















































软件

产品


前三篇博客已经介绍了,如何利用selenium去爬取一个指定内容的百度文库的文章链接和文章的名称,接下这篇博客主要介绍的是,针对于一篇文章我们应该如何去爬取所有的内容
1、分析文章的页面结构,文章地址 https://wenku.baidu.com/view/1d03027280eb6294dd886cb7.html?from=search
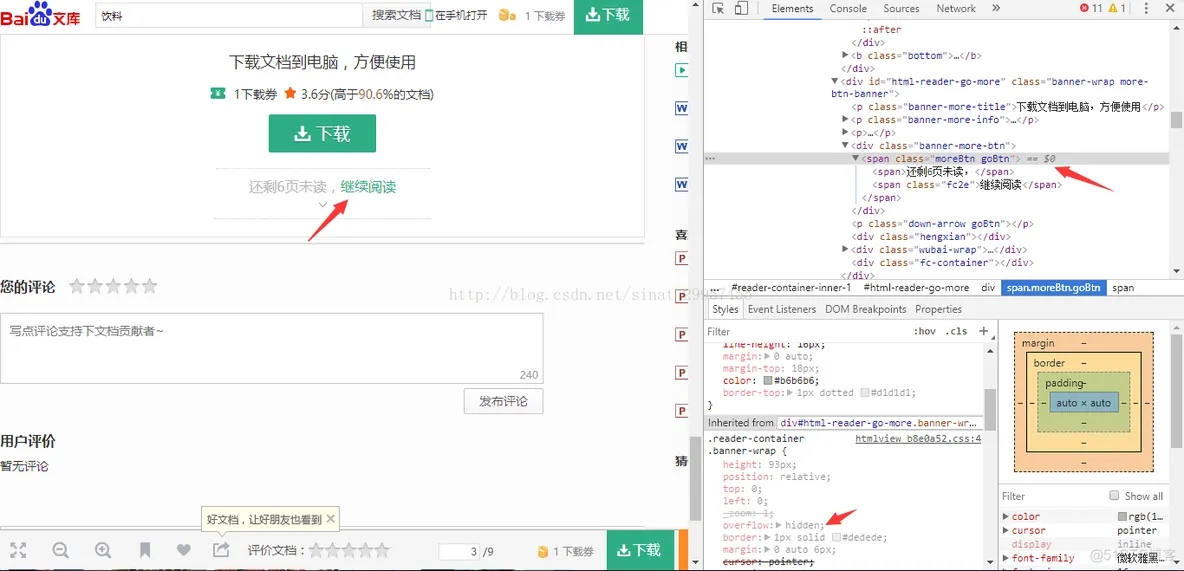
通过上图我们可以观察到,打开文章链接之后,可能有的文章显示不全需要点击“继续阅读”按钮之后,才能看到所有的内容。
运行之后,你会发现,在pycharm的控制台报错,selenium.common.exceptions.WebDriverException: Message: unknown error: Element <span class="moreBtn goBtn">...</span> is not clickable at point (449, 565). Other element would receive the click: <div class="content" id="reader-evaluate-content-wrap" data-id="1d03027280eb6294dd886cb7" data-value="-1" data-doc-value="0">...</div>,这个错误的意思是不能去点击这个标签,它可以去点击这个div。为什么会这样呢?细心的朋友可能会看见上图的右下角有一个箭头,仔细看有一句style属性是,overflow:hidden这句话的意思是隐藏这个标签,所以才导致这个错误的发生。selenium的python api链接
http://selenium-python.readthedocs.io/api.html,解决办法如下,
在点击继续阅读按钮之前,最好先判断这个按钮是否存在,如果只有1页的时候,是不会有这个按钮的,判断方法,可以用之前的方法进行判断。获取文章的所有内容
注意:有可能会因为百度文库的广告导致将继续阅读按钮遮住,致使点击的时候,点击不到继续阅读按钮,所以,你需要找到广告的位置(需要先判断广告是否存在,再做处理,否则可能会报错),然后,使用让隐藏按钮可以点击的方法处理广告即可。
输出结果:
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















