















































软件

产品


LASSO是由1996年Robert Tibshirani首次提出,全称Least absolute shrinkage and selection operator。该方法是一种压缩估计。它通过构造一个惩罚函数得到一个较为精炼的模型,使得它压缩一些回归系数,即强制系数绝对值之和小于某个固定值;同时设定一些回归系数为零。因此保留了子集收缩的优点,是一种处理具有复共线性数据的有偏估计。
除了岭回归之外,最常被人们提到就是模型 Lasso。和岭回归一样,Lasso来作用于多重共线性问题的算法,不过 Lasso使用的是系数w的L1范式(L1范式则是系数w的绝对值)乘以系数α,所以 Lasso的损失函数表达式为: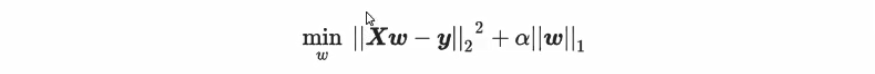
返回顶部
一般来说, Lasso与岭回归非常相似,都是利用正则项来对原本的损失函数形成一个惩罚,以此来防止多重共线性。但是其实这种说法不是非常严谨,我们来看看 Lasso的数学过程。当我们使用最小二乘法来求解 Lasso中的参数w,我们依然对损失函数进行求导:


所有这些让 Lasso成为了一个神奇的算法,尽管它是为了限制多重共线性被创造出来的,然而大部分地方并不使用它来抑制多重共线性,反而接受了它在其他方面的优势。在逻辑回归中涉及到,L1和L2正则化一个核心差异就是他们对系数w的影响:两个正则化都会压缩系数w的大小,对标签贡献更少的特征的系数会更小,也会更容易被压缩。不过,L2正则化只会将系数压缩到尽量接近0,但L1正则化主导稀疏性,因此会将系数压缩到0。这个性质,让 Lasso成为了线性模型中的特征选择工具首选,接下来,我们就来看看如何使用 Lasso来选择特征。
class sklearn.linear_model.Lasso(alpha=1.0, *, fit_intercept=True, normalize=False, precompute=False,
copy_X=True, max_iter=1000, tol=0.0001, warm_start=False,
positive=False, random_state=None, selection='cyclic')[source]
sklearn中我们使用Lasso类来调用lasso回归,众多参数中我们需要比较在意的就是参数α,正则化系数。要注意的就是参数 positive.当这个参数为True的时候,我们要求 Lasso回归处的系数必须为正数,以此证我们的α一定以增大来控制正则化的程度。
在skLearn中的Lasso使用的损失函数是:
# -*- coding: utf-8
# @Time : 2021/1/15 15:14
# @Author : ZYX
# @File : Example6_Lasso.py
# @software: PyCharm
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.linear_model import Lasso,Ridge,LinearRegression
from sklearn.model_selection import train_test_split,cross_val_score
from sklearn.datasets import
 做人呢,最重要的是开心!
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
做人呢,最重要的是开心!
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















