















































软件

产品


最近在阿里云数加平台上学习一下机器学习,把学习中整理的 资料 记录于此,已备查看,以下资料主要是概念解释及应用。
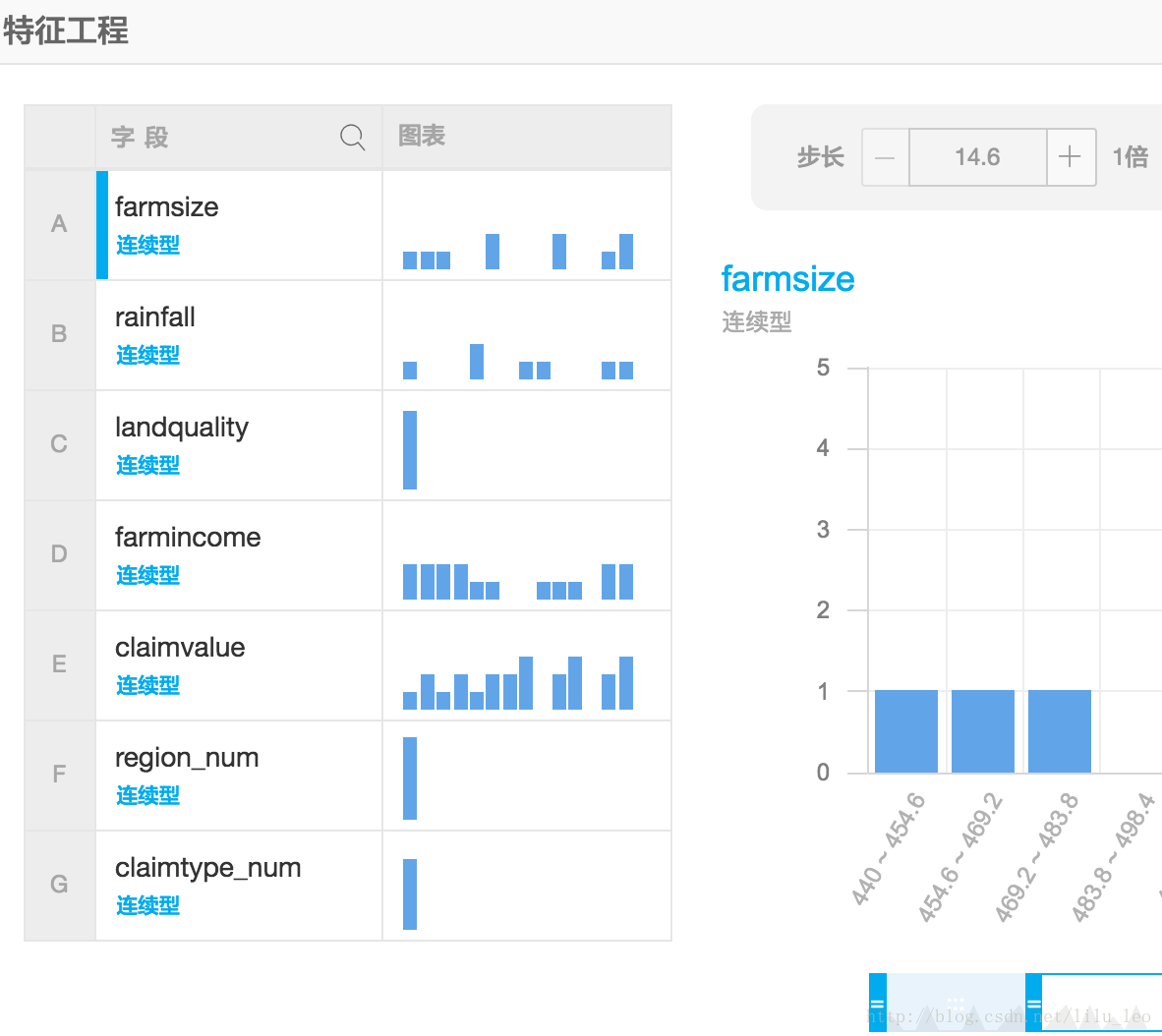
大数据通用可视化控件,提供所选择字段的直方图,如下图所示:
相关系数 算法 用于计算一个矩阵中每一列之间的协方差 (变化趋势相同,协方差为正,变化趋势相反,协方差为负,如果相互独立,则数值为0,但数值为0,不一定是相互独立)协方差矩阵计算的是不同维度之间的协方差,而不是不同样本之间的。
计算公式:
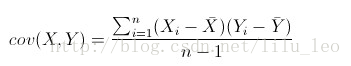
在维基百科中,协方差的定义:
协方差(Covariance)在概率论和统计学中用于衡量两个变量的总体误差。而方差是协方差的一种特殊情况,即当两个变量是相同的情况。

协方差
https://zh.wikipedia.org/wiki/%E5%8D%8F%E6%96%B9%E5%B7%AE
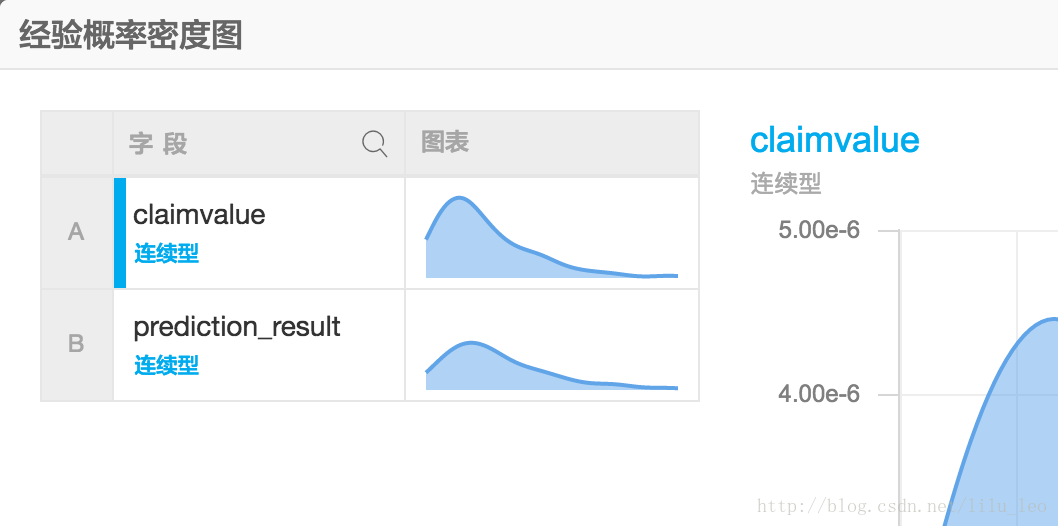
概率密度函数的维基百科定义如下:
在数学中,连续型随机变量的概率密度函数(在不至于混淆时可以简称为密度函数)是一个描述这个随机变量的输出值,在某个确定的取值点附近的可能性的函数。而随机变量的取值落在某个区域之内的概率则为概率密度函数在这个区域上的积分。当概率密度函数存在的时候,累积分布函数是概率密度函数的积分。概率密度函数一般以大写“PDF”(Probability Density Function)标记[1]。 概率密度函数有时也被称为概率分布函数,但这种称法可能会和累积分布函数或概率质量函数混淆。
在数加平台上,效果图如下:
分别计算全表的每个字段的统计信息,包括缺省值、最大最小值、方差、偏值等等。
表中各字段意义:
因为我们常常会将随机变量(先假定有任意阶矩)作一个线性变换,把一阶矩(期望)归零,二阶矩(方差)归一,以便统一研究一些问题。这时候,在同样期望为0方差为1的标准情况下(以下均假设随机变量满足该条件),随机变量最重要的指标就变成了接下来的两个矩了。 三阶矩,就是我们所称的「偏度」。粗略来说,一个典型的正偏度变量X的分布满足这样的特征:很大的概率X会取绝对值较小的负值,但在极少数情况下,X会取特别大的正值。可以理解为「一般为负,极端值为正」。典型的正偏度投资,就是彩票和保险:一般来说,你花的那一点小钱就打水漂了,但是这一点钱完全是在承受范围内的;而这点钱则部分转化为小概率情况下的巨大收益。而负偏度变量则正好相反,「一般为正,极端值为负」,可以参照一些所谓的「灰色产业」:一般情况下是可以赚到一点钱的,但是有较小的概率「东窗事发」,赔得血本无归。 四阶矩,又称峰度,简单来说相当于「方差的方差」,和偏度类似,都可以衡量极端值的情况。峰度较大通常意味着极端值较常出现,峰度较小通常意味着极端值即使出现了也不会「太极端」。峰度是大还是小通常与3(即正态分布的峰度)相比较。 至于为什么五阶以上的矩没有专门的称呼,主要是因为我们习惯的线性变换,只有两个自由度,故最多只能将前两阶矩给「标准化」。这样,标准化以后,第三、第四阶的矩就比较重要了,前者衡量正负,后者衡量偏离程度,与均值、方差的关系类似。换句话说,假如我们能把前四阶矩都给「标准化」了,那么五阶、六阶的矩就会比较重要了吧。
卡方检验是比较您数据的实测分布与数据的预期分布的假设检验。 有多种类型的卡方检验: 卡方拟合优度检验 使用此分析检验分类数据样本与某个理论分布的拟合程度。 例如,通过多次掷骰子并使用卡方拟合优度检验来确定结果是否服从均匀分布,可以检验骰子是否是正 6 面形的。在此情况下,卡方统计量会将计数的实测分布不同于假设分布的程度进行量化。 相关性和独立性的卡方检验 这些检验的计算方法都相同,但您尝试回答的问题可能会有所不同。 相关性检验:使用相关性检验确定一个变量是否与另一个变量相关。例如,确定不同颜色汽车的销量是否取决于在哪个城市销售它们。 独立性检验:使用独立性检验确定一个变量的观测值是否取决于另一个变量的观测值。例如,确定某人投票的候选人是否与投票人的性别无关。
在维基百科中,卡方拟合性检验有如下定义:
卡方拟合性检验是检验单个多项分类名义型变量各分类间的实际观测次数与理论次数之间是否一致的问题,其零假设是观测次数与理论次数之间无差异。 它在分类资料统计推断中的应用,包括:两个率或两个构成比比较的卡方检验;多个率或多个构成比比较的卡方检验以及分类资料的相关分析等。
(英语:Pearson’s chi-squared test)是最有名卡方检验之一(其他常用的卡方检验还有叶氏连续性校正、似然比检验、一元混成检验等等--它们的统计值之概率分配都近似于卡方分配,故称卡方检验)。“皮尔森卡方检验”最早由卡尔·皮尔森在1900年发表,[1] 用于类别变数的检验。科学文献中,当提及卡方检验而没有特别指明类型时,通常即指皮尔森卡方检验。
minitab support
http://support.minitab.com/zh-cn/minitab/17/topic-library/basic-statistics-and-graphs/tables/chi-square/what-is-a-chi-square-test/
minitab wiki
http://wiki.mbalib.com/wiki/%E5%8D%A1%E6%96%B9%E6%A3%80%E9%AA%8C
wikipedia
https://zh.wikipedia.org/wiki/%E7%9A%AE%E7%88%BE%E6%A3%AE%E5%8D%A1%E6%96%B9%E6%AA%A2%E5%AE%9A
枚举 类 变量与连续变量的箱线图,扰动点图
箱形图(英文:Box-plot),又称为盒须图、盒式图、盒状图或箱线图,是一种用作显示一组数据分散情况资料的统计图。因型状如箱子而得名。在各种领域也经常被使用,常见于品质管理。不过作法相对较繁琐。
wikipedia
https://zh.wikipedia.org/wiki/%E7%AE%B1%E5%BD%A2%E5%9C%96
数据点在直角坐标系平面上的分布图。
散点图表示因变量随自变量而变化的大致趋势,据此可以选择合适的函数对数据点进行拟合。 用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式。散点图将序列显示为一组点。值由点在图表中的位置表示。类别由图表中的不同标记表示。散点图通常用于比较跨类别的聚合数据。
百度百科
http://baike.baidu.com/item/%E6%95%A3%E7%82%B9%E5%9B%BE
知乎
https://www.zhihu.com/question/23236070
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















