















































软件

产品


1.算法概述

假设我们的行为准则已经学习好了, 现在我们处于状态s1, 我在写作业, 我有两个行为 a1, a2, 分别是看电视和写作业, 根据我的经验, 在这种 s1 状态下, a2 写作业 带来的潜在奖励要比 a1 看电视高, 这里的潜在奖励我们可以用一个有关于 s 和 a 的 Q 表格代替, 在我的记忆Q表格中, Q(s1, a1)=-2 要小于 Q(s1, a2)=1, 所以我们判断要选择 a2 作为下一个行为. 现在我们的状态更新成 s2 , 我们还是有两个同样的选择, 重复上面的过程, 在行为准则Q 表中寻找 Q(s2, a1) Q(s2, a2) 的值, 并比较他们的大小, 选取较大的一个. 接着根据 a2 我们到达 s3 并在此重复上面的决策过程. Q learning 的方法也就是这样决策的. 看完决策, 我看在来研究一下这张行为准则 Q 表是通过什么样的方式更改, 提升的.
Q-Learning它是强化学习中的一种 values-based 算法,是以QTable表格形式体现,在学习中遇到的任何操作存入QTable中,根据之前的学习选择当前最优操作,也可以根据设置的e_greedy机率随机选择。
Q-Learning的QTable标签更新公式:
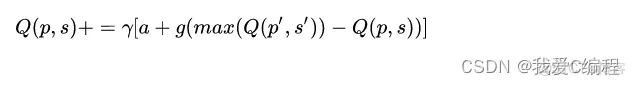
Q-Learning的计算步骤:
1.判断在当前位置可以有几种操作;
2.根据当前位置允许的操作选择一个操作;
3.根据选择的操作进行奖赏;
4.修改当前行为的本次操作权重;
2.仿真效果预览
matlab2022a仿真测试如下:
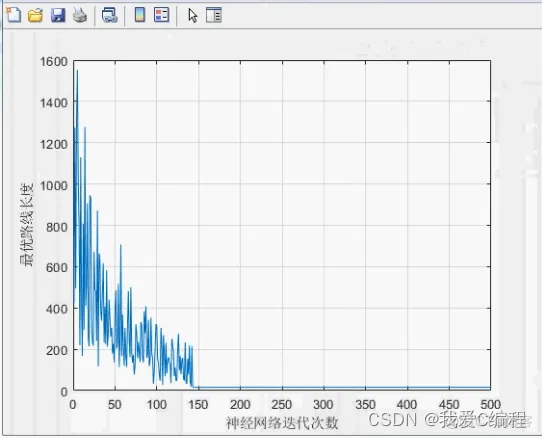
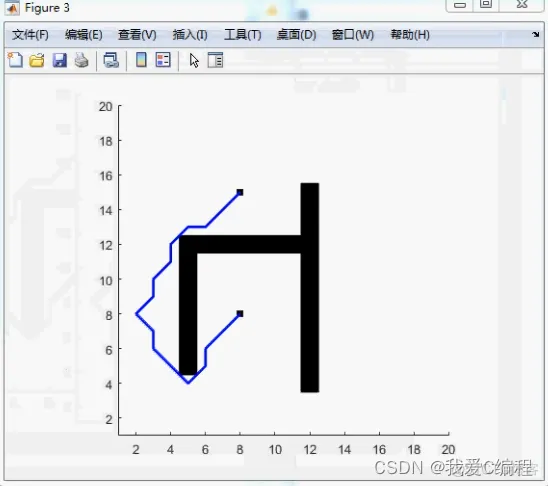
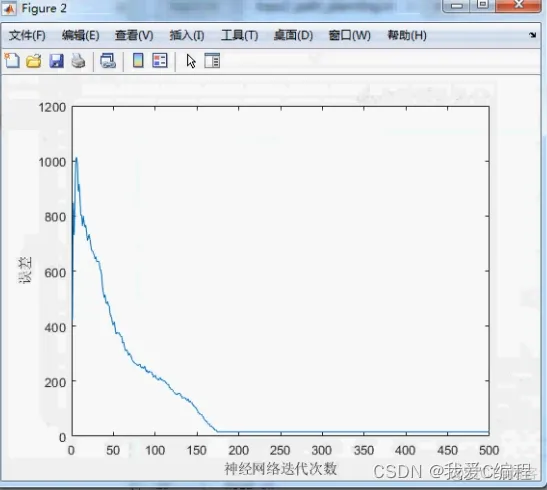
3.核心MATLAB代码预览
for i=1:pathtimes
i
Positions = stpt;
drivers = 0; %开车
E = zeros(prod([driver_actions Xscale Yscale]),1);
for j=1:maxiter
%计算训练驾驶策略
if j>=2
Choice = ndi2lin([1 Positions(1) Positions(2)],[driver_actions Xscale Yscale]);
Choice2 = ndi2lin([drivers Prestate(1) Prestate(2)],[driver_actions Xscale Yscale]);
delta = feedback + cb*max(NNPolicy(Choice:Choice+driver_actions-1))-NNPolicy(Choice2);
E(Choice2) = 1;
NNPolicy = NNPolicy + ca*delta*E;
E = cb*lambda*E*~exploring;
end
%选择动作
Choice = ndi2lin([1 Positions(1) Positions(2)],[driver_actions Xscale Yscale]);
Choice = [Choice:Choice+driver_actions-1];
tmps = find(NNPolicy(Choice) == max(NNPolicy(Choice)));
%是否转向
drivers = tmps(ceil(rand * length(tmps)));
%探索策略
if rand<LR
drivers=floor(rand*driver_actions)+1;
exploring = 1;
else
exploring = 0;
end
LR=LR/pathtimes;
Prestate=Positions;
[Positions,feedback] = nomancar(Positions,drivers,driver_direction,map_route,Xscale,Yscale);
if edpt(1)==Positions(1) & edpt(2)==Positions(2)
break
end
end
Itertion_times(k)=j;
if k>32
Error(k)=mean(Itertion_times(length(Itertion_times)-32+1:length(Itertion_times)));
else
Error(k)=mean(Itertion_times(1:length(Itertion_times)));
end
k=k+1;
end
A_005
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















