















































软件

产品


顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律。
我们知道,在机器学习中,有三种不同的学习模式:监督学习、无监督学习和强化学习:
k 均值聚类是一种无监督学习方法。
还记得哈利波特故事中的分院帽吗?那就是聚类,将新学生(无标签)分成四类:格兰芬多、拉文克拉、赫奇帕奇和斯特莱林。
人是非常擅长分类的,聚类算法试图让计算机也具备这种类似的能力,聚类技术很多,例如层次法、贝叶斯法和划分法。k 均值聚类属于划分聚类方法,将数据分成 k 个簇,每个簇有一个中心,称为质心,k 值需要给定。
k 均值聚类算法的工作原理如下:
使用 TensorFlow 的 Estimator 类 KmeansClustering 来实现 k 均值聚类,具体实现可参考,可以直接进行 k 均值聚类和推理。根据 TensorFlow 文档,KmeansClustering 类对象可以使用以下__init__方法进行实例化:

TensorFlow 文档对这些参数的定义如下:
配置:请参阅 Estimator。
TensorFlow 支持将欧氏距离和余弦距离作为质心的度量,KmeansClustering 类提供了多种交互方法。在这里使用 fit()、clusters() 和 predict_clusters_idx() 方法:

根据 TensorFlow 文档描述,需要给 fit() 提供 input_fn() 函数,cluster 方法返回簇质心,predict_cluster_idx 方法返回得到簇的索引。



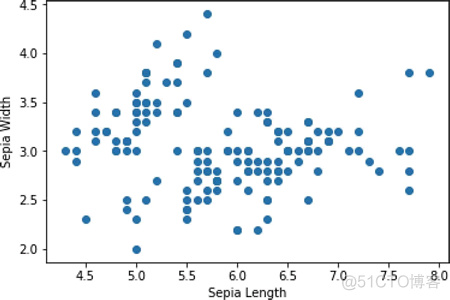
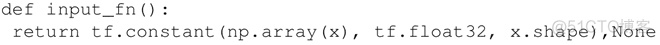



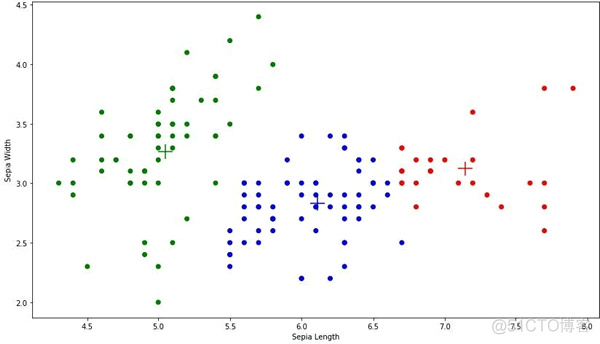
其中“+”号代表三个簇的质心。
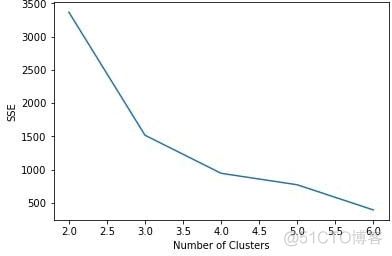
上面的案例中使用 TensorFlow Estimator 的 k 均值聚类进行了聚类,这里是提前知道簇的数目,因此设置 num_clusters=3。但是在大多数情况下,数据没有标签,我们也不知道有多少簇存在,这时候可以使用肘部法则确定簇的最佳数量。
肘部法则选择簇数量的原则是减少距离的平方误差和(SSE),随着簇数量 k 的增加,SSE 是逐渐减小的,直到 SSE=0,当k等于数据点的数量时,每个点都是自己的簇。
这里想要的是一个较小的 k 值,而且 SSE 也较小。在 TensorFlow 中,可以使用 KmeansClustering 类中定义的 score() 方法计算 SSE,该方法返回所有样本点距最近簇的距离之和:
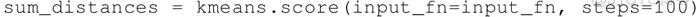
对于鸢尾花卉数据,如果针对不同的 k 值绘制 SSE,能够看到 k=3 时,SSE 的变化是最大的;之后变化趋势减小,因此肘部 k 值可设置为 3:
k 均值聚类因其简单、快速、强大而被广泛应用,当然它也有不足之处,最大的不足就是用户必须指定簇的数量;其次,算法不保证全局最优;再次,对异常值非常敏感。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















