





































































问题描述
使用客户特征数据预测客户是否有流失的可能;
数据文件名称Orange_Telecom_Churn_Data.csv。
分析KNN算法不同参数设置对模型预测精度的影响
数据来源于:https://software.intel.com/content/www/cn/zh/develop/training/course-machine-learning.html
数据文件、源程序等均可在QQ群517718332中下载。
第一步:获取数据
导入数据;
观察数据格式;
对数据进行初步的处理,比如删除一些没有意义的特征,替换一些缺失值等。
# 导入模块
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelBinarizer,MinMaxScaler
from sklearn.model_selection import GridSearchCV
from sklearn.neiors import KNeiorsClassifier
import numpy as np
import matplotlib.pyplot as plt
# 导入数据
file_path = "./data/Orange_Telecom_Churn_Data.csv"
raw_data = pd.read_csv(file_path)
raw_data.head()
表格太大公众号显示有问题,大家可以在这个网站上看http://www.xiaoqing-cae.com/
raw_data.describe()
表格太大公众号显示有问题,大家可以在这个网站上看http://www.xiaoqing-cae.com/
# 观察特征值是否能把目标值区分开,或者说特征值是否有效
# sns.pairplot(raw_data, hue='churned', height=3);
g = sns.JointGrid(data=raw_data, x="account_length", y="number_vmail_messages", hue="churned")
g.plot(sns.scatterplot, sns.histplot);
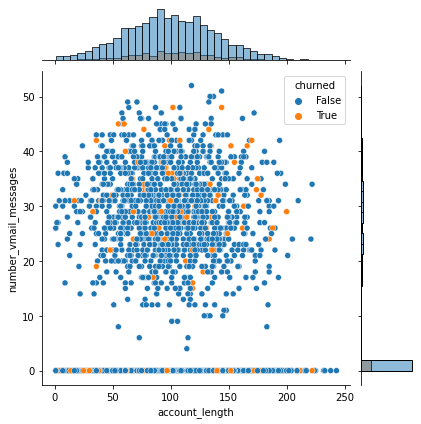
第二步:数据处理
观察原始数据可知:
-
数据共有5000个样本 -
每个样本有20个特征值,1个目标值 -
目标是只有两类,即只需要划分为两类
# 删除没有意义的特征值
raw_data.drop(['state', 'area_code', 'phone_number'], axis=1, inplace=True)
raw_data.head()
表格太大公众号显示有问题,大家可以在这个网站上看http://www.xiaoqing-cae.com/
# 数据中有些是浮点数,有些是类别如yes or no;需要将类别转换为数据
lb = LabelBinarizer()
for col in ['intl_plan', 'voice_mail_plan', 'churned']:
raw_data[col] = lb.fit_transform(raw_data[col])
# 分数据集为训练集和测试集
x_cols = [x for x in raw_data.columns if x != 'churned']
x_data = raw_data[x_cols]
y_data = raw_data['churned']
x_train, x_test, y_train, y_test = train_test_split(x_data,y_data, test_size=0.2, random_state=20)
特征工程
# 将所有的特征值转换至0~1范围内;特征值归一化处理
msc = MinMaxScaler()
x_train = msc.fit_transform(x_train)
x_test = msc.fit_transform(x_test)
训练模型与评估
# k从1~20;p从1~2;绘制精度的关系曲线
accuracy_s1 = []
accuracy_s2 = []
for i in range(1,30):
# 训练模型
knn = KNeiorsClassifier(n_neiors=i,p = 1)
knn = knn.fit(x_train, y_train)
# 评估模型准确率
score = knn.score(x_test, y_test)
accuracy_s1.append([i,score])
knn = KNeiorsClassifier(n_neiors=i,p = 2)
knn = knn.fit(x_train, y_train)
# 评估模型准确率
score = knn.score(x_test, y_test)
accuracy_s2.append([i,score])
# 绘制曲线
accuracy_s1 = np.array(accuracy_s1)
accuracy_s2 = np.array(accuracy_s2)
plt.figure()
#解决中文显示问题
plt.rcParams['font.sans-serif'] = ['KaiTi'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
plt.xlabel("k 值")
plt.ylabel("准确率")
plt.plot(accuracy_s1[:,0],accuracy_s1[:,1],label='p = 1')
plt.plot(accuracy_s2[:,0],accuracy_s2[:,1],label='p = 2')
plt.legend()
plt.show()
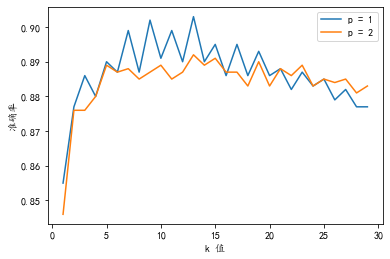
从上述分析可以可知:
-
k值为10~15预测的精度最高; -
p=1时精度比p=2时高; -
评估精度最高可以达到0.9。

 技术文档
技术文档
 推荐好文
推荐好文







 155-2731-8020
155-2731-8020