变量的样本作为输入获得功能函数的样本,再统计是小样本的数量从而估算失效概率。
在说明抽样方法前,首先要介绍随机数的产生,因为想要得到随机抽样样本的前提是可以生成较为“随机”的随机数,比方说,用什么方法才能从0-1之间抽取一个数,怎样保证抽样过程是真的随机?
随机数又分为真随机数和伪随机数,真随机数要求产生的数列之间没有相关关系, 在给定初值的情况下数列不具有重现性,但是伪随机数则恰好相反,伪随机数在给定初值的情况下会生成具有重复性的随机数,这就要求计算机在生成随机数时应该具有足够长的周期,使得在数列重复之前能产生足够多的随机数。
随机数一般都从0-1均匀分布随机数的生辰开始,然后通过逆变换法,将0-1均匀分布转化为其他分布类型。
具体相关知识可以参考祝玉学老师的《边坡可靠性分析》一书和张璐璐老师的《岩土工程可靠度理论》一书。在此不加赘述。
常用的抽样方法有重要抽样方法和拉丁超立方抽样方法。本节主要讲解拉丁超立方抽样方法。具体内容可以从参考我的另一篇文章图解拉丁超立方抽样。抽样方法之所以被研究,是因为他们相较普通简单的抽样方法可以在达到相同计算精度的前提下抽取较少的样本,提高计算的效率。可以理解为,通过各种抽样方法抽取的样本能够更好的代表某个随机变量的统计特征。
拉丁超立方抽样可以在给定抽样函数的情况下,采取更有策略的抽样方法,获得更能代表抽样函数的随机数,从而统计减小误差。
上一章对抽样方法进行了讨论,但是通常情况下,功能函数包含多种随机变量,也就是受到许多不同因素的影响,而这些因素同时又具有相关性。比如边坡的安全系数可以受到粘聚力和内摩擦角的影响,但是实验结果表明,内摩擦角和粘聚力通常呈现负相关关系,也就是土体的内摩擦角大则粘聚力就有可能较小。这种相关关系对计算结果也有一定的影响,应该加以讨论。
首先介绍相关系数的概念:相关系数是用来形容两组数据之间相关性的度量,相关系数取值区间在[-1,1]之间,如果相关系数大于零,则称两组数据正相关,反之称两者负相关,当相关系数等于0时,则称两组数据线性无关,注意这里所说的是线性无关,但有可能非线性相关,也就是拥有非线性的相关关系。假设有两个随机变量X、Y,通过抽样后得到了他们的样本向量X=(x1,x2,x3,…,xn)共n个元素,同理Y=(y1,y2,y3,…,yn)共n个元素。通过以下公式可以得到两组数据的相关系数。
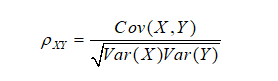
现在假设有四个随机变量则,四个随机变量之中,每两个随机变量就可以通过上式计算出他们的相关系数,则四个随机变量可生成相关系数矩阵,如下图: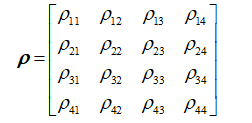
其中,随机变量和其本身的相关系数等于1,且随机变量1和2的相关系数等于随机变量2和随机变量1的相关系数相同。故相关系数矩阵是对角线为1的对称矩阵。
综上可知,相关系数矩阵就是用来形容一些随机变量之间相关性的矩阵。
计算相关系数的相关代码( python 代码)如下:
import numpy
Y=[1,2,3,4,5,5]
X=[5,4,3,2,1,0]
t=numpy.corrcoef(X,Y)
print(t)
结果
ans =
[[ 1. -0.98198051]
[-0.98198051 1. ]]
什么是乔利厄斯基分解?
Cholesky 分解是把一个对称正定的矩阵表示成一个下三角矩阵L和其转置的乘积的分解。它要求矩阵的所有特征值必须大于零,故分解的下三角的对角元也是大于零的。Cholesky分解法又称平方根法,是当A为实对称正定矩阵时,LU三角分解法的变形。(百度百科)
如图:L即为下三阶矩阵,LT是L的转置矩阵。
代码如下:
import numpy as np
co_mat1=[[1,0.5],[0.5,1]]
down_mat1=np.linalg.cholesky(co_mat1)
print(down_mat1)
结果:
[[1.
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















