















































软件

产品


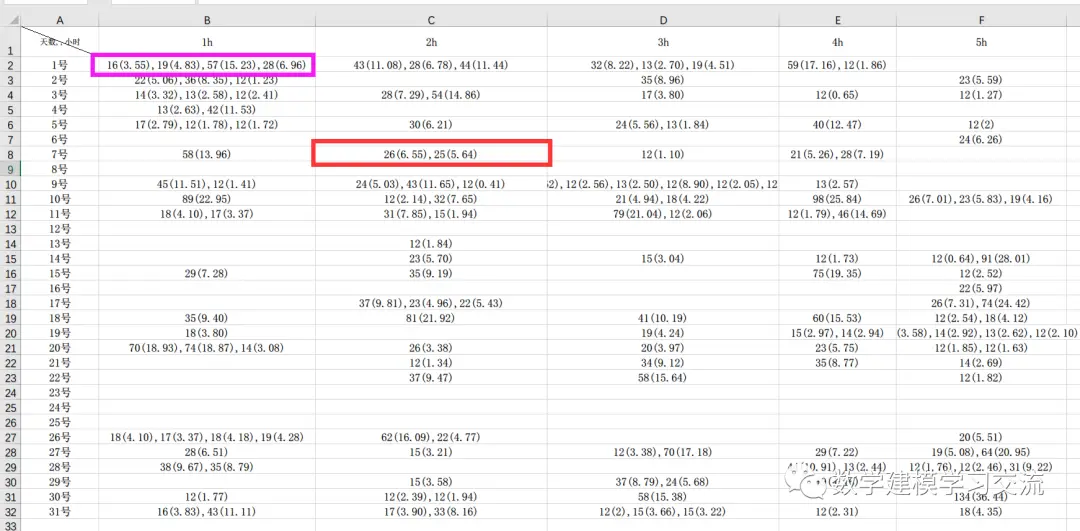
下表给出了某出租车司机某月每天各小时的跑单数据,每一行表示一天的数据,每一列表示某一个小时的数据。单元格中:括号前面的数值表示这一单对应的收入,括号内的数表示路程公里数。如果某个单元格为空,则说明该司机在这个小时没有接单。以1号的第1个小时为例,该出租车司机跑了四单,第一单收入为16元,路程公里数为3.55km;第二单收入为19元,路程公里数为4.83km;第三单收入为57元,路程公里数为15.23km;第四单收入为28元,路程公里数为6.96km。 类似的,7号的第2个小时中,该司机跑了两单,第一单收入为26元,路程公里数为6.55km;第二单收入为25元,路程公里数为5.64km。
数据表下载:https://wwi.lanzoup.com/iWqDd038c3vi
在线表格:https://docs.qq.com/sheet/DWU51Y2xiWUtxQmR1
问题:对上面的excel表格进行数据预处理,计算出每一天各小时的三个指标:(1)订单数 (2)收入 (3)路程公里数。请将这三个指标分别保存到三个矩阵中,矩阵的大小为31*24,其第i行第j列的元素表示第i号的第j个小时的计算结果。以第一天的第一个小时为例,矩阵的第一行第一列的数值分别为:4、120和30.57。(注:120=16+19+57+28、30.57=3.55+4.83+15.23+6.96)
下图是参考答案的部分截图,大家可以自行完成后对照:
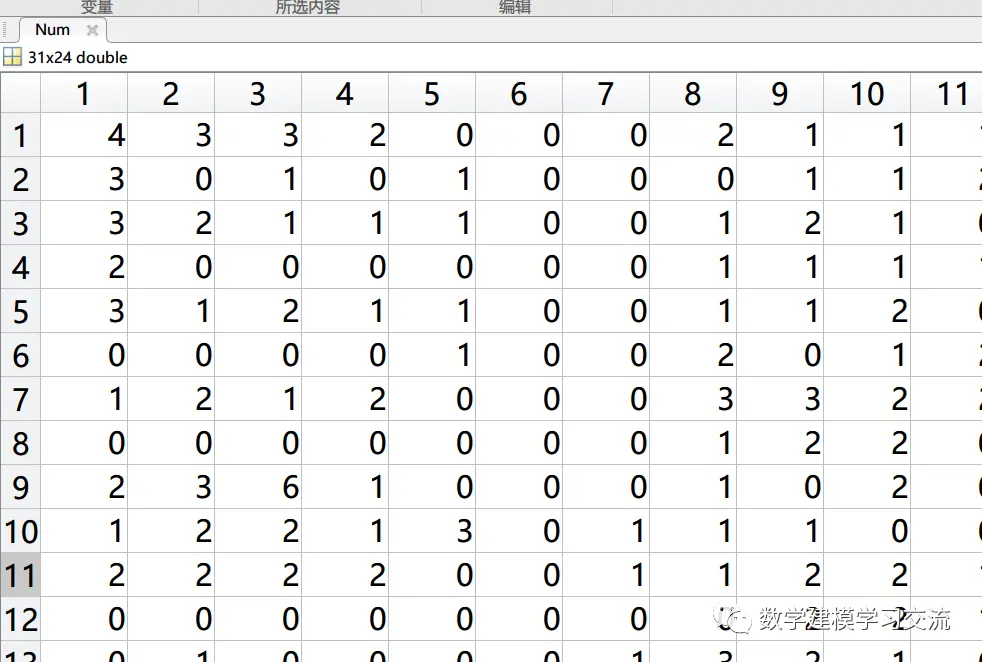
(1)订单数
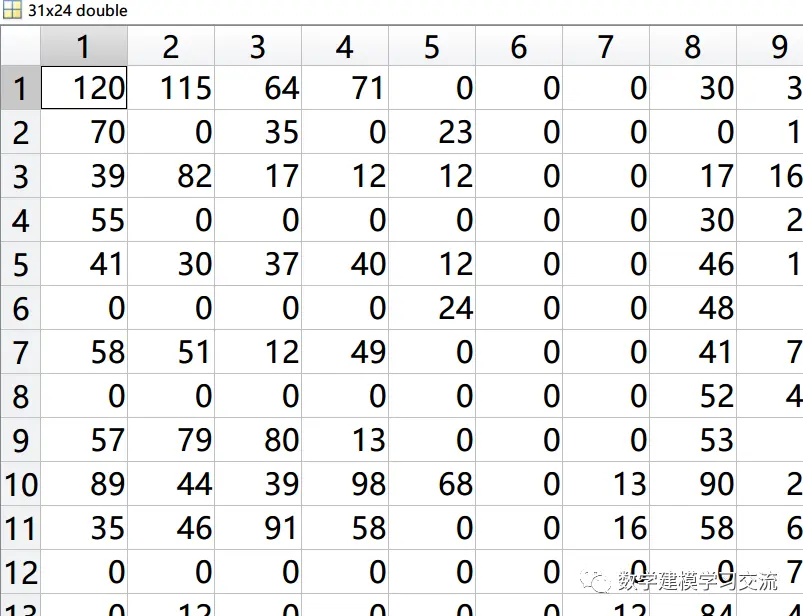
(2)收入
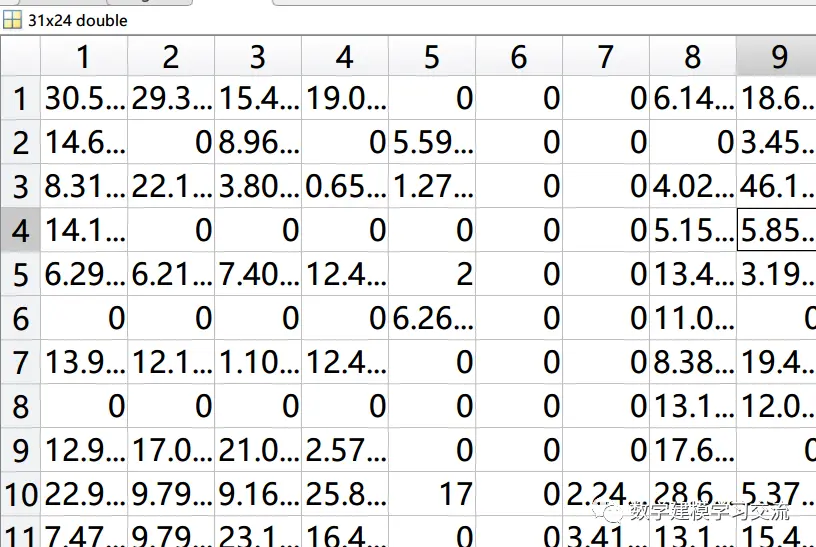
(3)路程公里数
下面给出分析思路和参考答案,大家可以先自己动手写写。
第一步:导入数据
在MATLAB中,导入excel数据的函数为xlsread,从MATLAB2019版本开始,MATLAB引入了新的导入数据的函数,并不再推荐使用xlsread.

这三个函数分别用于保存表格table类型、保存矩阵类型、保存元胞数组类型。其中,表格table类型在机器学习(微信公众号:《数学建模学习交流》查看历史文章)的视频中介绍过,类似于python中的pandas包。矩阵类型中的元素只能为数值型或者逻辑型的单个值,而元胞数组中包含的元素非常广泛,可以包含任意类型的数据,例如数值、文本、矩阵、表格等。
关于元胞数组的更多介绍,大家可查看MATLAB官网,这里我们不介绍很详细的基础知识:
https://ww2.mathworks.cn/help/matlab/cell-arrays.html
在元胞数组中,小括号()取值和大括号{}取值大家一定要重点关注,很容易搞错!基础不扎实的同学可以搜索相关的文章学习。
由于我们这里的数据比较简单,且单元格中包含的主要是文本,因此大家可以考虑将数据导入为元胞数组类型。
MATLAB2019版本之前的同学请使用xlsread函数读取数据:
[~, ~, data] = xlsread('附件.xlsx');如果你的版本更新,推荐使用readcell函数:
data = readcell("附件.xlsx");
导入进来的data的数据类型为cell,即元胞数组:
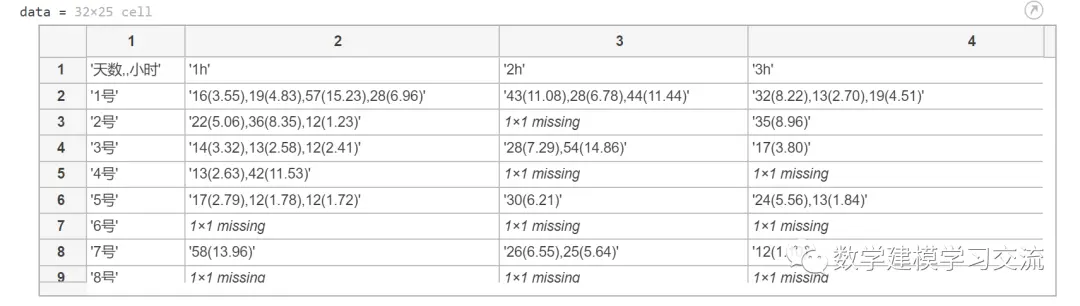
显然,第一行和第一列我们不需要,可通过下面的代码去除:
data = data(2:end,2:end);
去除后的结果如下:
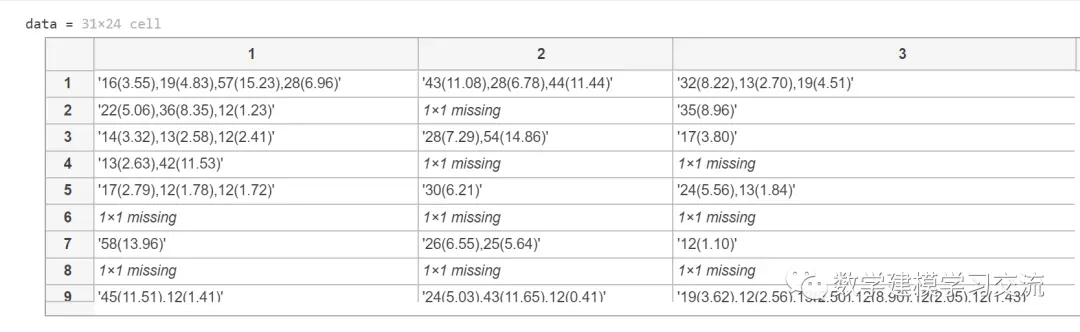
第二步:对每个单元格的元素分别处理
接下来的思路很简单,我们可以使用循环的方法,依次对每个单元格的元素进行处理。
这里我们先以第一行第一列的元素为例:
'16(3.55),19(4.83),57(15.23),28(6.96)'
我们需要先找到有几个订单,然后对每个订单分别提取出收入和里程公里数。
这个元素是一个字符数组(char类型),你可以就把它当成就是一个字符串,我们可以考虑对它进行分列(split函数),以英文的逗号对其进行分列,可以得到一个新的元胞数组,我们保存到tmp这个变量中,这个元胞数组中包含的元素个数就是这个小时的订单数:
tmp = data{1,1}
tmp = split(tmp,',')
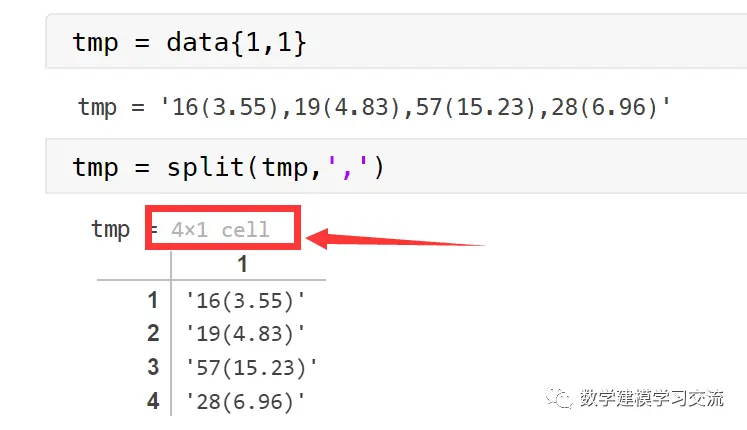
接下来,只需要对tmp中每个元素进行循环,下一个难点在于如何得到每笔订单的收入和公里数。
以这个元胞数组中的第一个元素为例:
'16(3.55)'
我们可以考虑先以小括号对其进行分列,然后分别处理小括号前和小括号后的数据。
tmp1 = tmp{1}
tmp2 = split(tmp1,'(')
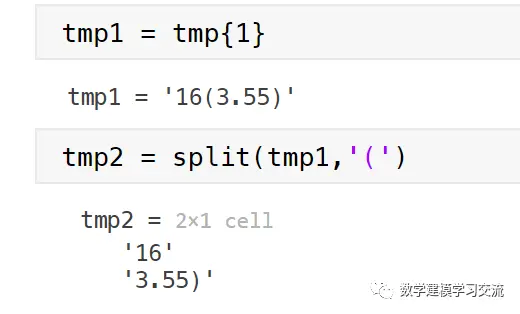
显然,tmp2中的第一个元素就是我们想要的收入,它现在还是一个字符数组类型,我们可以使用str2double函数将其转换成数值类型。
tmp2中的第二个元素是里程公里数,但它里面还有个右括号没有去除,我们可以考虑使用strrep函数来对字符进行替换,将原来的右括号替换为空字符串,然后再转换成数值类型。
str2double(tmp2{1})
tmp3 = strrep(tmp2{2},')','')
str2double(tmp3)

以上就是大致的思路,只需要把每一步的关系理清楚了,最后拼在一起就能得到最终的代码。
下面给出清风老师写的参考代码:
[~, ~, data] = xlsread('附件.xlsx');
% data = readcell("附件.xlsx"); % MATLAB2019以上可用这个
data = data(2:end,2:end);
[m,n] = size(data);
Wage = zeros(m,n); % 收入
Num = zeros(m,n); % 订单数
Dist = zeros(m,n); % 总路程公里
for ii = 1:m
for jj = 1:n
tmp = data{ii,jj};
if ~ismissing(tmp) % 只要tmp非空
tmp = split(tmp,','); % 字符串分割,得到元胞数组
Num(ii,jj) = length(tmp); % 订单数量
wage = zeros(Num(ii,jj),1);
dist = zeros(Num(ii,jj),1);
for kk = 1:Num(ii,jj)
tmp1 = tmp{kk};
tmp2 = split(tmp1,'(');
wage(kk) = str2double(tmp2{1});
tmp3 = strrep(tmp2{2},')','');
dist(kk) = str2double(tmp3);
end
Wage(ii,jj) = sum(wage);
Dist(ii,jj) = sum(dist);
end
end
end
上述代码中,多了一个判断data中的元素是否为缺失值或者为nan的情况,使用到的函数为ismissing,这个函数我们之前也介绍过,请看:缺失值和异常值的处理(微信公众号:《数学建模学习交流》查看历史文章),~就是取反的意思。
这个例题先介绍到这里,请大家课后自己编程完成,自己动手印象才会深刻。
进阶代码:使用cellfun函数避免循环
上面我们使用到了循环分别对元胞数组中的每一个元素进行了处理,事实上我们可以把这个处理过程封装为一个函数,然后直接调用MATLAB内置的cellfun函数来调用我们自己封装的这个函数,这样得到的结果和上面的循环版本完全相同,但代码会简洁很多。
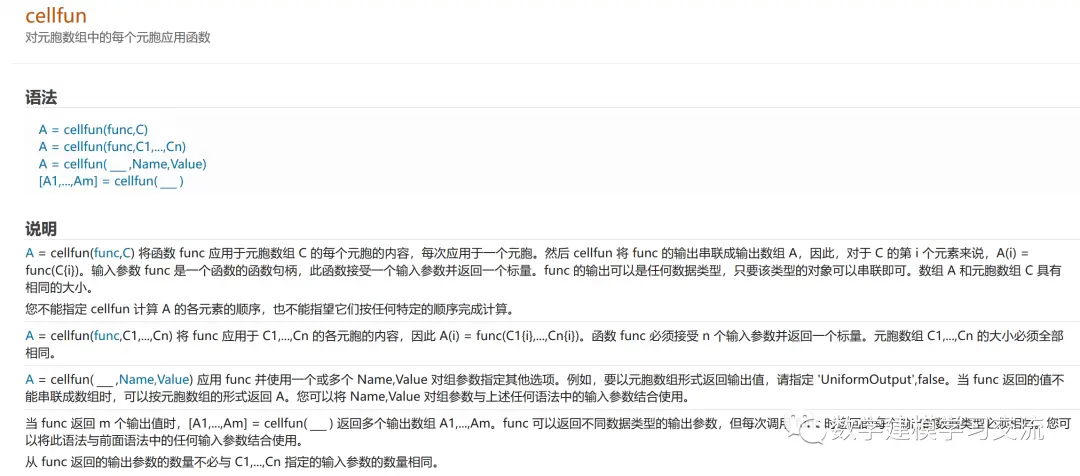
关于cellfun函数的用法,大家可以参考MATLAB官网的介绍:https://ww2.mathworks.cn/help/matlab/ref/cellfun.html 这里我直接给出代码,供学有余力的同学参考学习:前三行仍然是导入数据,第四行是核心,我们需要调用自己封装好的fun函数:
[~, ~, data] = xlsread('附件.xlsx');
% data = readcell("附件.xlsx"); % MATLAB2019以上可用这个
data = data(2:end,2:end);
[Wage,Num,Dist] = cellfun(@(x) fun(x),data);子函数,可将其保存为单独的m文件,命名为fun.m:
function [Wage,Num,Dist] = fun(tmp)
if ismissing(tmp)
Wage = 0;
Num = 0;
Dist = 0;
else
tmp = split(tmp,','); % 字符串分割,得到元胞数组
Num = length(tmp); % 订单数量
wage = zeros(Num,1);
dist = zeros(Num,1);
for kk = 1:Num
tmp1 = tmp{kk};
tmp2 = split(tmp1,'(');
wage(kk) = str2double(tmp2{1});
tmp3 = strrep(tmp2{2},')','');
dist(kk) = str2double(tmp3);
end
Wage = sum(wage);
Dist = sum(dist);
end
end
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















