















































软件

产品


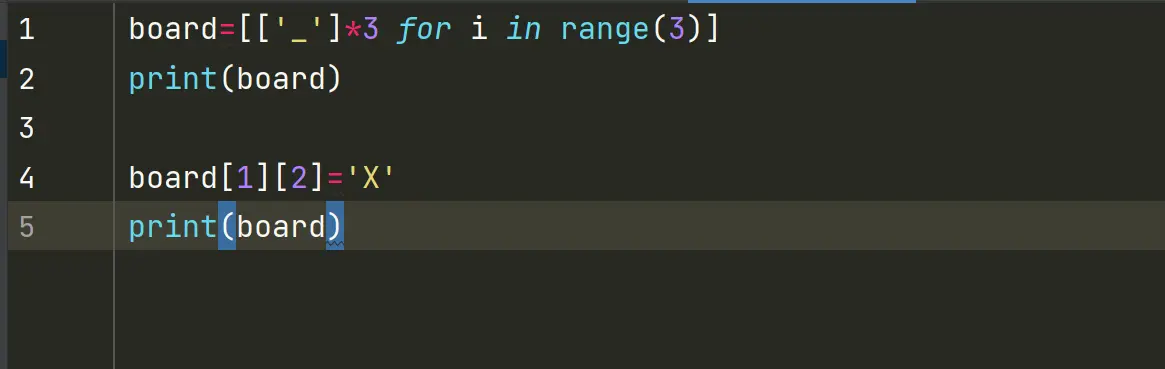
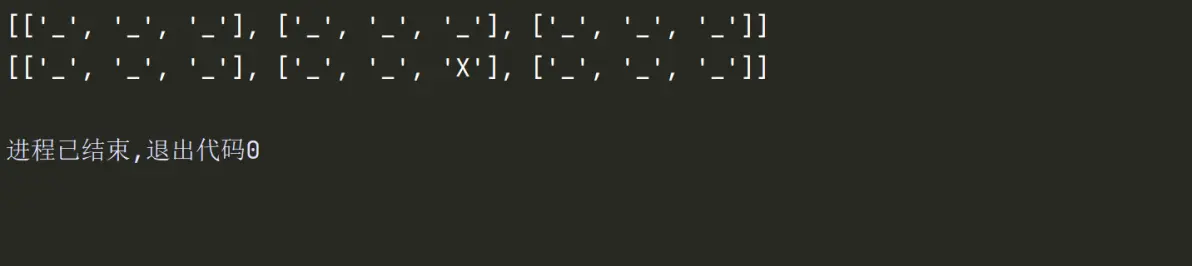
2.4切片
4.给切片赋值
如果把切片放在赋值语句的左边,或把它作为del操作的对象,我们就可以对序列进行嫁接,切除或就地修改。
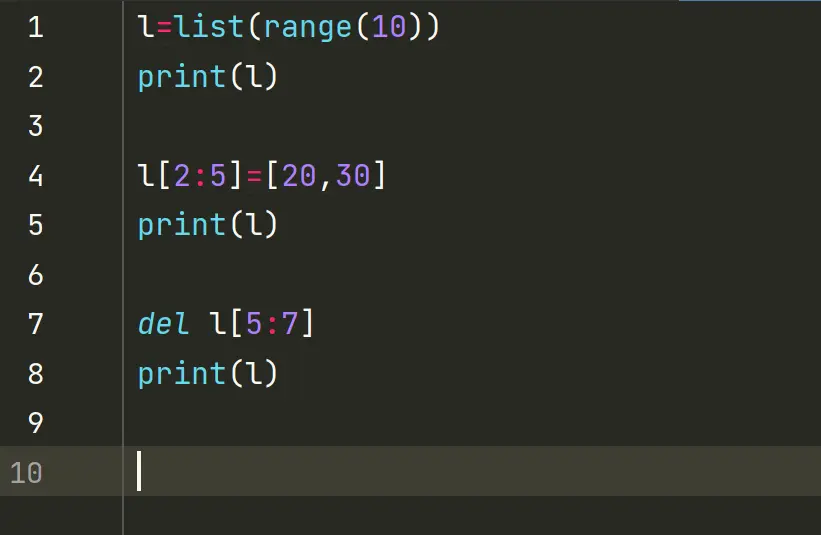
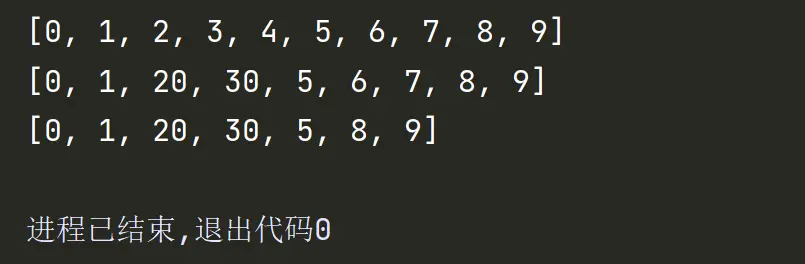
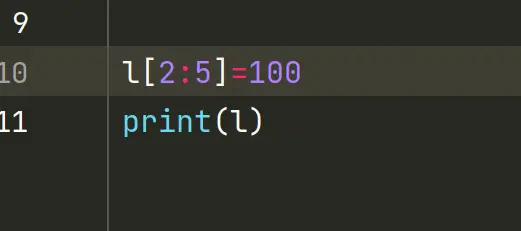

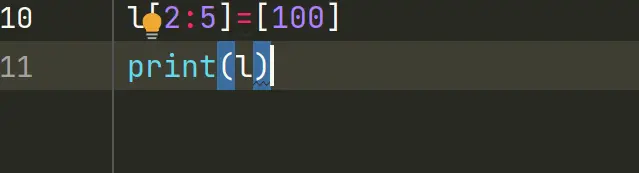

如果赋值对象是一个切片,那么赋值语句的右侧必须是一个可迭代对象。
2.5对序列使用+和*
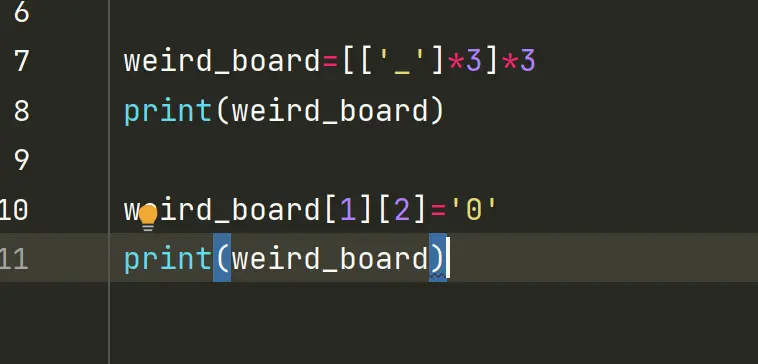
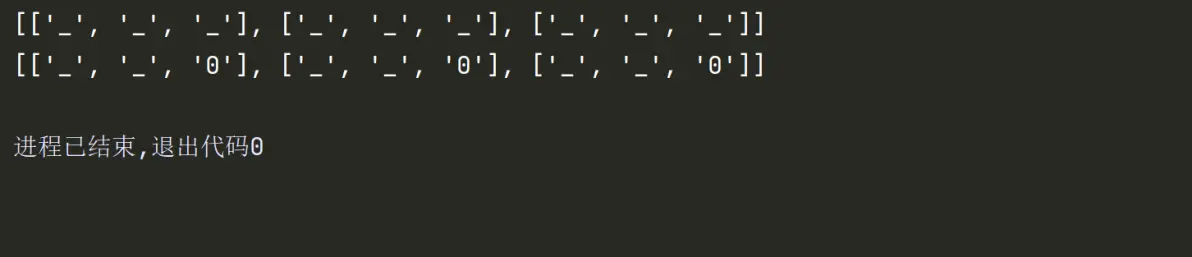
以下将展示一个诱人的捷径,但是实际上是错的
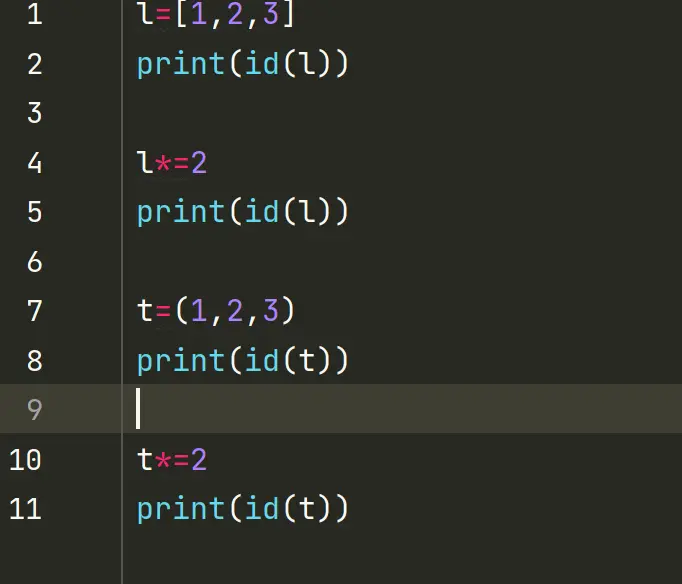
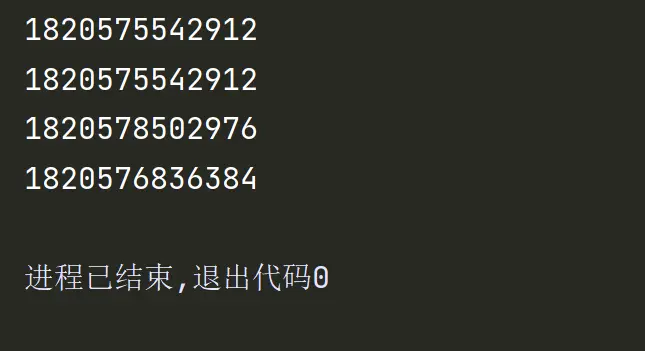
2.6序列的增量赋值
2.7list.sort方法和内置函数sorted
list.sort方法会就地排序列表,也就是说不会把原列表赋值一份,这也是这个方法返回None的原因,如果一个函数 或者方法对对象进行的是就地改动,那它就应该返回 None,好让调用者知道传入的参数发生了变动,而且并未产生新的对象。 与 list.sort 相反的是内置函数 sorted,它会新建一个列表作为返回 值。这个方法可以接受任何形式的可迭代对象作为参数,甚至包括不可变序列或生成器。而不管 sorted 接受的是怎样的参数,它最后都会返回一个列表。(都有两个参数,一个reverse和key,reverse=True,则被排序的序列会以降序输出;key,一个只有一个参数的函数,这个函数会被用在序列里的每一个元素 上,所产生的结果将是排序算法依赖的对比关键字。可选参数 key 还可以在内置函数 min() 和 max() 中起作用。 另外,还有些标准库里的函数也接受这个参数,像 itertools.groupby() 和 heapq.nlargest() 等。
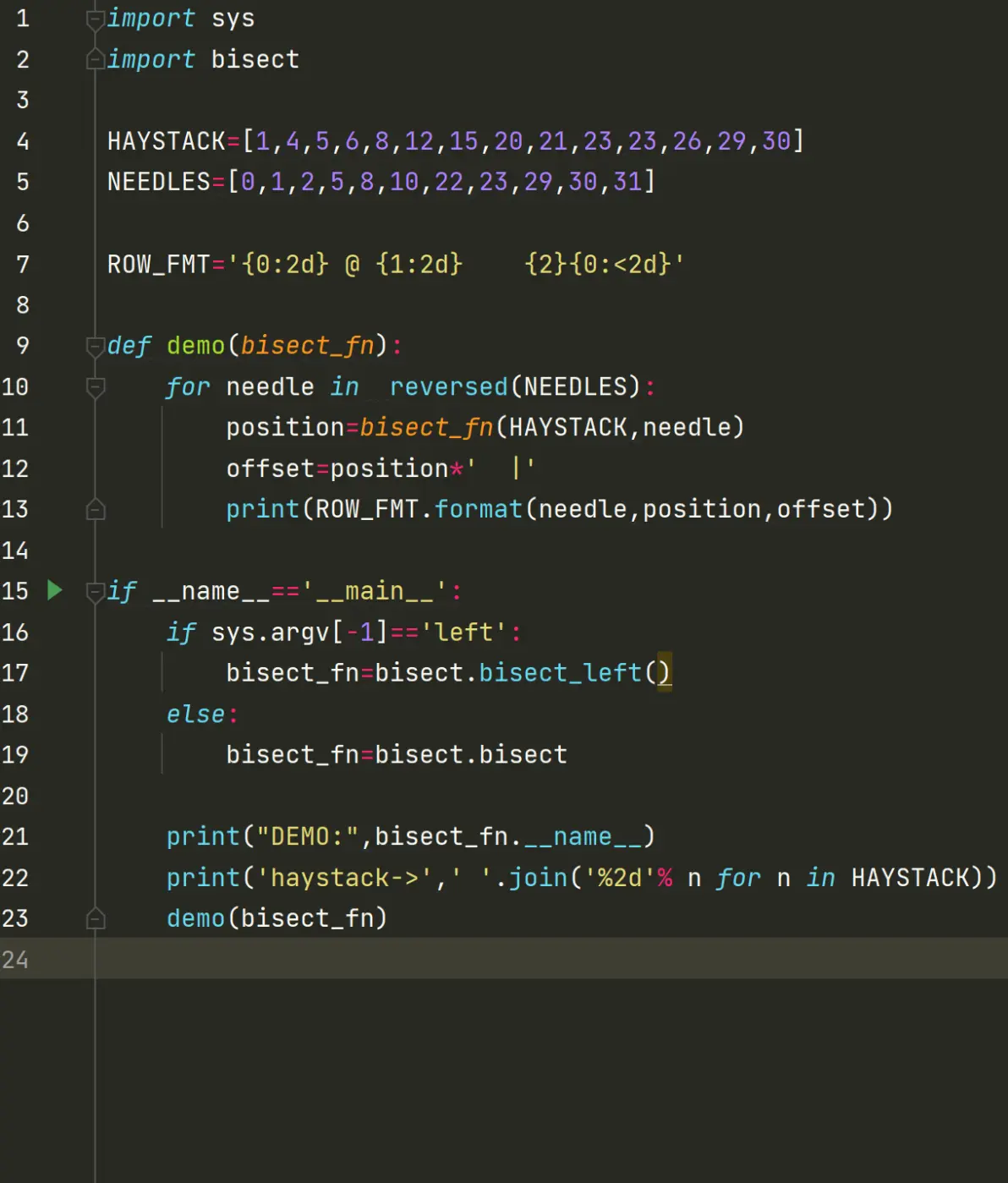
2.8用bisect来管理已排序的序列
bisect(haystack, needle)咋 haystack中搜索neeedle的位置,该位置满足的条件是,把呢饿死了插入这个位置之后,haystack还能保存升序。也就是再说这个汗珠返回的位置前面的值,都小于或等于needle,你可以先用 bisect(haystack, needle) 查找位置 index,再 用 haystack.insert(index, needle) 来插入新值。但你也可用 insort 来一步到位,并且后者的速度更快一些。(插入之后还是有序序列)

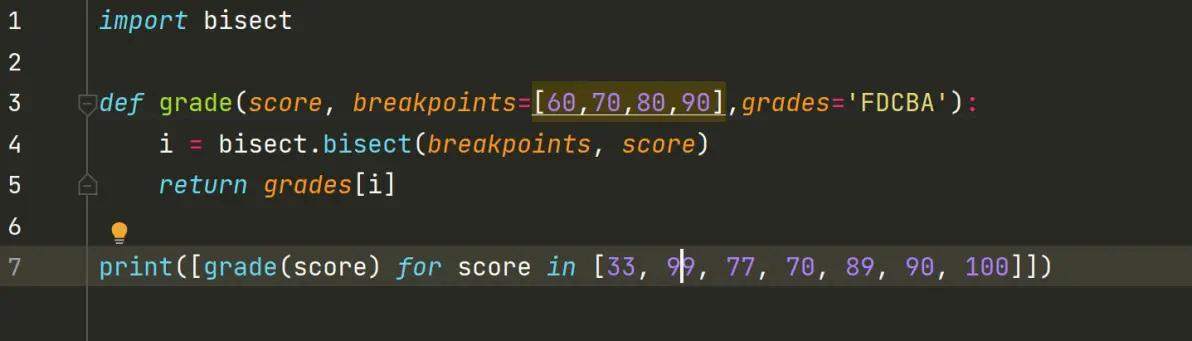
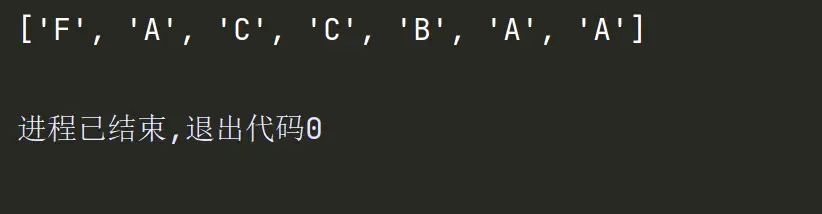
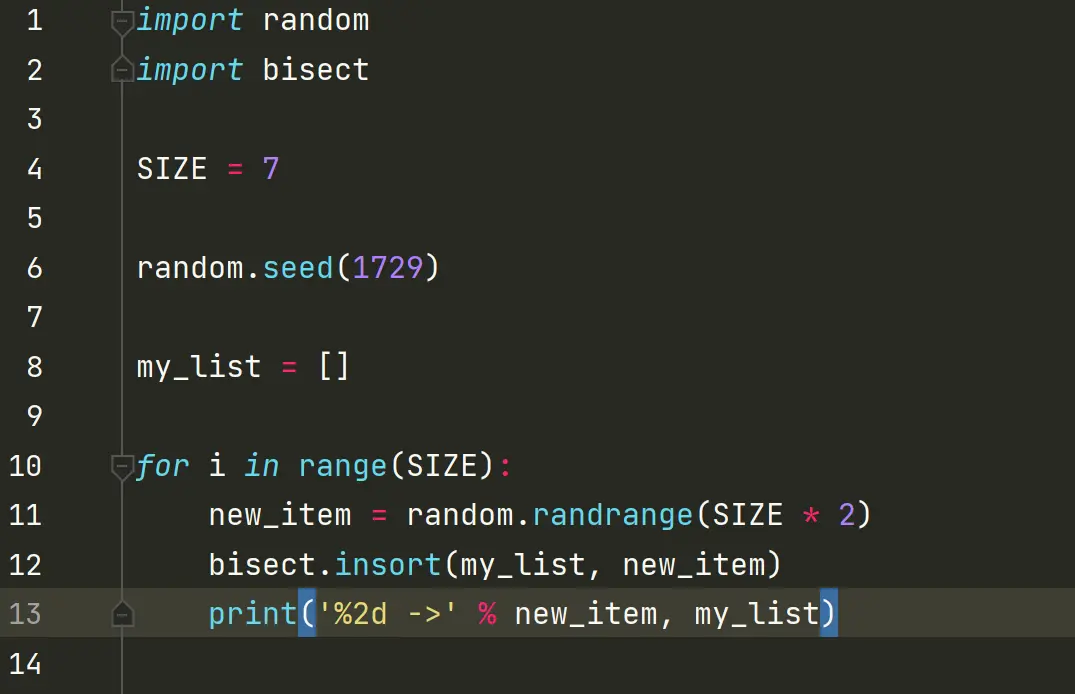
2.用bisect.insort来插入新元素
insort(seq, item) 把变量 item 插入到序列 seq 中,并能保持 seq 的升序顺序。
2.1random.seed() 会改变随机生成器的种子;传入的数值用于指定随机数生成时所用算法开始时所选定的整数值,如果使用相同的seed()值,则每次生成的随机数都相同;如果不设置这个值,则系统会根据时间来自己选择这个值,此时每次生成的随机数会因时间的差异而有所不同。

武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















