















































软件

产品


Dijistra算法(最短路径)
折半查找
适用于有序表
分块查找
①建立索引表,分块记录每一块的最大值
②在索引表中查找,确定是在哪一块
③块内进行顺序查找
平均查找长度:ASL=Lb+Lw(索引表+块内)
Lb = log2(n+1)(n:s总元素/每一块的元素 = 块)
Lw = (s/2)(s:总元素)
树表的查找
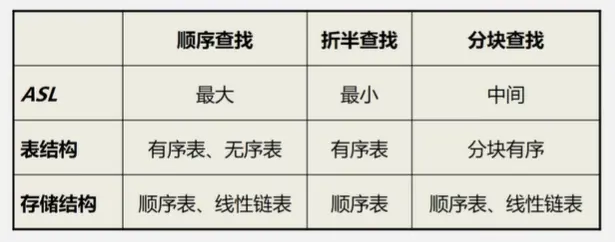
二叉排序树
左子树小于根、右子树大于等于根
中序遍历是递增有序的序列
递归查找
最多比较次数:数的深度
平均查找长度:和数的形态有关,O(log2n)
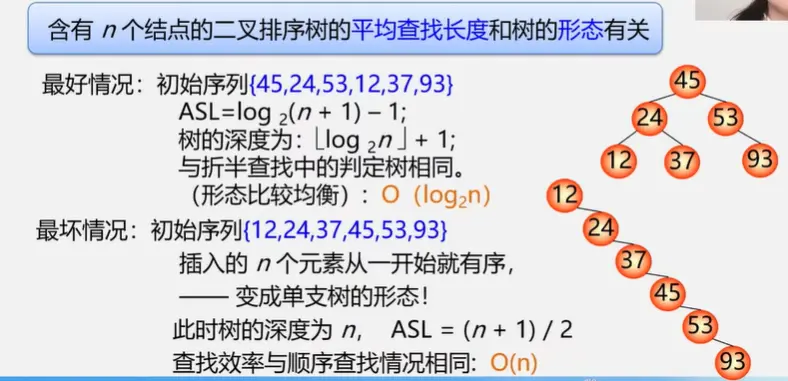
二叉排序树插入:都在叶结点上,修改指针,不需要移动元素
二叉排序树生成:依次插入,重复元素不插入
输入序列不同,生成的二叉树不一样,查找效率也不一样
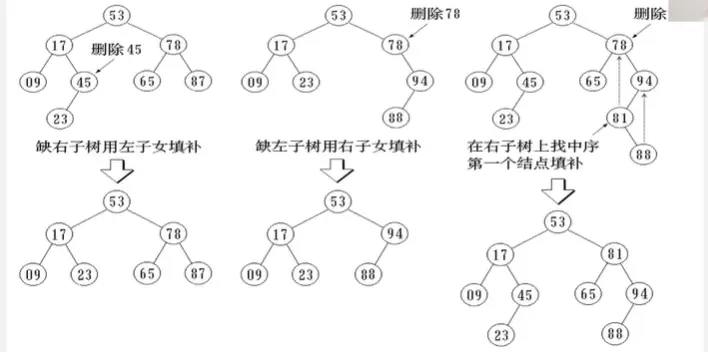
二叉排序树删除:
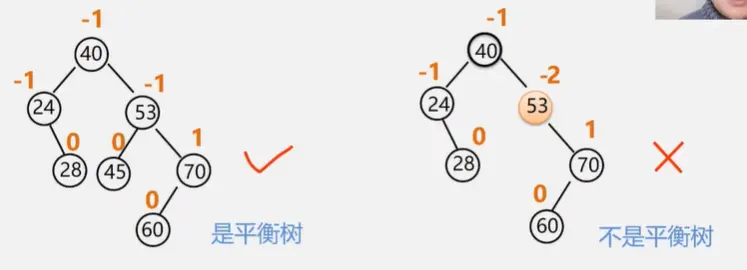
平衡二叉树(AVL)
平衡因子:左子树与右子树的高度差
BF = 结点左子树的高度 - 结点右子树的高度
BF = -1、0、1(就是平衡二叉树)
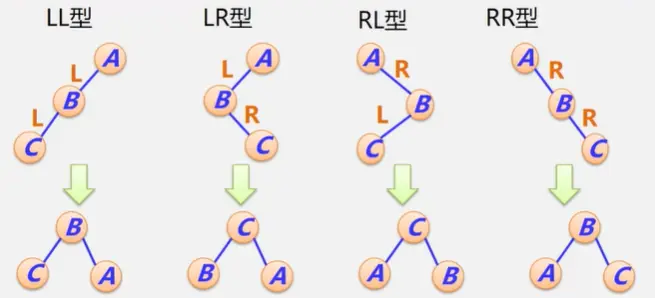
失衡二叉树的分析与调整(四种类型)
LL型、LR型、RL型、RR型
①降低树的高度
②保持二叉排序树的性质(左<根<右)
散列表
基本思想:记录的存储位置与关键字之间存在的对应关系
hash函数
看下面这个散列表:

根据散列函数来查找:H(key) = k
优点:查找效率高
缺点:空间效率低
例如:H(k) = k mod n(n:元素个数+1)
冲突:k1≠k2 但是H(k2)=H(k2)
减少冲突:优化散列函数
散列函数的构造方法需要考虑的问题:
直接定值法:关键字构成某种线性函数
解决冲突:如果找到的地址已经存储了值了,就移动到下一个地址
解决冲突的方法:
除留余数法:Hi = (Hash(key)+di) mod m(di为增量序列)
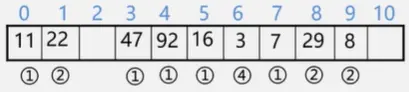
例如:{47,7,29,11,16,92,22,8,3}【线性探测法】
m=11 散列函数为:Hash(key) = key mod 11
链地址法:余数相同的链接在一个单链表上(头插法)
例如:{19,14,23,1,68,20,84,27,55,11,10,79}

优点:非同义词不会冲突,无聚集现象;适用表长不确定。
散列表的查找ASL:每个元素查找的次数之和 / 元素总个数


排序
排序方法的分类
按排序依据原则
排序算法的好坏
插入排序
插入排序:在有序序列中插入一个元素,保持序列有序
1.直接插入排序:顺序查找插入的位置,还可以使用哨兵模式
算法效率:比较+移动

2. 二分插入排序:查找插入位置时采用折半查找法,使用哨兵。
3. 希尔排序:分割若干个子序列,分别进行直接插入排序;定义递减的增量序列,比如5、3、1,最后一个增量必须为1

交换排序
交换排序:两两比较,如果发生逆序就交换
1.冒泡排序:每一趟不断将记录两两比较,并按“前小后大”规则交换

2.快速排序:任取一个元素为中心,所有比它小的元素一律前放,比它大的元素一律后放,形成左右子表(交替式逼近法,递归);
选择排序
1.简单选择排序:在等待排序的数据中选出最大(小)的元素放在其最终位置。
例如:直接选出最小的 放在第一个位置
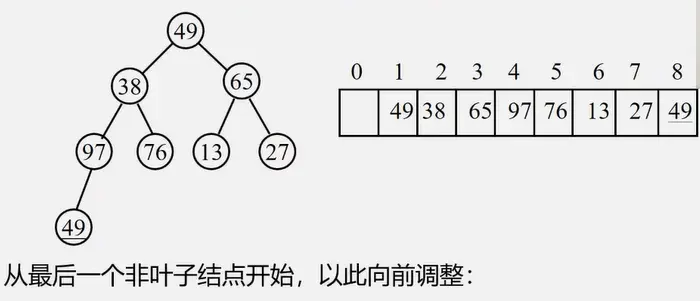
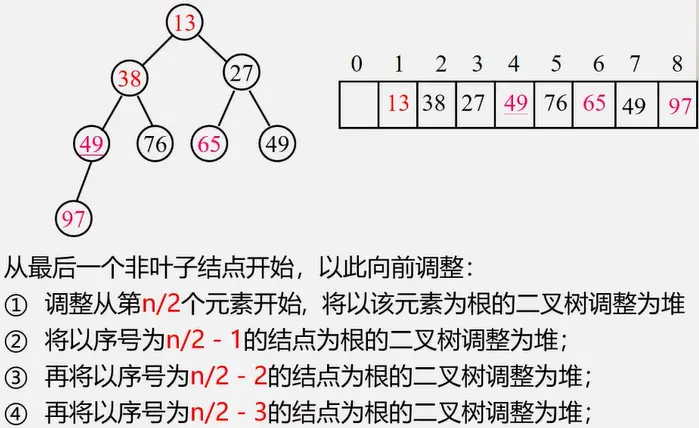
2.堆排序:
小根堆:根都小于等于左右结点
大根堆:根都大于等于左右结点
完全二叉树的非叶子结点(位置i):i > n/2
无序序列建立成一个堆: 将元素直接排成堆 然后再调整
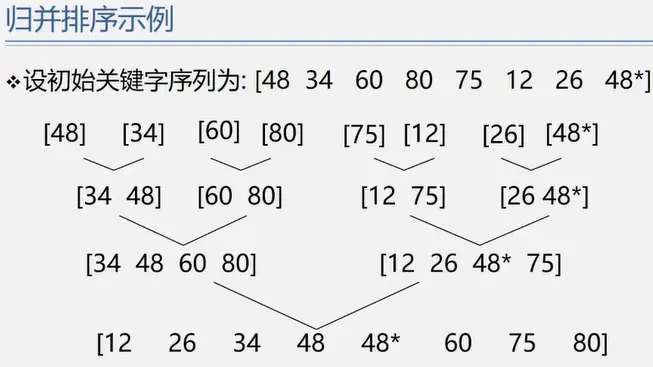
归并排序
归并排序:将两个或者两个以上的有序序列“归并”为一个有序序列。
1.二路归并排序
排序完成需要log2n次。
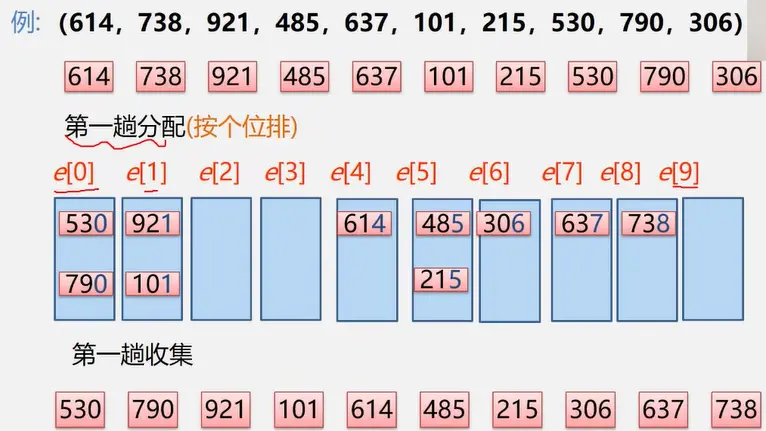
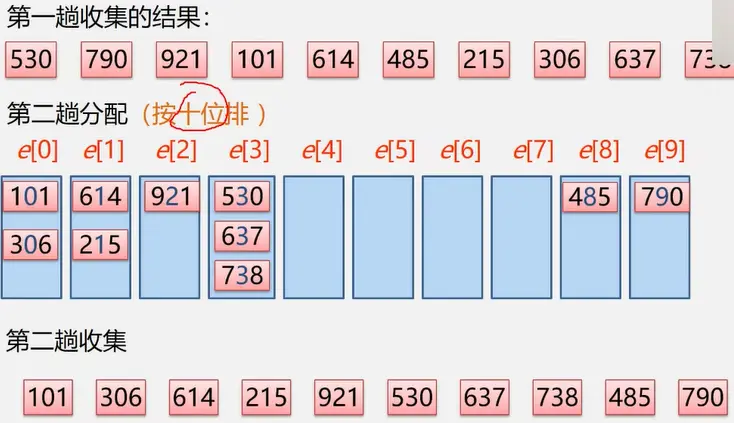
基数排序
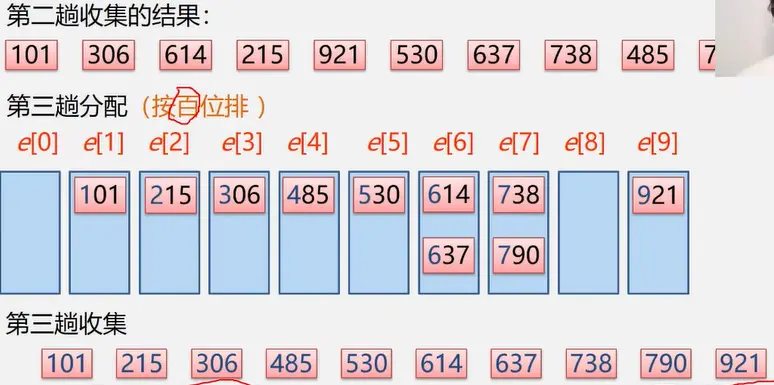
1. 基数排序:分配+收集
排序总结

武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















