















































软件

产品


RFM数据是指最近一次消费,消费频率以及消费金额,分别构成R,F,M,给定200行用户行为数据,我们用模糊C均值聚类进行分析
首先简单介绍一下模糊C均值聚类,每一个样本距各个聚类中心(初始聚类中心需要随机指定)都有一个隶属度,每一个样本至各个聚类的隶属度总和为1。
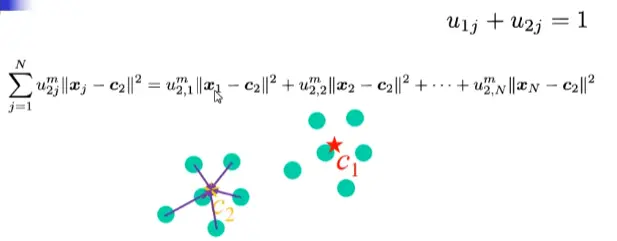
通过每次随机分配,取均值等方法,在层层迭代过程中,寻找聚类中心,使得每个样本到每个聚类中心的距离值最小化,所计算的聚类结果就是我们的目标。

目标方程值最小化
MBA智库对于RFM有着详细的解释,link:https://wiki.mbalib.com/zh-tw/RFM%E6%A8%A1%E5%9E%8B
模糊C均值聚类的详细说明可以参见:https://wiki.mbalib.com/zh-tw/RFM%E6%A8%A1%E5%9E%8B
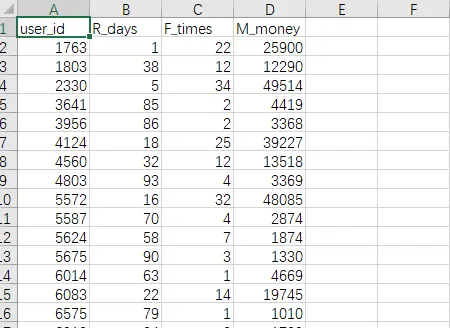
下面给出RFM数据
接下来我们用欧式距离定义的方法,计算用户特征向量与聚类中心的距离值:
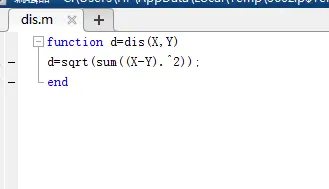
两个向量相减,求平方,再求和,最后开方
接下来就是数据预处理,因为R,F,M分别代表的含义不同,单位也不同,因此要实现数据的无量纲化,我们采用归一化处理。即数据减去最小值,再除以最大值与最小值的差值
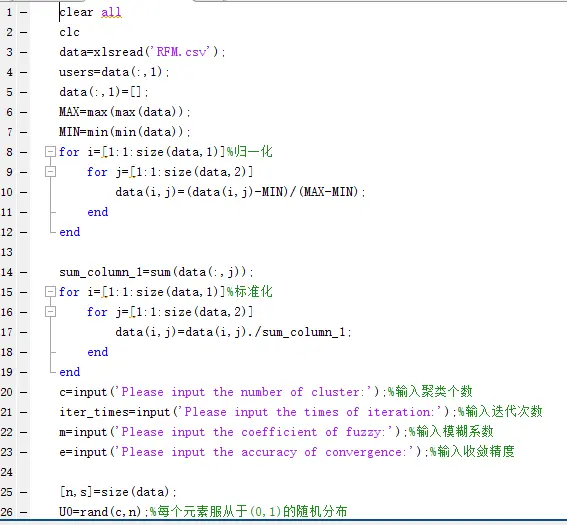
最后,我们设定以下参数:

即聚类数目,迭代次数,模糊系数(要求大于1),以及精度。
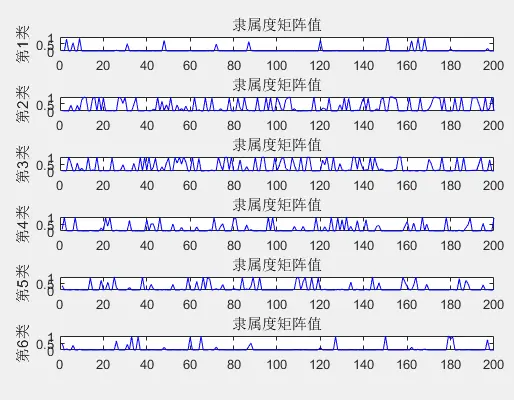
最后看一下各个用户(即样本数据)对于各个类别的归属度,可以直观反应用户u对N个类别的隶属度
我们用表格查看:

可见,用户1隶属于6类,用户2隶属于类别4等等。
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















