















































软件

产品


\qquad 首先从逻辑回归的成本函数入手说起: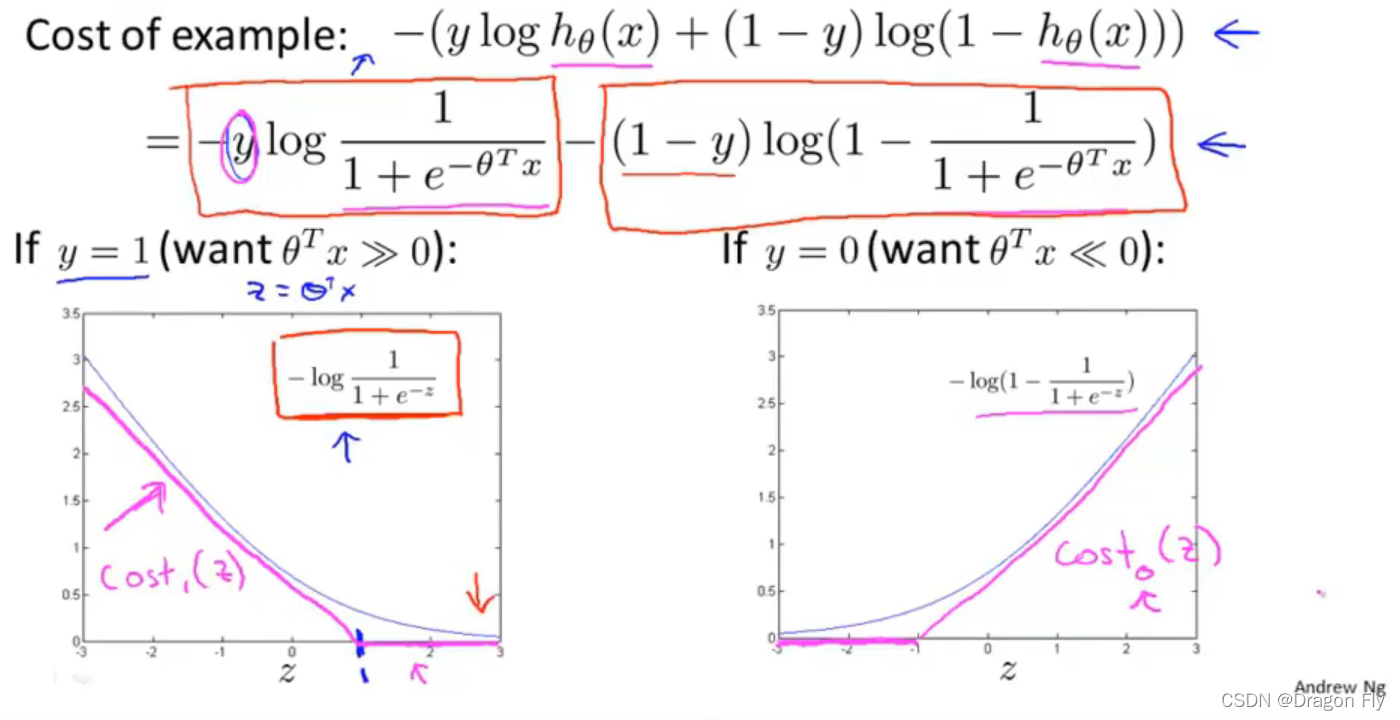
\qquad 使用一个线性近似 c o s t 1 ( z ) cost_1(z) cost1(z)来近似表示逻辑回归中成本函数的第一项;使用线性近似 c o s t 0 ( z ) cost_0(z) cost0(z)来近似表示逻辑回归成本函数中的第二项。
\qquad 之后在SVM中,将成本函数中的常数项 1 / m 1/m 1/m去掉,并用参数C来替代归一化参数 λ \lambda λ: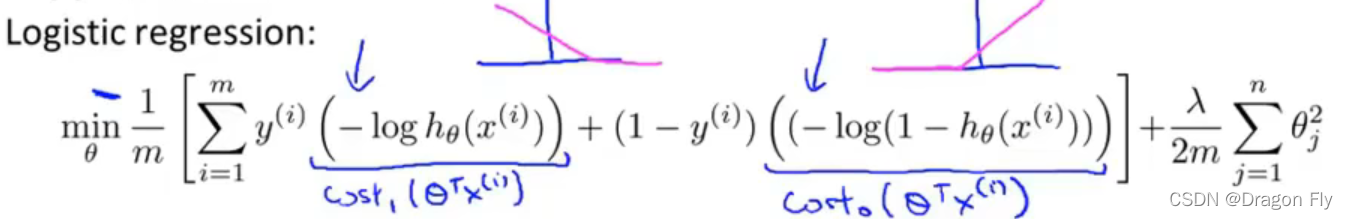
\qquad SVM成本函数估计的最终方式如下所示: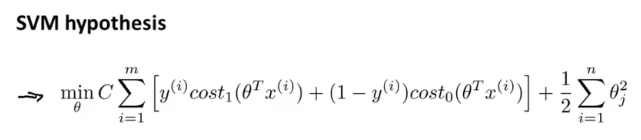
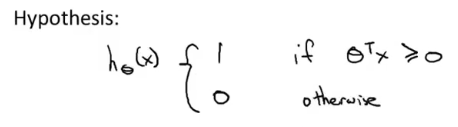
\qquad 当使用SVM作为分类成本函数时,最终获得的分类 边界 距离各个样本点的距离会比较大,从而可以得到一个较大的分类间距(margin),使得分类器的鲁棒性更高。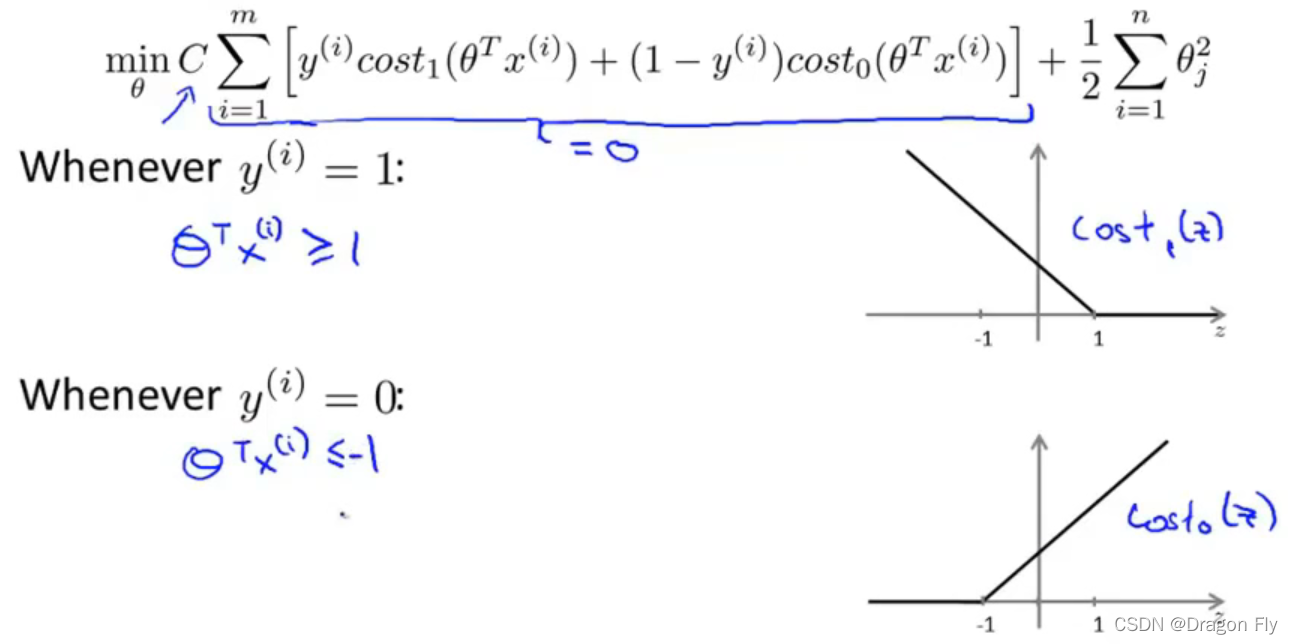
\qquad 若将上述成本函数中的系数C设置为一个极大的数字(如10000),所以上述最小化成本函数可以通过求解下述约束优化问题得到: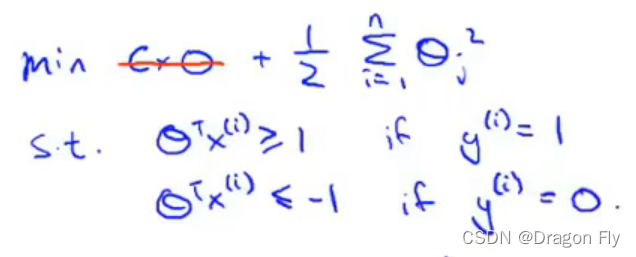
\qquad 最终得到的分类边界如下图黑色分类边界所示: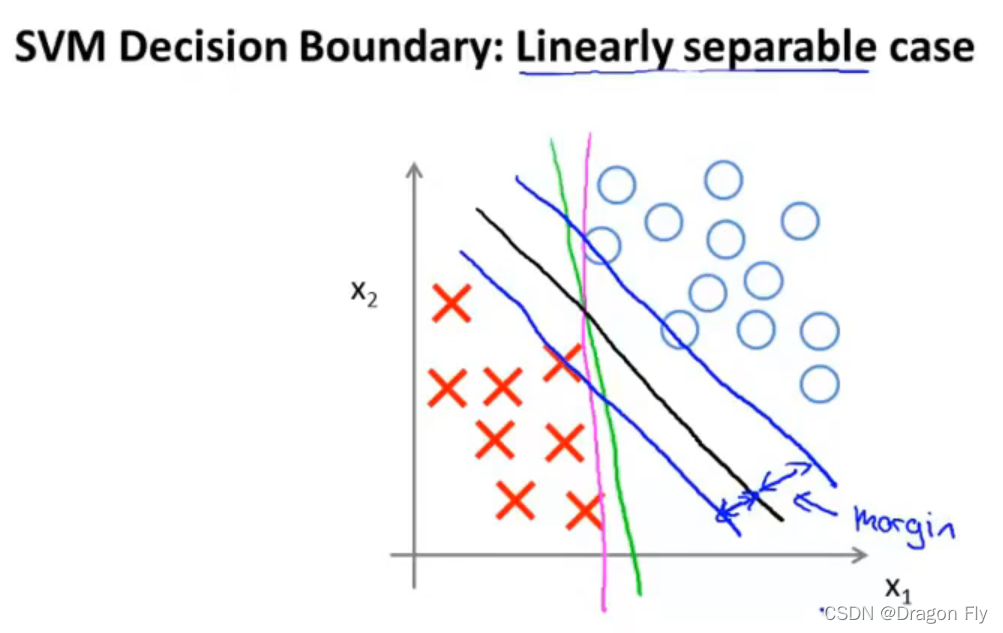
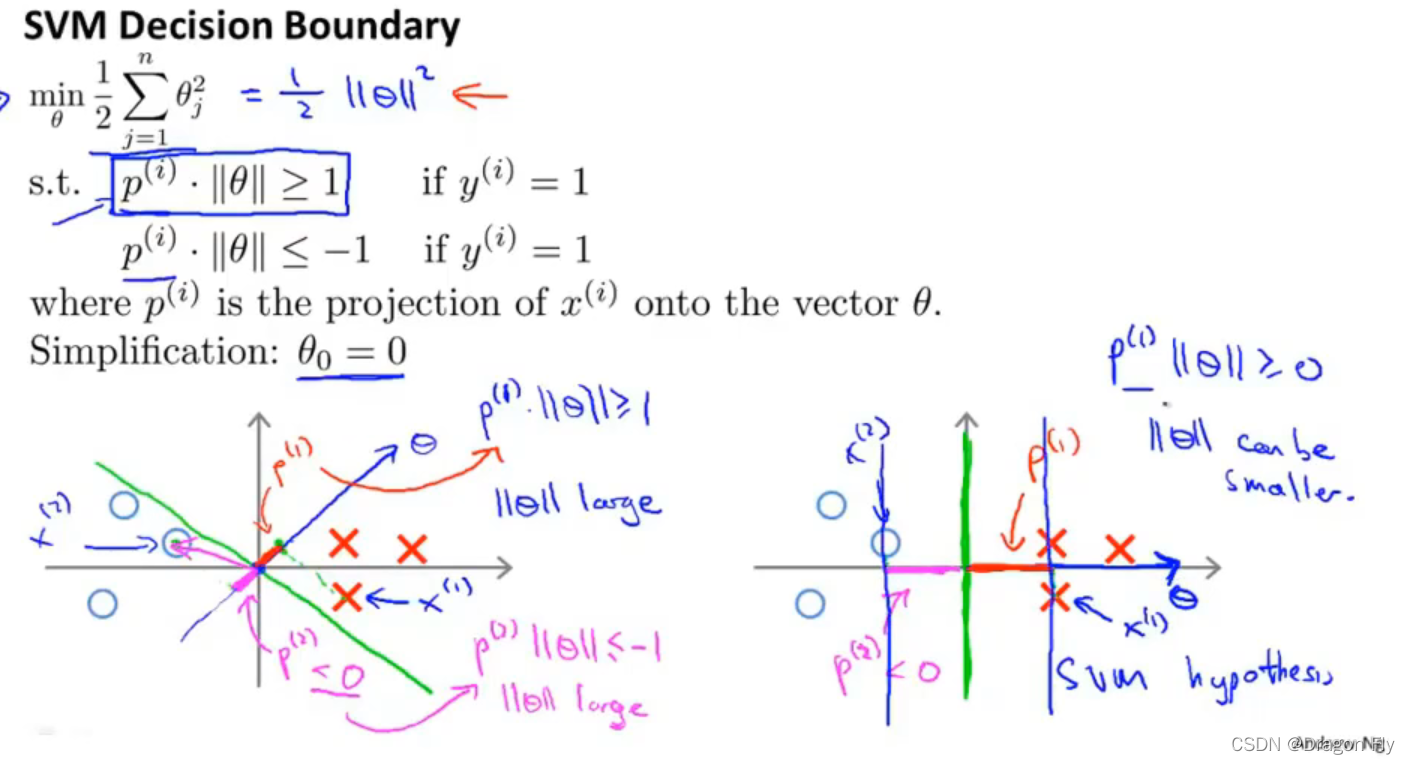
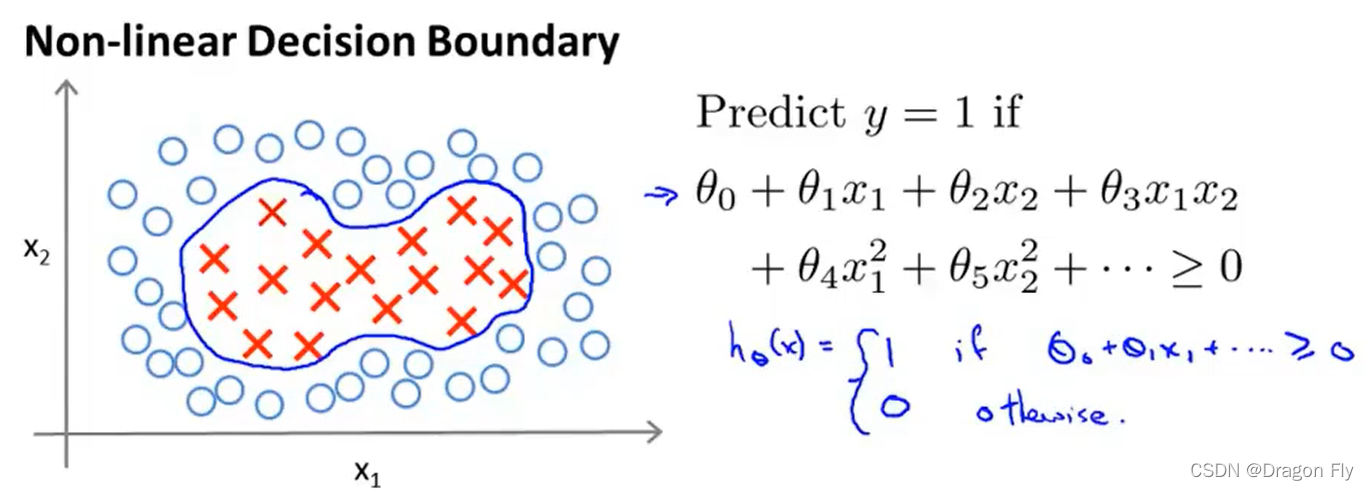
\qquad 如上图所示,当使用非线性决策边界进行分类时,通常需要将假设函数取较高的幂,但是假设函数中特征取值方法很难确定。所以可以使用核函数方法,通过取“landmark”的方式,根据新特征跟“landmark”之间的相似程度来确定新的特征,每一个确定下来的“landmark”都代表一个新的特征。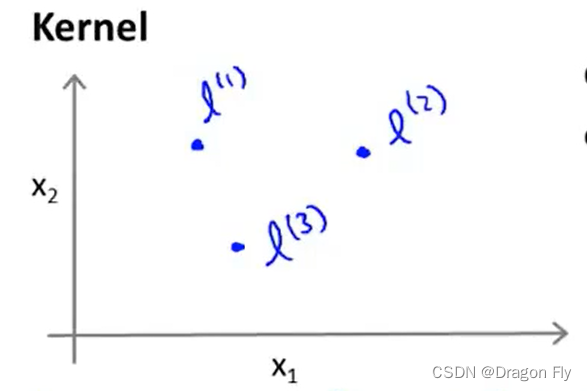
\qquad "landmark"和某个样本( x 1 , x 2 x_1,x_2 x1,x2)之间的相似度(高斯核函数)的计算方法如下所示: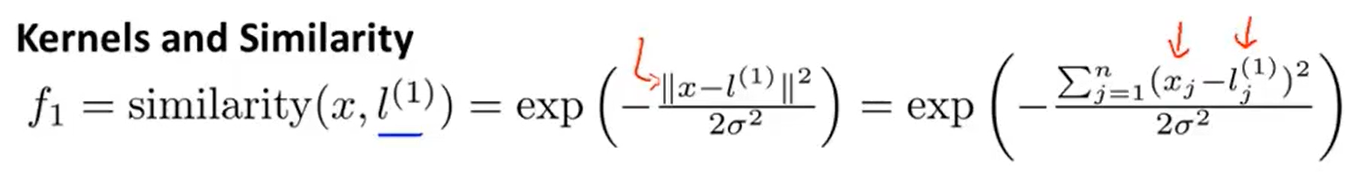
\qquad 当样本和“landmark”之前距离很近时,则 f 1 f_1 f1的取值约等于0,说明取到的样本和“landmark”之间相似度很高;当样本和“landmark”之间的距离很远时,则 f 1 f_1 f1的取值约等于0,说明取到的样本和“landmark”之间的相似度很低。
\qquad 核函数和相似度 公式 中的x和 σ \sigma σ之间的关系如下图所示: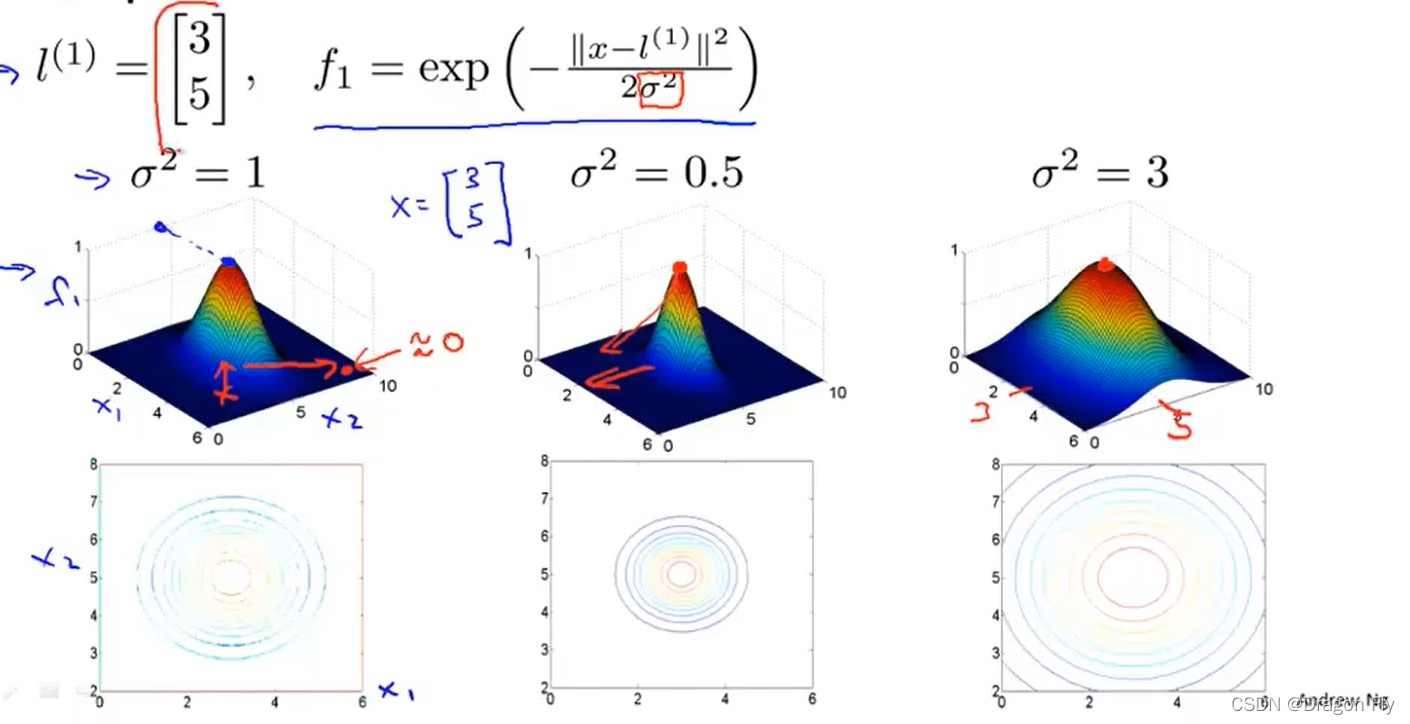
\qquad 当确定了“landmark”的位置和 σ \sigma σ的取值之后,便可以使用 f 1 , f 2 , f 3 f_1,f_2,f_3 f1,f2,f3作为新的特征来定义假设函数:
\qquad 在使用SVM时,“landmark”的数量即为选取的训练数据集中样本的数量,即 训练 数据中每一个样本点都代表一个“landmark”,即对应一个特征。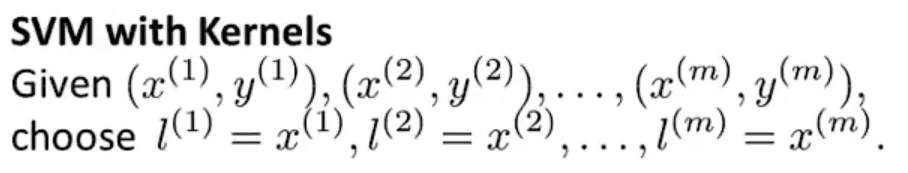
\qquad SVM 模型 过拟合合欠拟合与参数取值的关系:
\qquad 根据特征数量和训练样本数量的多少,选择使用逻辑回归或者SVM的细节如下所示:
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















