















































软件

产品


谱聚类就是基于图论的聚类方法,通过对样本数据的拉普拉斯矩阵的特征向量进行聚类,从而达到对样本数据进行聚类的目的。 https://zhuanlan.zhihu.com/p/29941760【简单理解】
首先介绍两个基本概念:
谱聚类把待聚类的数据集中的每一个样本看做是图中一个顶点,这些顶点连接在一起,连接的这些边上有 权重 ,权重的大小表示这些样本之间的相似程度。同一类的顶点它们的相似程度很高,在图论中体现为同一类的顶点中连接它们的边的权重很大,不在同一类的顶点连接它们的边的权重很小。于是谱聚类的最终目标就是找到一种切割图的方法,使得切割之后的各个子图内的权重很大,子图之间的权重很小。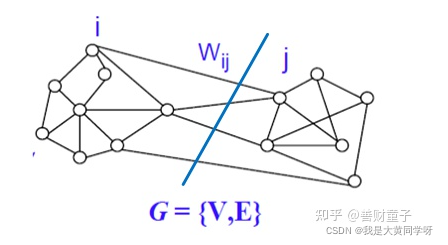
一种经典的谱聚类算法如下所示,首先计算给定数据集中的相似度矩阵 W W W,这里有很多种方式可以计算,比如K近邻、全连接法【可见参考资料2】,其主要目的是衡量数据点之间的相似度;根据相似度矩阵 W W W构造图拉普拉斯矩阵 L L L(这里需要利用W进一步构造度矩阵和 邻接矩阵 ,才能得到图拉普拉斯矩阵);计算图拉普拉斯矩阵的特征值,获取前k个最小特征值对应的特征向量 Z ∈ R n × k Z∈R^{n\times k} Z∈Rn×k;将 Z Z Z中每一行视为一个数据点,进行K-Mean聚类,最后聚类的结果就对应于 原始数据 的聚类结果。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















