















































软件

产品


在使用Python提取ABAQUS后处理odb文件中的数据时,发现关于ABAQUS中具体的应力提取方式,缺少详细的总结和说明。因此在这里对于自己曾经使用过的ABAQUA二次开发相关函数做总结,之后遇到二次开发相关的问题也会补充在这篇文章里。
值得注意的一点是,所有有关ABAQUS二次开发的方法函数总结,都可以通过在ABAQUS软件中进行对应的操作,之后查看.rpy文件学习。 个人认为这是一种最为快速便捷的方法,比在博客中查询自己想要得到的结果函数要快的多。
在采用Python对ABAQUS结果提取之前,首先我们要了解ABAQUS odb文件结构,实际上,之后的python获取abaqus结果数据的方法,即为根据数据结构图依次调用其中的各个函数。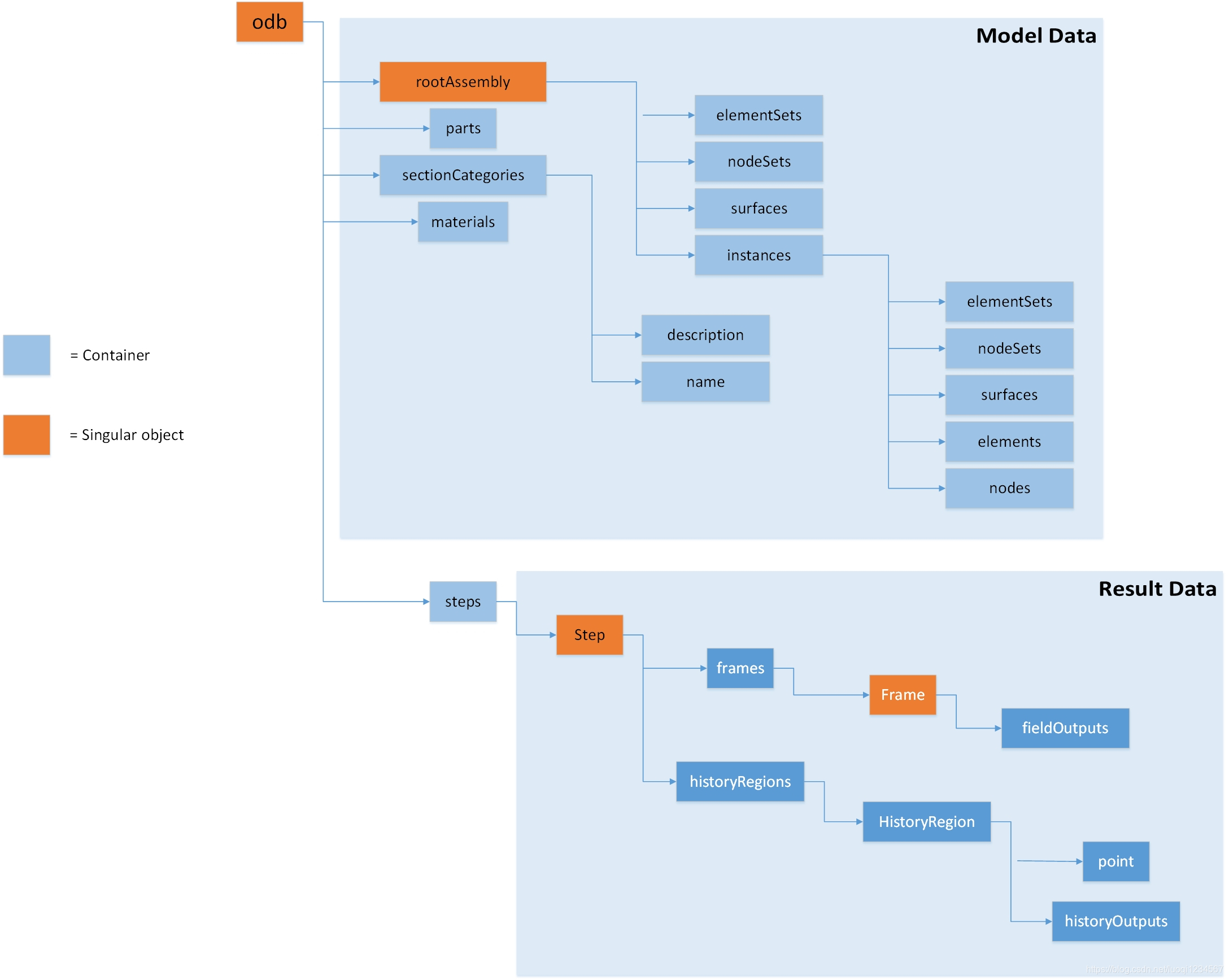
代码如下:
from odbAccess import*
from abaqusConstants import*
import sys
import os
实际上,提取数据的过程,应当直接使用abaqus的runscrip运行,而导入库直接使用abaqus运行时rpy文件中自动导入的库即可。
Python选择节点和单元的常用函数如下:
getByBoundingBox()
getByBoundingCylinder()
getByBoundingSphere()
通过位置选择节点:
p = mdb.models['Model-1'].parts['Part-1']
n = p.nodes
# 通过矩形框选节点,括弧里为矩形的两个坐标
nlist = n.getByBoundingBox(-100, 100, 0, 100, 100, 0)
# 创建set,Set-1即为我们所框选矩形内的节点集合
p.Set(nodes=nlist, name='Set-1')
通过位置选择单元:
与通过位置选择节点的方法类似,只需将nodes换成elements即可。
注:选中节点的单元都会被选中
p = mdb.models['Model-1'].parts['Part-1']
n = p.elements
elist = e.getByBoundingBox(-0.2, -12.6, -0.1, 0.2 ,12.6 ,0.1)
获取节点的label:
仅需在所希望获得label的节点后添加.label即可。这里以“[1]位置”节点的label获取为例。
p = mdb.models['Model-1'].parts['Part-1']
e = p.elements
elist = e.getByBoundingBox(-0.2, -12.6, -0.1, 0.2 ,12.6 ,0.1)
e1 = elist[1]
elabel1 = e1.label
ABAQUS的后处理结果中,fieldOutputs可提取参数如下(常用的也就是应力,应变,温度之类的):
S(应力)
MISEMAX(最大Mises应力)
E (应变)
TEMP(温度)
对于一些诸如Mises应力这种经过S(应力)处理后可以得到的数据,不能从odb文件中直接提取出来。
但是类似上述label的提取方式,可以先提取S(应力)之后利用.mises对应力做处理,具体的操作方式见下述程序:
# 这里直接使用exefile运行py文件获得odb结果,如果文件夹中已经有odb结果文件,则可省略这一步,直接提取结果文件
exefile('https://www.gofarlic.com/abaqus/temp/work_1.py', __main__.__dict__)
# 打开odb结果文件
jobname = 'Job-1'
odb = session.openOdb(name=jobname + '.odb')
# 提取应力,注意这里提取的stress是所有节点应力的集合,且每个节点包括六个应力(S11 S22 S33 S12 S13 S23)。
stress = odb.steps['Step-1'].frames[1].fieldOutputs['S'].values
# 提取某个节点(node_num = 2000)的Mises应力
node_num = 2000
stress_node = stress[node_num].mises
# 提取位移,同理,这里的位移也是所有节点位移集合
displacement = odb.steps['Step-1'].frames[1].fieldOutputs['U'].values
假设我们需要对某个模型改变某个条件(例如温度)运行iteration_num次,并且记录其每次模型的平均Mises应力结果及某个节点所对应的Mises应力结果,和循环所用时间,可写Python程序如下:
import numpy as np
import random
import time
time_start = time.time() # 记录循环所用时间
# 给定迭代次数及选取的节点编号
iteration_num = 100
node_num = 2000
# 抽取正态分布的温度
random.seed(1)
temp = 273.15 + np.random.normal(25, 2, iteration_num)
# 考虑到对所提取结果的后处理,建议将每次输出的结果,记录在txt或csv文件中,而不是用数组记录
pi01 = open("output_mean.txt", 'w')
pi02 = open("output_node.txt", 'w')
# 开始循环计算
for i in range(len(temp)):
T = temp[i]
execfile('https://www.gofarlic.com/abaqus/temp/Random_Model.py', __main__.__dict__)
# 提取odb结果文件
jobname = 'Job_norm_' + str(i)
odb = session.openOdb(name=jobname + '.odb')
stress = odb.steps['Step-1'].frames[1].fieldOutputs['S'].values
# 提取应力平均值(von mises)
stress_mean = Stress_mean(stress)
# 提取某一个节点的Von mises应力
stress_node = stress[node_num].mises
# 保存数据
save_data(stress_mean, stress_node)
pi01.close()
pi02.close()
time_end = time.time()
print('Time cost = %fs' % (time_end - time_start))
def Stress_mean(stress):
"""求平均应力"""
stress_add = 0.0
for t in range(len(stress)):
stress_add += stress[t].mises
stress_mean = stress_add / len(stress)
return stress_mean
def save_data(stress_mean, stress_node):
"""保存Vonmises应力数据"""
pi01.write("{}\n".format(str(stress_mean)))
pi02.write("{}\n".format(str(stress_node)))
注意对所提取结果做后处理应当考虑之前所保存文件的数据类型。这里的处理方法仅针对之前的数据存储方法。
将上述应力的结果提取出来,并绘制其分布直方图。
import numpy as np
import random
import matplotlib.pyplot as plt
po01 = open("output_mean.txt", 'r')
po02 = open("output_node.txt", 'r')
Output_Mean = np.array(po01.readlines())
Output_Node = np.array(po02.readlines())
plt.hist(Output_Mean, bins=10, color='steelblue', edgecolor='black')
plt.show()
plt.hist(Output_Node, bins=10, color='red', edgecolor='black')
plt.show()
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















