















































软件

产品


霍夫曼编译码的Matlab代码实现
注:不知道怎么回事,插入的图都没显示出来,还是推荐大家去CSDN学习和查看。
我也在CSDN发布了,网址为:https://blog.csdn.net/qq_40700822/article/details/104100028
霍夫曼编码的简介
哈夫曼编码(Huffman Coding),又称霍夫曼编码,是一种编码方式,哈夫曼编码是可变字长编码(VLC)的一种。Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫做Huffman编码(有时也称为霍夫曼编码)。
摘自百度百科: [链接](https://baike.baidu.com/item/%E5%93%88%E5%A4%AB%E6%9B%BC%E7%BC%96%E7%A0%81/1719730?fr=aladdin)
霍夫曼编码的原理
这里不再赘述,直接粘过来
赫夫曼树(Huffman Tree),又称最优二叉树,是一类带权路径长度最短的树。假设有n个权值{w1,w2,...,wn},如果构造一棵有n个叶子节点的二叉树,而这n个叶子节点的权值是{w1,w2,...,wn},则所构造出的带权路径长度最小的二叉树就被称为赫夫曼树。
这里补充下树的带权路径长度的概念。树的带权路径长度指树中所有叶子节点到根节点的路径长度与该叶子节点权值的乘积之和,如果在一棵二叉树中共有n个叶子节点,用Wi表示第i个叶子节点的权值,Li表示第i个也叶子节点到根节点的路径长度,则该二叉树的带权路径长度 WPL=W1*L1 + W2*L2 + ... Wn*Ln。
根据节点的个数以及权值的不同,赫夫曼树的形状也各不相同,赫夫曼树具有如下特性:
对于同一组权值,所能得到的赫夫曼树不一定是唯一的。
赫夫曼树的左右子树可以互换,因为这并不影响树的带权路径长度。
带权值的节点都是叶子节点,不带权值的节点都是某棵子二叉树的根节点。
权值越大的节点越靠近赫夫曼树的根节点,权值越小的节点越远离赫夫曼树的根节点。
赫夫曼树中只有叶子节点和度为2的节点,没有度为1的节点。
一棵有n个叶子节点的赫夫曼树共有2n-1个节点。
霍夫曼Tree的构建
赫夫曼树的构建步骤如下:
1、将给定的n个权值看做n棵只有根节点(无左右孩子)的二叉树,组成一个集合HT,每棵树的权值为该节点的权值。
2、从集合HT中选出2棵权值最小的二叉树,组成一棵新的二叉树,其权值为这2棵二叉树的权值之和。
3、将步骤2中选出的2棵二叉树从集合HT中删去,同时将步骤2中新得到的二叉树加入到集合HT中。
4、重复步骤2和步骤3,直到集合HT中只含一棵树,这棵树便是赫夫曼树。
参考自:[哈夫曼树及哈夫曼编码详解【完整版代码】](https://blog.csdn.net/wardseptember/article/details/80717653)
由右边的霍夫曼Tree得到左边的霍夫曼表: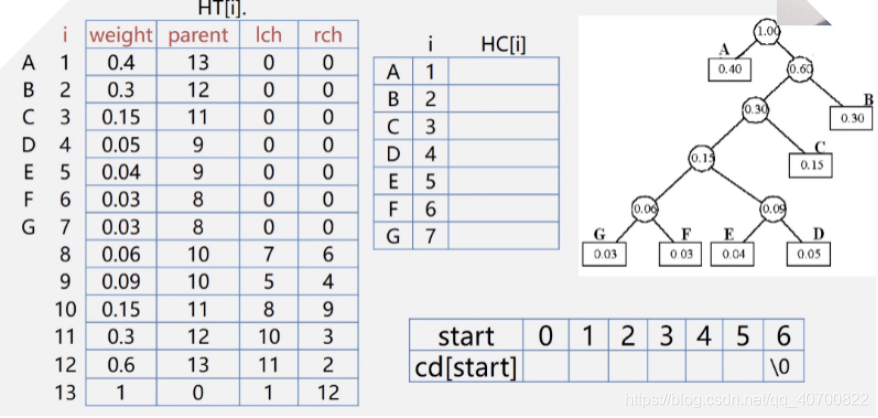
霍夫曼编码
由于霍夫曼Tree已经建立好了,接下来就进行霍夫曼编码,在由叶子结点到根节点的过程中,如果经过左子树,则编为0,如果经过右子树则变为1,编码所在的层数越小,编码的位次就越高,具体形式请参看:[哈夫曼树及哈夫曼编码详解【完整版代码】](https://blog.csdn.net/wardseptember/article/details/80717653)的Huffman编码部分。
# 霍夫曼编码Matlab代码实现
代码思路:
1、首先保存输入各权重的值,以数组的形式输入。
2、得到各个值的权重值之后,建立霍夫曼树 ,其实我建立的并不是霍夫曼Tree,而是上图中左边的霍夫曼表,其实霍夫曼表就是由霍夫曼Tree直接得到的,本质二者没有差别,只是表现的形式不同而已。
3、利用得到的霍夫曼Tree进行霍夫曼编码,首先我创建了与输入值的个数相等的空字符数组,用与进行霍夫曼编码,说白了就是为了存“0”和“1”。再从叶子结点到根节点的过程中,如果是左子树,则在该数组前面连接一个字符“0”,如果是右子树,则在该数组前面连接一个字符“1”,直到根节点为止,这样就得到了一个数的编码值。
4、计算平均码长。
5、计算信源熵。
6、计算编码效率。
直接上代码:
```
clear
p=input('输入信源概率分布:\n');
[~,n]=size(p);%得到编码个数
HT=zeros(2*n-1,4);%构造霍夫曼树
for i=1:n
HT(i,1)=p(i);
end
HT;%第一列为个数的权重值 1~4列分别为 权重 父节点 左孩子 右孩子
HT0=HT;
%构建霍夫曼树
for i=1:n-1
a=HT0(:,1);
[b,l]=sort(a,'descend');
s=b(n-i+1)+b(n-i);%选取两个最小值进行求和 大 小
HT0(n+i,1)=s;%将求和后的数放进霍夫曼树的父节点上
HT0(l(n-i+1),1)=0;%将两个最小值删除,清零
HT0(l(n-i),1)=0;%将两个最小值删除,清零
HT0(l(n-i+1),2)=n+i;%两个最小值的父节点
HT0(l(n-i),2)=n+i;%两个最小值的父节点
HT0(n+i,3)=l(n-i+1);%父节点的左孩子
HT0(n+i,4)=l(n-i);%父节点的右孩子
%重构霍夫曼树
HT(n+i,1)=s;
HT(l(n-i+1),2)=n+i;
HT(l(n-i),2)=n+i;
HT(n+i,3)=l(n-i+1);
HT(n+i,4)=l(n-i);
end
HT;%去掉分号可查看霍夫曼树
%字符数组,用于生成霍夫曼码
a={;};
for i=1:n
a{1,i}=' ';
end
%霍夫曼编码
for i=1:n
f=i;
while(HT(f,2)~=0)%直到父节点为根结点时,编码完成
q=HT(f,2);%取出叶子结点的父节点的值
if HT(q,3)==f
a{i}=strcat('0',a{i});%若为左孩子,则编为0
else
a{i}=strcat('1',a{i});%若为右孩子,则编为1
end
f=q;%继续寻找父节点的节点
end
end
fprintf('各分布概率的霍夫曼编码为:\n');
for i=1:n
fprintf( '%f的编码为:"%s"\n' ,HT(i,1),a{i});
end
%计算平均码长
l=[];
L_1=0;
for i=1:n
l(i)=length(a{i});
L_1=l(i)*HT(i,1)+L_1;
end
fprintf('平均码长为:%f \n',L_1);
%计算信源熵
Hx=0;
for i=1:n
Hx=-HT(i,1).*log2(HT(i,1))+Hx;
end
fprintf('信源熵为:%f \n',Hx);
%计算编码效率
M=Hx/L_1;
fprintf('编码效率为:%f \n',M);
```
为了更好地理解我就拿刚才的那个图举个例子:

脚本文件运行之后:
首先输入:(注意,此代码在输入权重时,必须用方括号阔起来)
```
输入信源概率分布:
[0.4 0.3 0.15 0.05 0.04 0.03 0.03]
```
如果运行没有问题的话,结果应该为:
```
各分布概率的霍夫曼编码为:
0.400000的编码为:"0"
0.300000的编码为:"11"
0.150000的编码为:"101"
0.050000的编码为:"10011"
0.040000的编码为:"10010"
0.030000的编码为:"10001"
0.030000的编码为:"10000"
平均码长为:2.200000
信源熵为:2.165790
编码效率为:0.984450
```
霍夫曼译码

代码思路:
1、首先输入各个值的权重值,并保存。
2、构建霍夫曼Tree。
3、每次输入一个值的编码值,得到该编码的权重值。
上代码:
```
clear
p=input('输入信源概率分布:\n');
[~,n]=size(p);%得到编码个数
HT=zeros(2*n-1,4);%构造霍夫曼树
for i=1:n
HT(i,1)=p(i);
end
HT;%第一列为个数的权重值 1~4列分别为 权重 父节点 左孩子 右孩子
HT0=HT;
%构建霍夫曼树
for i=1:n-1
a=HT0(:,1);
[b,l]=sort(a,'descend');
s=b(n-i+1)+b(n-i);%选取两个最小值进行求和 大 小
HT0(n+i,1)=s;%将求和后的数放进霍夫曼树的父节点上
HT0(l(n-i+1),1)=0;%将两个最小值删除,清零
HT0(l(n-i),1)=0;%将两个最小值删除,清零
HT0(l(n-i+1),2)=n+i;%两个最小值的父节点
HT0(l(n-i),2)=n+i;%两个最小值的父节点
HT0(n+i,3)=l(n-i+1);%父节点的左孩子
HT0(n+i,4)=l(n-i);%父节点的右孩子
%重构霍夫曼树
HT(n+i,1)=s;
HT(l(n-i+1),2)=n+i;
HT(l(n-i),2)=n+i;
HT(n+i,3)=l(n-i+1);
HT(n+i,4)=l(n-i);
end
HT;
%霍夫曼解码
t=[];%存储二进制报文
t=input('输入二进制报文(注意输入各数之间用空格或者逗号隔开并用方括号阔起来,例:[1 0 1]):\n');%输入二进制报文
[~,v]=size(t);%得到二进制报文的长度
f=2*n-1;
i=1;
while(HT(f,3)||HT(f,4)||(i<=v))
if(t(i)==0)%从根节点出发,读入0则走向左孩子,读入1则走向右孩子
q=HT(f,3);%读入0则走向左孩子
f=q;
else
q=HT(f,4);%读入1则走向右孩子
f=q;
end
i=i+1;%读取下一个二进制报文
end
fprintf('输出对应的概率值为:\n');
disp(HT(f,1));%输出对应的概率值
```
还是那刚才的那个表举例:
脚本文件运行之后:
输入:
```
输入信源概率分布:
[0.4 0.3 0.15 0.05 0.04 0.03 0.03]
```
再次提示输入:
```
输入二进制报文(注意输入各数之间用空格或者逗号隔开并用方括号阔起来,例:[1 0 1]):
[1 0 0 0 0]
```
输出:
```
输出对应的概率值为:
0.0300
```
我又对霍夫曼编译码进行了整合:
代码如下:
```
p=input('输入信源概率分布:\n');
%function Huffman_coding_decoding(p)
[~,n]=size(p);%得到编码个数
HT=zeros(2*n-1,4);%构造霍夫曼树
for i=1:n
HT(i,1)=p(i);
end
HT;%第一列为个数的权重值 1~4列分别为 权重 父节点 左孩子 右孩子
HT0=HT;
%构建霍夫曼树
for i=1:n-1
a=HT0(:,1);
[b,l]=sort(a,'descend');
s=b(n-i+1)+b(n-i);%选取两个最小值进行求和 大 小
HT0(n+i,1)=s;%将求和后的数放进霍夫曼树的父节点上
HT0(l(n-i+1),1)=0;%将两个最小值删除,清零
HT0(l(n-i),1)=0;%将两个最小值删除,清零
HT0(l(n-i+1),2)=n+i;%两个最小值的父节点
HT0(l(n-i),2)=n+i;%两个最小值的父节点
HT0(n+i,3)=l(n-i+1);%父节点的左孩子
HT0(n+i,4)=l(n-i);%父节点的右孩子
%重构霍夫曼树
HT(n+i,1)=s;
HT(l(n-i+1),2)=n+i;
HT(l(n-i),2)=n+i;
HT(n+i,3)=l(n-i+1);
HT(n+i,4)=l(n-i);
end
HT;
while(1)
y=input('请选择需要的进行的操作:\n 1.编码\n 2.解码\n 3.退出\n');
if y==1
Huffman_coding(p);
end
if y==2
huffman_decoding(p);
end
if y==3
break;
end
end
```
把编码和译码分成了两个不同函数进行调用:
脚本文件运行成功后:
```
输入信源概率分布:
[0.4 0.3 0.15 0.05 0.04 0.03 0.03]
请选择需要的进行的操作:
1.编码
2.解码
3.退出
```
# 注意!!!霍夫曼编译码是建立在同一个霍夫曼Tree下的。
如有不足请多指教。
如果原理看不明白,建议去B站看 [青岛大学--王卓](https://www.bilibili.com/read/cv3285768)有关霍夫曼编码的视频讲解,老师是用C实现的霍夫曼编译码,原理懂了,什么语言实现都无所谓。让我们一起加油吧。
我也在CSDN发布了,网址为:https://blog.csdn.net/qq_40700822/article/details/104100028
2020.1.28 by iNBC from SDUT
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















